文章目录
- SparkSQL与Hive的整合
- 1.1. Spark On Hive
- 1.1.1. Hive的准备工作
- 1.1.2. Spark的准备工作
- 1.1.3. Spark代码开发
- 1.1.4. Spark On Hive案例
- 1.2. Hive On Spark
- 1.3. SparkSQL命令行
- 1.4. SparkSQL分布式查询引擎
- 1.4.1. 开启ThriftServer服务
- 1.4.2. beeline连接ThriftServer
- 1.4.3. 代码连接
- 1.4.4. 任务查看
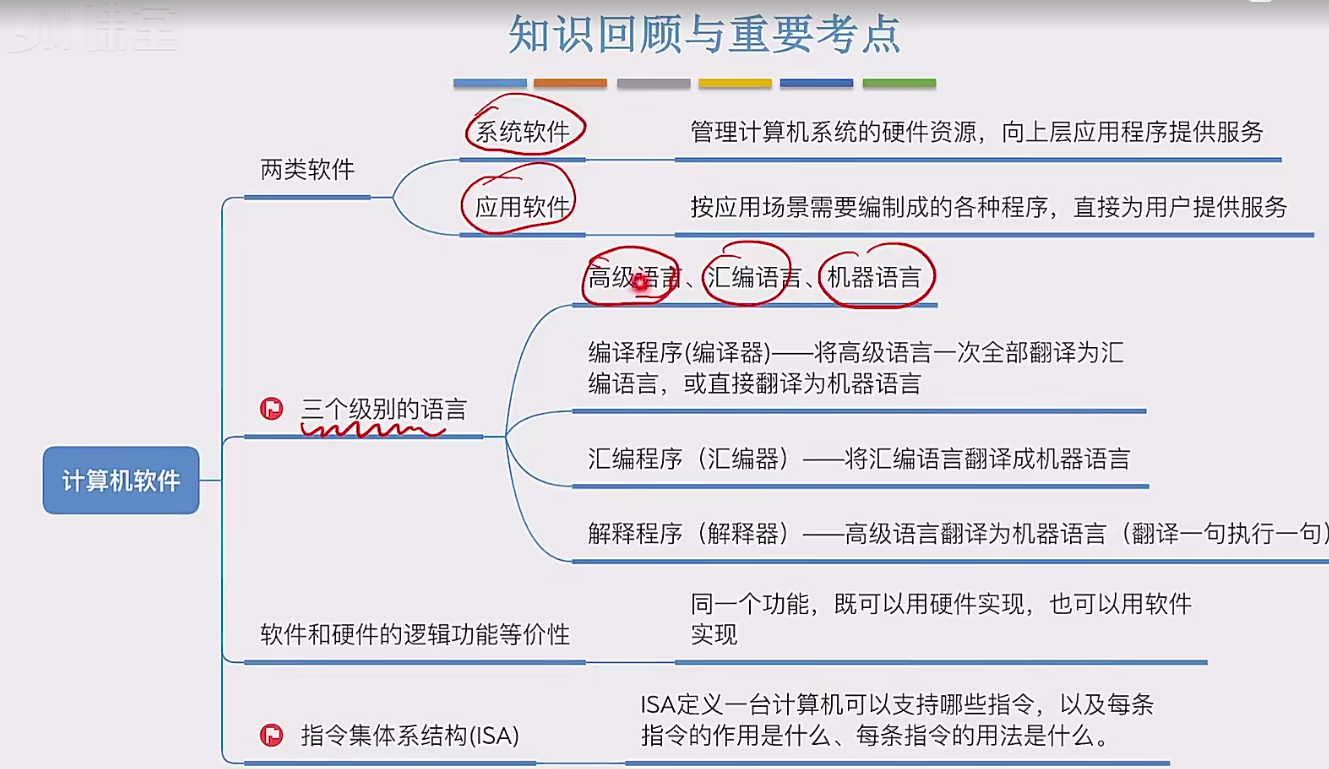
SparkSQL与Hive的整合
1.1. Spark On Hive
SparkSQL其实就是一个Spark框架下的执行引擎,可以对结构化的数据使用SQL的方式,将SQL翻译成为SparkCore的代码去完成计算。SparkSQL支持不同的数据源,可以读取各种数据文件的数据、可以通过JDBC读取MySQL的数据,在实际开发过程中,有时候我们需要使用SparkSQL去处理Hive中的数据。这就是SparkSQL与Hive的整合方式之一:Spark On Hive。
其实Spark只是一个计算引擎,本身是没有元数据管理的功能的。而我们在前面使用到的无论是DSL风格的处理方式,还是SQL风格的处理方式,所谓的“元数据”、“表”,其实都是向DataFrame注册的。DataFrame中记录了“表”、“字段”、“类型”等信息,就可以将SQL语句解析成为Spark程序来运行了。
但是Hive不同,Hive本身就是有一个元数据库(MetaStore)的,因此我们需要使用SparkSQL处理Hive的数据的时候,无需再注册表、注册字段等信息,直接从Hive的元数据库(MetaStore)中获取元数据即可。
1.1.1. Hive的准备工作
-
配置Hive的元数据服务:修改hive的配置文件
hive-site.xml<!-- 配置Hive的MetaStore服务,使用thrift协议,设置好主机名和端口号 --> <property><name>hive.metastore.uris</name><value>thrift://qianfeng01:9083</value> </property> -
启动Hive的元数据服务
# 开启Hive的metastore服务 # 这种方式开启的服务是一个前台进程,不方便使用 hive --service metastore# 开启Hive的metastore服务,并设置为后台进程 # 这种方式开启的元数据服务是后台进程,方便交互了,但是不方便查看日志,并且随着session的退出,服务会中断 hive --service metastore &# 启动后台进程,将日志输出到指定位置 nohup hive --service metastore > /var/log/metastore.log 2>&1 &
1.1.2. Spark的准备工作
-
在spark的conf目录下,创建hive-site.xml文件,存放连接到hive的配置信息
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.metastore.uris</name><value>thrift://qianfeng01:9083</value></property> </configuration>Spark程序在运行的时候,相关的配置信息的加载次序:
- 首先加载
conf目录下的配置文件。 - 再加载代码中进行的配置。
其实只需要让SparkSQL程序知道metastore服务在哪里就可以了,如果不配置上面的这个文件也可以,不过就需要在代码中配置了。为了避免每一次在写程序的时候,都在代码里面去配置,简单起见,就直接创建这个文件,将连接到Hive元数据服务的配置都放进去。这样每次Spark程序在启动的时候,都可以自动的加载到。
- 首先加载
-
准备MySQL的驱动包
因为Hive的元数据保存到了MySQL数据库,Spark SQL程序如果需要访问的话,肯定需要从MySQL数据库中读取元数据信息。此时就必须要这个jar包了。
将准备好的mysql-connector-java-8.0.26.jar文件存放到spark的jars目录下。
注意:
- 如果需要运行本地模式,那么本地的Spark的jars目录下需要存放有这个jar包。
- 如果需要运行集群模式,那么集群中的Spark的jars目录下需要存放有这个jar包。
1.1.3. Spark代码开发
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司from pyspark.sql import SparkSession# 这里的 .enableHiveSupport() 表示的就是打开Hive支持,此时就可以访问到Hive的数据了。
