目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《PostgreSQL数据库内核分析》
2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》
3、PostgreSQL数据库仓库链接,点击前往
4、日本著名PostgreSQL数据库专家 铃木启修 网站主页,点击前往
5、参考书籍:《PostgreSQL中文手册》
6、参考书籍:《PostgreSQL指南:内幕探索》,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
5、本文内容基于PostgreSQL 17.0源码开发而成
深入理解PostgreSQL数据库之在 libpq 中支持负载平衡
- 文章快速说明索引
- 功能使用背景说明
- 使用 psql 检查
- 使用 pgbench 检查
- 功能使用源码解析

文章快速说明索引
学习目标:
做数据库内核开发久了就会有一种 少年得志,年少轻狂 的错觉,然鹅细细一品觉得自己其实不算特别优秀 远远没有达到自己想要的。也许光鲜的表面掩盖了空洞的内在,每每想到于此,皆有夜半临渊如履薄冰之感。为了睡上几个踏实觉,即日起 暂缓其他基于PostgreSQL数据库的兼容功能开发,近段时间 将着重于学习分享Postgres的基础知识和实践内幕。
学习内容:(详见目录)
1、深入理解PostgreSQL数据库之在 libpq 中支持负载平衡
学习时间:
2024年12月12日 20:51:45
学习产出:
1、PostgreSQL数据库基础知识回顾 1个
2、CSDN 技术博客 1篇
3、PostgreSQL数据库内核深入学习
注:下面我们所有的学习环境是Centos8+PostgreSQL master+Oracle19C+MySQL8.0
postgres=# select version();version
------------------------------------------------------------------------------PostgreSQL 17.0 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 13.1.0, 64-bit
(1 row)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
BANNER_FULL Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production Version 19.17.0.0.0
BANNER_LEGACY Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
CON_ID 0#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.27 |
+-----------+
1 row in set (0.06 sec)mysql>
功能使用背景说明
在连接期间指定多个 PostgreSQL 实例的功能并不新鲜。您可以在连接字符串中的 host、hostaddr 和 port 参数下列出多个副本。客户端将尝试按指定的顺序连接到副本。
psql "host=replica1,replica2,replica3"
但是,如果连接数量很多,列表中的第一个副本将比其他副本承受更多的负载,而最后一个副本可能完全处于空闲状态。为了在副本之间均匀分配连接,您可以在形成连接字符串时在应用程序端对副本列表进行打乱。
或者您可以使用新的连接参数 load_balance_hosts,也就是我们今天要学习的重点 如下:
psql "host=replica1,replica2,replica3 load_balance_hosts=random"
其中load_balance_hosts=random 表示在尝试连接之前将对节点列表进行打乱。
load_balance_hosts 已添加到 PostgreSQL 客户端库 libpq 的连接字符串。它当前支持以下两个值:
| 值 | 说明 |
|---|---|
| disable | 主机之间没有负载平衡。主机按照提供的顺序进行尝试,地址按照从 DNS 或主机文件接收的顺序进行尝试 |
| random | 以随机顺序尝试主机或地址。此方法允许在多个 PostgreSQL 服务器之间实现连接负载平衡 |
注:其默认值为禁用。 PostgreSQL 15 之前的行为也与禁用相同。
提交记录如下:

提交信息,如下:
* Support connection load balancing in libpqThis adds support for load balancing connections with libpq using a
connection parameter: load_balance_hosts=<string>. When setting the
param to random, hosts and addresses will be connected to in random
order. This then results in load balancing across these addresses and
hosts when multiple clients or frequent connection setups are used.The randomization employed performs two levels of shuffling:1. The given hosts are randomly shuffled, before resolving themone-by-one.2. Once a host its addresses get resolved, the returned addressesare shuffled, before trying to connect to them one-by-one.Author: Jelte Fennema <postgres@jeltef.nl>
Reviewed-by: Aleksander Alekseev <aleksander@timescale.com>
Reviewed-by: Michael Banck <mbanck@gmx.net>
Reviewed-by: Andrey Borodin <amborodin86@gmail.com>
Discussion: https://postgr.es/m/PR3PR83MB04768E2FF04818EEB2179949F7A69@PR3PR83MB0476.EURPRD83.prod.outlook.
翻译一下,如下:
在 libpq 中支持连接负载平衡
- 这增加了使用连接参数
load_balance_hosts=<string>实现 libpq 负载平衡连接的支持。将参数设置为random时,主机和地址将以随机顺序连接。当使用多个客户端或频繁连接设置时,这会使得这些地址和主机之间的负载平衡- 所采用的随机化执行两个级别的改组:
- 给定的主机被随机改组,然后逐一解析它们
- 一旦主机的地址得到解析,返回的地址将被改组,然后尝试逐一连接它们。
该功能的价值在于:
- 将此功能添加到 libpq 意味着使用
libpq的客户端应用程序可以从中受益- 标准PostgreSQL包中提供的客户端应用程序使用libpq,因此 无需修改 客户端应用程序端的负载均衡功能即可使用负载均衡功能
- 尽管可能只有 psql 和 pgbench 是最有用的
接下来,我们看一下该功能的使用案例,如下:

使用 psql 检查
当使用 psql 连接时,通常会显式指定 --host、--port、--username 等选项,但实际上可以传递连接字符串作为数据库名称。以下是通过传递连接字符串作为数据库名称进行连接的示例:
[postgres@localhost:~/test/bin]$ ./psql 'port=5432 dbname=postgres host=localhost'
psql (17.0)
Type "help" for help.postgres=# \q
[postgres@localhost:~/test/bin]$ ./psql 'port=5433 dbname=postgres host=localhost'
psql (17.0)
Type "help" for help.postgres=# \q
[postgres@localhost:~/test/bin]$ ./psql 'port=5434 dbname=postgres host=localhost'
psql (17.0)
Type "help" for help.postgres=# \q
[postgres@localhost:~/test/bin]$
因此,新增加的负载均衡功能也可以作为连接字符串给出。(因此,即使 psql 端没有负载平衡选项,它也可以工作)
下面是随机连接到验证环境中显示的三个data并使用 SHOW 命令显示连接目的地的 PostgreSQL 参数端口的示例。要指定的连接字符串的内容如下:
| 关键词 | 值 | 说明 |
|---|---|---|
| host | localhost,localhost,localhost | 这次,所有三个节点都在同一机器上创建,因此为所有节点指定相同的 localhost |
| port | 5432,5433,5434 | 这次,三个节点设置为不同的端口。您需要匹配主机数量和逗号列表 |
| load_balance_hosts | random | 如果将其指定为随机,则负载将得到平衡 |
| dbname | postgres | 还可以指定数据库名称列表,但在这种情况下只能指定一个。 在这种情况下,无论连接到哪个端口,连接的数据库名称都是postgres |
测试如下:

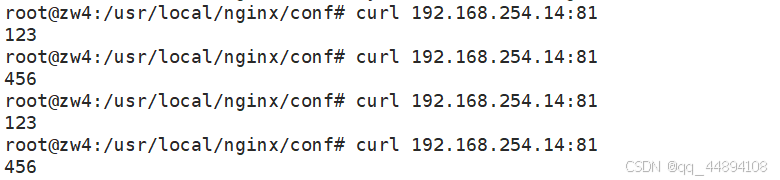
如上,通过连接到数据库集群并输出其端口号设置,可以看到连接目的地是随机选择的。
如果指定主机/端口上的数据库集群已停止,测试如下:
正常情况,如下:

我们这里把log_connections = on都设置上,如下:

异常情况,(停止使用 port=5433连接的数据库集群,并尝试使用与之前相同的连接字符串进行连接)如下:


在这种情况下,即使选择已停止的数据库集群也不会发生错误。这是因为当指定 load_balance_hosts=random 时,会以随机顺序尝试连接,而不是从列表中随机选择。例如,如果列表中有一个主机/端口已停止的数据库集群,并且首先选择它(如果立即发生连接错误),则将尝试使用下一个列表进行连接。
接下来,我们仅启动data1,进行调试:

开始,如下:

第一次尝试,如下:


再次尝试,如下:

同样此时conn->try_next_addr = true;,继续:

继续尝试,如下(这次端口号就是5432了):

注1:在我的调试中,有时候一次就成功,有时候则需要2次或3次。
注2:第三次尝试就成功了,虽然上面有errormessage,但是可以忽略不计,如下:

注:那么,敏锐的人可能已经注意到一个问题:在连接尝试时,如果无法在 TCP/IP 层连接,直到超时才会返回错误,这种情况下需要如何处理呢?因此,在指定 load_balance_hosts 时(此时可能会在 host 和 port 中指定多个主机和端口),最好将 connect_timeout 的设置也包含在连接字符串中。
使用 pgbench 检查
正如 psql 验证中所解释的,任何使用 libpq 的应用程序都可以从此 load_balance_hosts 中受益。由于 pgbench 也使用 libpq,那么是否可以在不使用另一个负载均衡器的情况下将处理分发到多个数据库服务器?
作为PostgreSQL的pgbench本身的一个选项,指定负载均衡和指定多主机的选项并没有显式的写出来,但是pgbench以和psql相同的方式指定数据库名称,所以连接字符的使用方式是不是也可以?
首先,使用pgbench的初始化模式初始化这三个端口的每个数据库集群(所有数据库名称均保持如上):

让我们为这三个数据库集群运行一个 pgbench 并随机分配处理。pgbench 的执行选项如下:
| 选项 | 值 | 说明 |
|---|---|---|
| -b | tpcb-like | 默认交易。一个条目也被插入到 pgbench_history 中 |
| -C | / | 每笔交易都会建立一个连接 |
| -c | 2 | 将同时连接数设置为2 |
| -t | 500 | 每个连接执行 500 个事务。这次,同时连接数 = 2,因此总共将执行 1000 个事务 |
| 数据库名称 | 'host=localhost,localhost,localhost port=5432,5433,5434 load_balance_hosts=random dbname=postgres' | 在此指定 load_balance_hosts |
让我们使用此设置运行 pgbench,如下:
[postgres@localhost:~/test/bin]$ ./pgbench -b tpcb-like -C -c 2 -t 500 'host=localhost,localhost,localhost port=5432,5433,5434 load_balance_hosts=random dbname=postgres'
pgbench (17.0)
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 2
number of threads: 1
maximum number of tries: 1
number of transactions per client: 500
number of transactions actually processed: 1000/1000
number of failed transactions: 0 (0.000%)
latency average = 7.383 ms
average connection time = 2.446 ms
tps = 270.897508 (including reconnection times)
[postgres@localhost:~/test/bin]$
虽然VACUUM是先执行的,但并不知道这个VACUUM是针对哪个数据库集群的postgres执行的。实际测量时,VACUUM本身必须为每个数据库集群单独执行,最好提前运行它并使用-n, --no-vacuum运行 pgbench 时。
-n, --no-vacuum do not run VACUUM before tests
现在 pgbench 已完成运行,让我们看看每个数据库集群的 pgbench_history 条目数,如下:
[postgres@localhost:~/test/bin]$ ./psql -t -p 5432 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"300[postgres@localhost:~/test/bin]$ ./psql -t -p 5433 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"341[postgres@localhost:~/test/bin]$ ./psql -t -p 5434 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"359[postgres@localhost:~/test/bin]$
清理一下,再来一遍(2 * 1000):
[postgres@localhost:~/test/bin]$ ./pgbench -p 5432 -i -s 10 --unlogged-table -q postgres
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 2.22 s (drop tables 0.01 s, create tables 0.00 s, client-side generate 1.24 s, vacuum 0.24 s, primary keys 0.72 s).
[postgres@localhost:~/test/bin]$ ./pgbench -p 5433 -i -s 10 --unlogged-table -q postgres
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 1.90 s (drop tables 0.01 s, create tables 0.00 s, client-side generate 1.21 s, vacuum 0.24 s, primary keys 0.43 s).
[postgres@localhost:~/test/bin]$ ./pgbench -p 5434 -i -s 10 --unlogged-table -q postgres
dropping old tables...
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 1.88 s (drop tables 0.02 s, create tables 0.00 s, client-side generate 1.20 s, vacuum 0.23 s, primary keys 0.44 s).
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./vacuumdb -p 5432 -d postgres
vacuumdb: vacuuming database "postgres"
[postgres@localhost:~/test/bin]$ ./vacuumdb -p 5433 -d postgres
vacuumdb: vacuuming database "postgres"
[postgres@localhost:~/test/bin]$ ./vacuumdb -p 5434 -d postgres
vacuumdb: vacuuming database "postgres"
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./psql -t -p 5432 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"0[postgres@localhost:~/test/bin]$ ./psql -t -p 5433 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"0[postgres@localhost:~/test/bin]$ ./psql -t -p 5434 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"0[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./pgbench -n -b tpcb-like -C -c 2 -t 1000 'host=localhost,localhost,localhost port=5432,5433,5434 load_balance_hosts=random dbname=postgres'
pgbench (17.0)
