2.1 CAP 定理的由来与证明
CAP 定理是计算机科学界的“铁律”,最早由 Eric Brewer 提出,后来被正式证明:
分布式系统里,一致性(C)、可用性(A)、分区容错性(P),三选二 。

说白了就是:你想当个“全能选手”,但生理极限摆在那儿。
CAP 定理不是吓唬人,而是告诉你:
在网络抖动、节点挂掉的情况下,你必须选择牺牲一致性或可用性。
2.2 CAP 定理的三要素
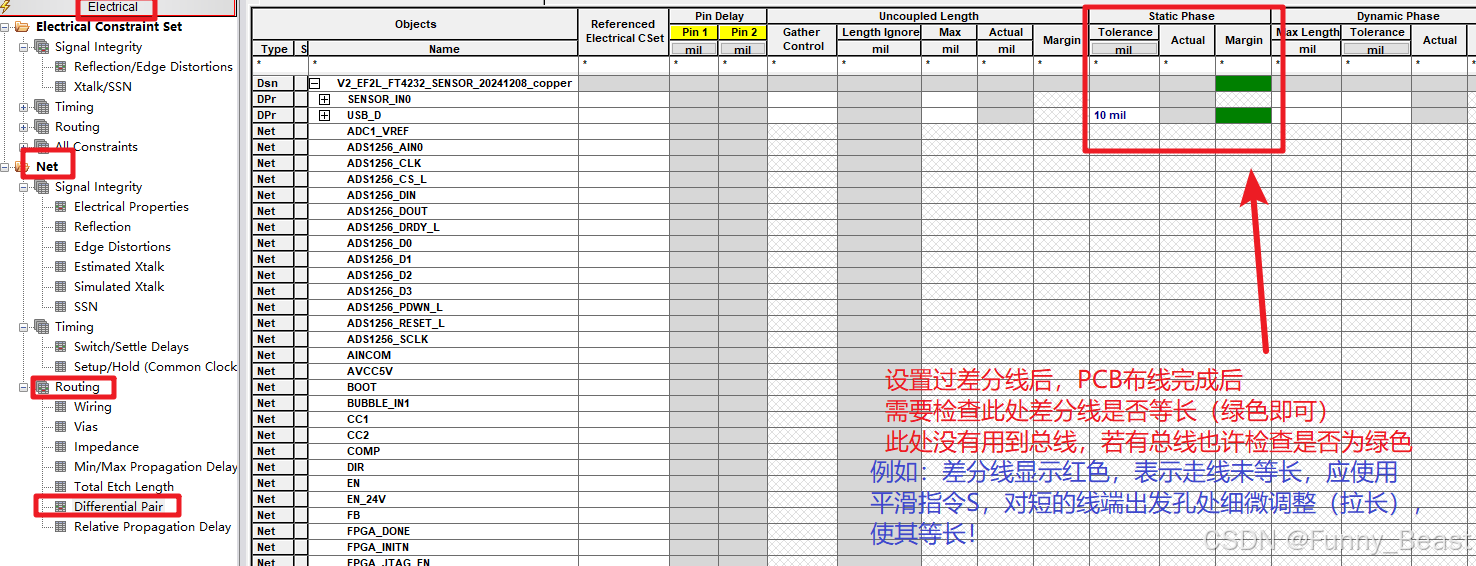
一致性(Consistency,C):所有节点看到的数据必须是一样的。就像银行转账,一秒差错都可能让用户报警。但强一致性有个代价——效率低,用户得等。
可用性(Availability,A):系统能随时响应请求,哪怕返回的是不太准确的数据。比如双十一,你下单秒杀个商品,能买到就开心了,至于库存可能会稍微滞后。
分区容错性(Partition Tolerance,P):网络出问题时,系统还能继续提供服务。毕竟分布式系统里,网络断连是常态,你不可能让它一断网就宕机。
三者冲突的现实:
如果你既想数据毫无误差,又想系统随时响应,还想网络断了照样能跑,那结果只有一个:
系统超载爆炸。分布式系统的难题就在于此。
- CAP 定理的实践意义:强一致性和高并发的终极选择
3.1 CP(强一致性) VS AP(高并发)
CP(强一致性):
比如银行系统,转账时你宁可多等几秒钟,也不能让账户余额出错。
这时候,系统会优先保障一致性,即便某些节点挂掉,整个服务变慢,也得保证数据“账账相符”。
AP(高并发):
像电商秒杀,用户需要的是“能买到就行”,至于库存数据稍微延迟,事后对账能补回来。这种场景更倾向于高可用性,牺牲一致性。
总结一句话:CP 保证严谨,AP 注重速度,最终的选择得看业务场景。
- 分布式中间件中的 CAP 定理实现

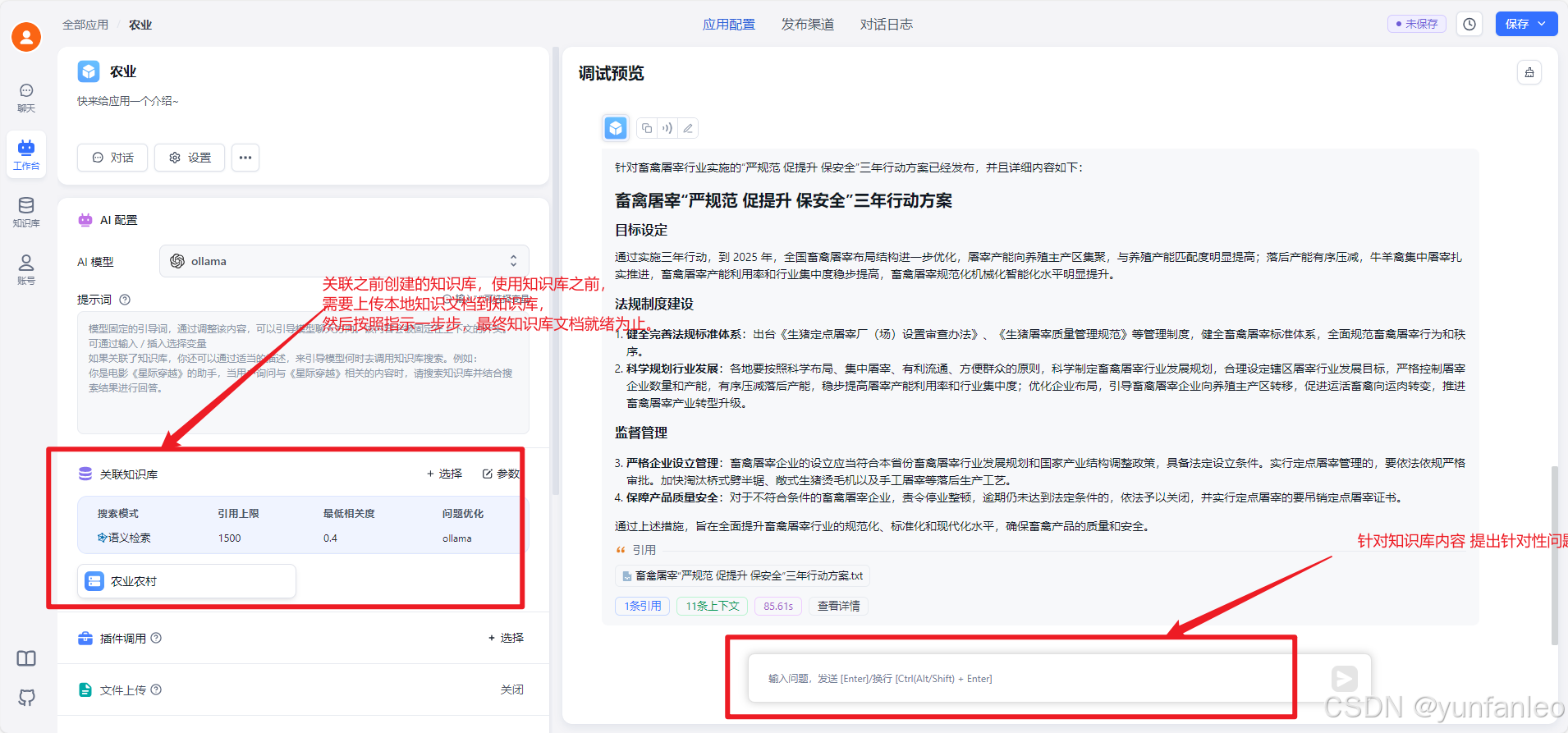
4.1 Redis Cluster 是 AP 型