# 注意:
# 如果没有在spark的conf目录下面创建hive-site.xml并正确的设置hive的元数据服务
# 那么在创建SparkSession对象的时候,就必须要设置hive的元数据服务信息
# .config("spark.sql.warehouse.dir", "hdfs://qianfeng01:9820/user/hive/warehouse")
# .config("hive.metastore.uris", "thrift://qianfeng01:9083")
spark = SparkSession.builder\.master("local[*]")\.appName("hive-enable")\.enableHiveSupport()\.getOrCreate()# spark.sql("select * from mydb.emp").show()
spark.sql("select * from mydb.emp join mydb.dept on mydb.emp.deptno = mydb.dept.deptno;").show()spark.stop()
1.1.4. Spark On Hive案例
基本的Spark On Hive的程序就编写完成了。我们也可以结合之前的内容,整合其他的数据源与Hive配合使用
在Hive中有一张表,存储了用户的名字与身份证号。读取这个表中的数据,通过身份证号解析出生日、性别、年龄等信息,并将结果保存到Hive中。
"""
需求: 从 Hive 的mydb.users表中通过身份证号,解析出用户的生日、年龄、性别信息,并将结果存入到一个新的表中
res:usernameidcardphonebirthdayagegender
create table if not exists mydb.res(username string,idcard string,phone string,birthday string,age string,gender string
)
row format delimited
fields terminated by ','
"""import os
import re
import datetime
from pyspark.sql import SparkSession
from pyspark.sql.types import MapType, StringTypeos.environ.setdefault("HADOOP_USER_NAME", "root")def calculate_age(year, month, day) -> int:now = datetime.datetime.now()age = now.year - yearif now.month < month:age -= 1elif now.month == month and now.day < day:age -= 1return agedef parse_idcard(idcard: str) -> dict:# 1. 验证身份证号码是否合法m = re.fullmatch(r'(\d{6})'r'(?P<year>(19|20)\d{2})'r'(?P<month>0[1-9]|1[0-2])'r'(?P<day>[012][0-9]|10|20|30|31)'r'\d{2}'r'(?P<gender>\d)'r'[0-9xX]', idcard)if m is None:return {}# 2. 解析每一部分year = m.group('year')month = m.group('month')day = m.group('day')age = calculate_age(int(year), int(month), int(day))gender = '男' if int(m.group('gender')) % 2 != 0 else '女'birthday = '-'.join([year, month, day])return {"birthday": birthday, "age": age, "gender": gender}with SparkSession.builder.master("local[*]").appName("exercise").enableHiveSupport().getOrCreate() as spark:# 注册 UDF 函数spark.udf.register("parse_idcard", parse_idcard, MapType(StringType(), StringType()))# 查询数据res = spark.sql("""selectusername, idcard,phone,parse_idcard(idcard)['birthday'] as birthday,parse_idcard(idcard)['age'] as age,parse_idcard(idcard)['gender'] as genderfrom mydb.users""")# 将查询结果写出到 Hive 指定的表中,这个表需要提前存在res.write.insertInto("mydb.res")