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 2
number of threads: 1
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 2000/2000
number of failed transactions: 0 (0.000%)
latency average = 7.924 ms
average connection time = 2.612 ms
tps = 252.392714 (including reconnection times)
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./psql -t -p 5432 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"662[postgres@localhost:~/test/bin]$ ./psql -t -p 5433 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"672[postgres@localhost:~/test/bin]$ ./psql -t -p 5434 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"666[postgres@localhost:~/test/bin]$
当然还可以 能者多劳,如下:
[postgres@localhost:~/test/bin]$ ./pgbench -n -b tpcb-like -C -c 2 -t 1000 'host=localhost,localhost,localhost,localhost port=5432,5433,5434,5433 load_balance_hosts=random dbname=postgres'
pgbench (17.0)
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10
query mode: simple
number of clients: 2
number of threads: 1
maximum number of tries: 1
number of transactions per client: 1000
number of transactions actually processed: 2000/2000
number of failed transactions: 0 (0.000%)
latency average = 7.319 ms
average connection time = 2.428 ms
tps = 273.276011 (including reconnection times)
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ./psql -t -p 5432 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"525[postgres@localhost:~/test/bin]$ ./psql -t -p 5433 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"981[postgres@localhost:~/test/bin]$ ./psql -t -p 5434 -d postgres -c "SELECT COUNT(*) FROM pgbench_history"494[postgres@localhost:~/test/bin]$
功能使用源码解析
官方手册解释,如下:
load_balance_hosts:控制客户端尝试连接到可用主机和地址的顺序。连接尝试成功后,将不再尝试其他主机和地址。此参数通常与多个主机名或返回多个 IP 的 DNS 记录结合使用。此参数可以与 target_session_attrs 结合使用,例如,仅在备用服务器上进行负载平衡。成功连接后,返回连接的后续查询将全部发送到同一服务器。目前有两种模式:
- disable(默认):不执行跨主机的负载平衡。主机按提供顺序尝试,地址按从 DNS 或主机文件接收的顺序尝试。
- random:主机和地址按随机顺序尝试。此值主要用于同时打开多个连接(可能来自不同的计算机)。这样,连接可以在多个 PostgreSQL 服务器之间进行负载平衡。虽然随机负载平衡由于其随机性,几乎永远不会导致完全均匀的分布,但从统计上看,它非常接近。这里的一个重要方面是,该算法使用两级随机选择(下面我们会详细解释):首先,主机将以随机顺序解析。其次,在解析下一个主机之前,将以随机顺序尝试当前主机的所有已解析地址。在某些情况下,这种行为可能会极大地扭曲每个节点获得的连接数量,例如当某些主机解析到比其他主机更多的地址时。但这种偏差也可以故意使用,例如通过在主机字符串中多次提供主机名来增加大型服务器获得的连接数量。使用此值时,建议还为 connect_timeout 配置一个合理的值。因为这样,如果用于负载平衡的节点之一没有响应,就会尝试一个新节点。
该功能的源码非常简单,下面重点看一下核心部分:
// src/interfaces/libpq/libpq-int.h/* Target server type (decoded value of load_balance_hosts) */
typedef enum
{LOAD_BALANCE_DISABLE = 0, /* Use the existing host order (default) */LOAD_BALANCE_RANDOM, /* Randomly shuffle the hosts */
} PGLoadBalanceType;
如上,两种选择 核心在于random,如下:
// src/interfaces/libpq/fe-connect.c/** pqConnectOptions2** Compute derived connection options after absorbing all user-supplied info.* 吸收所有用户提供的信息后计算派生的连接选项** Returns true if OK, false if trouble (in which case errorMessage is set* and so is conn->status).* 如果成功则返回 true,如果出现问题则返回 false(这种情况下会设置 errorMessage 并且 conn->status 也会设置)。*/
bool
pqConnectOptions2(PGconn *conn)
{...if (conn->load_balance_type == LOAD_BALANCE_RANDOM){libpq_prng_init(conn);/** This is the "inside-out" variant of the Fisher-Yates shuffle* algorithm. Notionally, we append each new value to the array and* then swap it with a randomly-chosen array element (possibly* including itself, else we fail to generate permutations with the* last integer last). The swap step can be optimized by combining it* with the insertion.* 这是 Fisher-Yates 洗牌算法的“由内而外”变体。* 理论上,我们将每个新值附加到数组中,然后将其与随机选择的数组元素交换(可能包括其自身,否则我们无法生成最后一个整数的排列)。* 交换步骤可以通过将其与插入相结合来优化。*/for (i = 1; i < conn->nconnhost; i++){int j = pg_prng_uint64_range(&conn->prng_state, 0, i);pg_conn_host temp = conn->connhost[j];conn->connhost[j] = conn->connhost[i];conn->connhost[i] = temp;}}...