分区容错性(P):Redis 的分片存储机制,让数据分布在多个节点上,某些节点挂了系统也不会死。
可用性(A):主从复制机制,切换节点几乎无感知。
一致性(C):但主从同步可能有延迟,数据不一定完全一致。
总结:Redis 不追求强一致性,它的目标是:快!快!快!
4.2 Zookeeper 是 CP 型
分区容错性(P):网络断连时,Zookeeper 保证“少数服从多数”,继续维护一致性。
一致性(C):ZAB 协议确保数据同步,适合分布式锁这种对一致性要求极高的场景。
可用性(A):但可用性差点意思,Leader 挂掉时会短暂不可用。
总结:Zookeeper 更适合用在需要“严防死守”的场景,比如分布式锁和服务注册。
4.3 MongoDB 属于 CP 型
MongoDB 的选主机制更关注一致性,而不是在网络分区时优先保持可用性。
适合:需要一致性的非关系型存储场景。
4.4 Cassandra 属于 AP 型
基于 Gossip 协议,Cassandra 牺牲一致性换来了超高的可用性和分区容错能力。
适合:大规模分布式写入,如日志和监控数据。
4.5 Eureka 属于 AP 型
作为微服务注册中心,Eureka 优先考虑高可用性。即使心跳超时,也会保持服务注册状态。
适合:高并发场景的服务发现。
4.6 Nacos 支持 AP + CP
Nacos 提供 AP 和 CP 模式切换:临时节点用 AP,永久节点用 CP。灵活应对各种场景。
总结一句话:分布式中间件的 CAP 策略就是“场景优先,问题靠边”。
- 总结:CAP 定理对架构设计的深远影响
CAP 定理不是魔咒,而是底层逻辑。
理解它的核心冲突,你才能在分布式系统里活得更明白。
技术选型时先看业务场景:银行选 CP,电商秒杀选 AP。
架构师的终极哲学:分布式系统里没有完美,只有最合适的权衡。
总结:CAP 定理教会我们的,是如何用有限的资源,撑起分布式系统的无限可能。
参考链接:https://blog.csdn.net/liuguojiang1128/article/details/144332961