1.2. Hive On Spark
其实Hive On Spark的意思就是,将Hive的底层计算引擎替换成Spark!Hive默认的计算引擎是MapReduce,而这个是可以替换的。只需要使用set hive.execution.engine=spark即可完成替换,同时需要指定Spark的Master。
# 使用Hive On Spark非常简单
# 只要用set hive.execution.engine命令设置Hive的执行引擎为spark即可
# 默认是mr
set hive.execution.engine=spark;
# 这里,是完全可以将其设置为Spark Master的URL地址的
set spark.master=spark://192.168.10.101:7077
# 注意上面这种配置是只适用于匹配的版本才可以,如果高版本的话现在是没有这种功能的,需要自行编译
# 参考官方文档:https://cwiki.apache.org//confluence/display/Hive/Hive+on+Spark:+Getting+Started
但是需要注意,HiveOnSpark并不是适合所有场景的,因为Spark是内存计算的计算引擎,需要消耗大量的内存资源,不利于其他程序的计算应用。因此需要使用Spark来处理Hive的数据的时候,SparkOnHive是一个比较常见的选择。
1.3. SparkSQL命令行
在Spark的bin目录下,有一个脚本文件spark-sql,这个脚本文件会启动一个命令交互界面,可以使得我们在命令行上直接使用Spark来操作Hive的数据。
在3.3.1.章节的部分,已经在spark的conf目录下面创建出来一个hive-site.xml文件,其中定义了hive的元数据相关的信息,这样我们就可以直接使用了。

1.4. SparkSQL分布式查询引擎
在Spark中有一个服务是ThriftServer服务,通过这个服务,用户可以通过JDBC连接ThriftServer来访问SparkSQL的数据。连接后可以直接通过编写SQL语句访问SparkSQL的数据。在配置ThriftServer的时候,至少需要配置ThriftServer的主机名和端口号,如果需要使用Hive的数据的话,还需要再提供Hive的Metastore的URIs。
如果你前面已经配置完成了Spark On Hive,那么在你的Spark的conf目录下已经存在了一个文件:hive-site.xml,在这个文件中已经配置好了Hive的Metastore的URIs了。
1.4.1. 开启ThriftServer服务
$SPARK_HOME/bin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000\
--hiveconf hive.server2.thrift.bind.host=qianfeng01\
--master local[*]
这里的
--master可以设置为local模式、Standalone模式或者YARN模式。
1.4.2. beeline连接ThriftServer
ThriftServer服务启动之后,默认件监听的是10000端口,我们可以使用一些客户端工具来连接到这个服务。例如beeline。

1.4.3. 代码连接
如果需要需要使用ThriftServer连接到SparkSQL,进而操作Hive的数据的话,我们需要安装Hive的依赖。
pip3 install pyhive
# @Author : 千锋大数据教研院
# @Company : 北京千锋互联科技有限公司from pyhive import hive# 通过Spark ThriftServer,创建到Hive的连接对象,
conn = hive.Connection(host="qianfeng01", port=10000, username="root", database="mydb")
# 创建一个光标对象,用来操作hive
cursor = conn.cursor()with conn, cursor:# 执行SQL语句cursor.execute("select * from emp join dept on emp.deptno = dept.deptno")result = cursor.fetchall()for r in result:print(r)
1.4.4. 任务查看
ThriftServer提交到Spark的任务,我们可以通过http://192.168.10.101:4040/jobs/来查看到。