}
// src/interfaces/libpq/fe-connect.c/* ----------------* PQconnectPoll** Poll an asynchronous connection.* 轮询异步连接** Returns a PostgresPollingStatusType.* Before calling this function, use select(2) to determine when data* has arrived..* 在调用此函数之前,使用 select(2) 来确定数据何时到达。** You must call PQfinish whether or not this fails.** This function and PQconnectStart are intended to allow connections to be* made without blocking the execution of your program on remote I/O. However,* there are a number of caveats:* 此函数和 PQconnectStart 旨在允许建立连接而不阻塞程序在远程 I/O 上的执行。* 但是,有许多注意事项:** o If you call PQtrace, ensure that the stream object into which you trace* will not block.* 如果调用 PQtrace,请确保您跟踪的流对象不会阻塞。* o If you do not supply an IP address for the remote host (i.e. you* supply a host name instead) then PQconnectStart will block on* getaddrinfo. You will be fine if using Unix sockets (i.e. by* supplying neither a host name nor a host address).* 如果您不提供远程主机的 IP 地址(即您提供的是主机名),那么 PQconnectStart 将在 getaddrinfo 上阻塞。* 如果使用 Unix 套接字(即不提供主机名和主机地址),则不会有问题。* o If your backend wants to use Kerberos authentication then you must* supply both a host name and a host address, otherwise this function* may block on gethostname.* 如果您的后端想要使用 Kerberos 身份验证,那么您必须提供主机名和主机地址,否则此功能可能会在 gethostname 上阻止。** ----------------*/
PostgresPollingStatusType
PQconnectPoll(PGconn *conn)
{.../* Time to advance to next address, or next host if no more addresses? */// 是否需要前进到下一个地址,或者如果没有更多地址则前进到下一个主机?if (conn->try_next_addr){if (conn->whichaddr < conn->naddr){conn->whichaddr++;reset_connection_state_machine = true;}elseconn->try_next_host = true;conn->try_next_addr = false;}/* Time to advance to next connhost[] entry? */// 是时候前进到下一个 connhost[] 条目了吗?if (conn->try_next_host){.../** If random load balancing is enabled we shuffle the addresses.* 如果启用了随机负载平衡,我们就会打乱地址。*/if (conn->load_balance_type == LOAD_BALANCE_RANDOM){/** This is the "inside-out" variant of the Fisher-Yates shuffle* algorithm. Notionally, we append each new value to the array* and then swap it with a randomly-chosen array element (possibly* including itself, else we fail to generate permutations with* the last integer last). The swap step can be optimized by* combining it with the insertion.* 这是 Fisher-Yates 洗牌算法的“由内而外”变体。* 理论上,我们将每个新值附加到数组中,然后将其与随机选择的数组元素交换(可能包括其自身,否则我们无法生成最后一个整数的排列)。* 交换步骤可以通过将其与插入相结合来优化。** We don't need to initialize conn->prng_state here, because that* already happened in pqConnectOptions2.* 我们不需要在这里初始化 conn->prng_state,因为这已经在 pqConnectOptions2 中发生了。*/for (int i = 1; i < conn->naddr; i++){int j = pg_prng_uint64_range(&conn->prng_state, 0, i);AddrInfo temp = conn->addr[j];conn->addr[j] = conn->addr[i];conn->addr[i] = temp;}}reset_connection_state_machine = true;conn->try_next_host = false;...}...
}
下面我们来调试一下,(配置还是和之前一样),如下:
{"name": "(gdb) 启动","type": "cppdbg","request": "launch","program": "/home/postgres/test/bin/psql","args": ["host=localhost,localhost,localhost port=5432,5433,5434 load_balance_hosts=random dbname=postgres"],"stopAtEntry": false,"cwd": "${fileDirname}","environment": [],"externalConsole": false,"MIMode": "gdb","setupCommands": [{"description": "为 gdb 启用整齐打印","text": "-enable-pretty-printing","ignoreFailures": true},{"description": "将反汇编风格设置为 Intel","text": "-gdb-set disassembly-flavor intel","ignoreFailures": true}]}
看一下本机(此次三个data是在一台机器上,区别仅port不同)的host配置,如下:
[postgres@localhost:~/postgres → REL_17_0]$ cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[postgres@localhost:~/postgres → REL_17_0]$
如上,说明一下:
- 第一行是针对 IPv4 环境的主机名绑定,
127.0.0.1是 IPv4 回环地址。 - 第二行是针对 IPv6 环境的主机名绑定,
::1是 IPv6 回环地址。 - 通过这两行配置,系统和应用程序可以在 IPv4 和 IPv6 两种网络环境中,均能正确解析 localhost。
开始调试,如下:

调整顺序之前,host的排序就是初始设置的!

如上,经过调整之后的host顺序就是5433 5432 5434,此时的函数堆栈,如下:
libpq.so.5!pqConnectOptions2(PGconn * conn) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:1840)
libpq.so.5!PQconnectStartParams(const char * const * keywords, const char * const * values, int expand_dbname) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:837)
libpq.so.5!PQconnectdbParams(const char * const * keywords, const char * const * values, int expand_dbname) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:693)
main(int argc, char ** argv) (\home\postgres\postgres\src\bin\psql\startup.c:272)
然后进入pqConnectDBStart函数,开始相关初始化,如下:

.../** Set up to try to connect to the first host. (Setting whichhost = -1 is* a bit of a cheat, but PQconnectPoll will advance it to 0 before* anything else looks at it.)* 设置尝试连接到第一台主机。* 设置 whichhost = -1 有点作弊,但是 PQconnectPoll 会在任何其他东西查看它之前将其推进到 0** Cancel requests are special though, they should only try one host and* address, and these fields have already been set up in PQcancelCreate,* so leave these fields alone for cancel requests.* 但是取消请求很特殊,它们应该只尝试一个主机和地址,并且这些字段已经在 PQcancelCreate 中设置,因此对于取消请求,请保留这些字段。*/if (!conn->cancelRequest){conn->whichhost = -1;conn->try_next_host = true;conn->try_next_addr = false;}
...
然后进入PQconnectPoll,选择host如下:

此时conn->whichhost = 0,于是选择的host就是上面的localhost 5433了。
然后就到了IP的重新排序这里,初始状态如下:

在网络编程中,address family(地址族) 用于指定套接字(socket)的协议族,即网络通信使用的地址类型。AF_INET 和 AF_INET6 是常见的地址族,而它们的数字表示在底层代码中也被用到。以下是 address family 10 和 2 的含义:
对比总结:
| Address Family | 数字表示 | 含义 | 地址格式 | 应用场景 |
|---|---|---|---|---|
AF_INET | 2 | IPv4 地址族 | 点分十进制(x.x.x.x) | IPv4 网络通信 |
AF_INET6 | 10 | IPv6 地址族 | 十六进制(x:x::x:x) | IPv6 网络通信 |
扩展信息:
其他常见的 address family:
AF_UNIX(1):本地 Unix 套接字,用于同一台机器上进程间通信。AF_PACKET(17):用于底层网络接口的原始套接字(主要在 Linux 中)。
经过调整之后,顺序没有发生变化,如下:
libpq.so.5!PQconnectPoll(PGconn * conn) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:2998)
libpq.so.5!pqConnectDBStart(PGconn * conn) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:2446)
libpq.so.5!PQconnectStartParams(const char * const * keywords, const char * const * values, int expand_dbname) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:843)
libpq.so.5!PQconnectdbParams(const char * const * keywords, const char * const * values, int expand_dbname) (\home\postgres\postgres\src\interfaces\libpq\fe-connect.c:693)
main(int argc, char ** argv) (\home\postgres\postgres\src\bin\psql\startup.c:272)

那么这个顺序下,优先选择的conn->connip,如下:

于是localhost + IPV6 + 5433,这样是无法建立连接的,如下:

然后再试一下另一个IP,如下:


当然我们知道这个也是无法建立连接的,如下:

然后接下来需要更换主机,也就是localhost 5432了(这里比较幸运,若是5434 那么久的重复一遍上面两次重试),如下:

此时conn->whichhost = 1,然后又到了对它的IP重排序的地方了,如下:

其初始的顺序也是10 和 2,这里也非常幸运 排完序之后就是2 和 10。这样我们直接IPV4就连接成功了,如下:

于是这次直接就成功了,下面是的留存,如下:
// &conn->errorMessage0x6c7bb0 "
connection to server at \"localhost\" (::1), port 5433 failed: 拒绝连接\n\tIs the server running on that host and accepting TCP/IP connections?\nconnection to server at \"localhost\" (127.0.0.1), port 5433 failed: 拒绝连接\n\tIs the server running on that host and accepting TCP/IP connections?\nconnection to server at \"localhost\" (127.0.0.1), port 5432 failed: "

最后简单小结一下:
- 对主机的排序 发生一次(仅一次),然后后面按照顺序依次选择
- 对选择的主机对应的IP再排序,这种发生的次数就是上面选择一个主机 排一次IP的顺序,直到成功建立连接
- 若是这样的情况(假设3个host,它们依次对应了1,2,3个IP),最差的情况(我们假定仍然只有一个data存活且是第一个)。主机排序1次,3次+2次的额外尝试将不可避免
- 在调试的过程中,可以将
connect_timeout也配置到连接字符串中 把该值设置大点,以避免人为因素的影响
最后的最后,我们再看一下上面如何做到随机:
// src/interfaces/libpq/fe-connect.c/** Initializes the prng_state field of the connection. We want something* unpredictable, so if possible, use high-quality random bits for the* seed. Otherwise, fall back to a seed based on the connection address,* timestamp and PID.* * 初始化连接的 prng_state 字段。* 我们想要一些不可预测的东西,因此如果可能的话,请使用高质量的随机位作为种子。* 否则,请回退到基于连接地址、时间戳和 PID 的种子。*/
static void
libpq_prng_init(PGconn *conn)
{uint64 rseed;struct timeval tval = {0};if (pg_prng_strong_seed(&conn->prng_state))return;gettimeofday(&tval, NULL);rseed = ((uintptr_t) conn) ^((uint64) getpid()) ^((uint64) tval.tv_usec) ^((uint64) tval.tv_sec);pg_prng_seed(&conn->prng_state, rseed);
}
简单解释一下上面的随机数种子函数:
- 初始化随机数生成器:该函数的目的是为 PostgreSQL 客户端连接初始化伪随机数生成器(PRNG)。它通过生成一个基于连接地址、进程 ID 和当前时间的种子来初始化 PRNG。
- 确保强种子:在初始化之前,函数会检查是否已经有一个强随机种子,如果已经有,就不再进行重新初始化。
- 多样性和不可预测性:通过结合连接的内存地址、进程 ID 和当前时间(包括微秒),生成的种子具有较好的随机性和不可预测性。
// src/common/pg_prng.c/** Select a random uint64 uniformly from the range [rmin, rmax].* If the range is empty, rmin is always produced.* 从范围 [rmin, rmax] 中均匀选择一个随机 uint64。* 如果范围为空,则始终生成 rmin。*/
uint64
pg_prng_uint64_range(pg_prng_state *state, uint64 rmin, uint64 rmax)
{uint64 val;if (likely(rmax > rmin)){/** Use bitmask rejection method to generate an offset in 0..range.* Each generated val is less than twice "range", so on average we* should not have to iterate more than twice.* 使用位掩码拒绝方法在 0..range 中生成偏移量。* 每个生成的值都小于“range”的两倍,因此平均而言我们不必迭代超过两次。*/uint64 range = rmax - rmin;uint32 rshift = 63 - pg_leftmost_one_pos64(range);do{val = xoroshiro128ss(state) >> rshift;} while (val > range);}elseval = 0;return rmin + val;
}
问题1:因为有小伙伴会问错误信息什么时候清理的,如下:

问题2:使用两种ip建立的连接分别长什么样,如下:

和