链接:https://www.zhihu.com/question/46563853/answer/153380355
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
针对这个问题,我们邀请了微软亚洲研究院机器学习组的首席研究员刘铁岩博士,为大家带来他眼中人工智能现状,包括面临的挑战与机遇。
<img src="https://pic1.zhimg.com/v2-16231a6e76200f0b01fc2d12fd12b1b0_b.png" data-rawwidth="2048" data-rawheight="1236" class="origin_image zh-lightbox-thumb" width="2048" data-original="https://pic1.zhimg.com/v2-16231a6e76200f0b01fc2d12fd12b1b0_r.png">
微软亚洲研究院机器学习组包含机器学习的各个主要方向,在理论、算法、应用等不同层面推动机器学习领域的学术前沿。该组目前的研究重点为深度学习、增强学习、分布式机器学习和图学习。其研究课题还包括排序学习、计算广告和云定价。在过去的十几年间,该组在顶级国际会议和期刊上发表了大量高质量论文,帮助微软的产品部门解决了很多复杂问题,并向开源社区贡献了微软分布式机器学习工具包(DMTK)和微软图引擎(Graph Engine),LightLDA、LightGBM等,并受到广泛关注。该组正在招贤纳士,诚邀各路英雄好汉加盟,共同逐鹿AI天下。联系我们。
——这里是正式回答的分割线——
要说人工智能发展到了什么程度,我们先来看看人工智能的历史进程。
人工智能从1956年的达特茅斯会议开始,到现在61年的历史,发展过程中风风雨雨,可以看到几起几落,至少我们经历过两个所谓人工智能的冬天。
每一次人工智能的崛起都是因为某种先进的技术发明,而每一次人工智能遇到了它的瓶颈,也都是因为人们对于人工智能技术的期望太高,超出了它技术能达到的水准。所以政府、基金会等撤资,导致了研究人员没有足够的资金去从事研究。
那么今天我们处在一个什么阶段呢?有人说现在是人工智能的春天,有人说是夏天,还有人悲观一点,说是秋天,秋天的意思就是冬天马上就来了。作为人工智能的学者,我们该怎么看待这件事情,我们能做些什么?不管大家怎么预测,至少今天还是一个人工智能的黄金时代。
为什么这么讲呢?接下来先给大家展示一些最近人工智能取得的成果,确实是之前十几年我们完全想不到的。
首先,我们讲人工智能在语音方面的突破,人工智能在语音识别,语音合成上面最近都取得了非常瞩目的结果。2016年10月份由微软美国研究院发布的一个语音识别的最新结果实现了错误率为5.9%的新突破,这是第一次用人工智能技术取得了跟人类似的语音识别的错误率。
其次,在图像方面,人工智能也有很多长足的进步,比如图像识别的ImageNet比赛,用计算机去识别数据集中1000个类别的图像。在2015年,来自微软亚洲研究院的技术——ResNet,获得了2015年ImageNet的冠军,错误率是3.5%,而人的错误率大概是5.1%。所以可看出在特定领域、特定类别下,其实计算机在图像识别上的能力已经超过了人的水平。2016年我们微软亚洲研究院再接再励,在比图像识别更难的一个任务——物体分割上面取得了冠军。
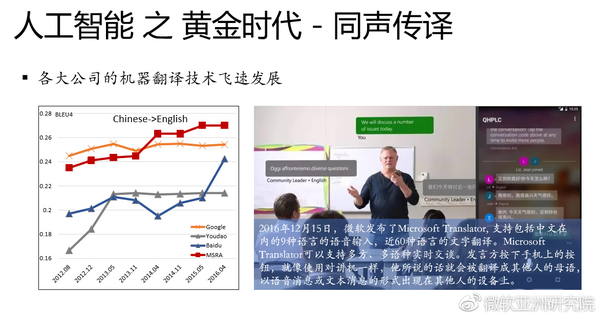
除了语音和图像以外,其实人工智能在自然语言上面也取得了很大的进展。左边这张图描述了各大公司都在不断地提高各自语音机器翻译的水准和技术,右边这张图展示的是去年12月微软发布了Microsoft Translator的一个新功能,它支持50多种语言,可以实现多个人多种语言的实时翻译,比如大家每个人可能来自不同的国家,只要拿着手机用这个APP我们就可以互相交流。你说一句话或者输入文字,对方听到/看到的就是他的母语。
<img src="https://pic2.zhimg.com/v2-106f73904bcb13248dea7f10dc378e0d_b.png" data-rawwidth="1172" data-rawheight="622" class="origin_image zh-lightbox-thumb" width="1172" data-original="https://pic2.zhimg.com/v2-106f73904bcb13248dea7f10dc378e0d_r.png">
前面说的这些语音、图像、语言,听起来还都是一些感知方面的东西。大家也知道,最近这段时间,人工智能在一些传统我们认为可能很难由机器来取得成功的领域也获得了突破。比如左边这张图描述的是用人工智能技术来打游戏,大家可以看到这个敲砖块的游戏,在120分钟训练的时候,人工智能就找到了很有效的得分的途径。当我们继续去训练这个人工智能的机器人,到了240分钟以后,它又达到了那种所谓骨灰级玩家的水准,它发现了一些平时我们自己都玩不出来的窍门。
<img src="https://pic3.zhimg.com/v2-c585cc94d4a65eac19069423062e5582_b.png" data-rawwidth="1161" data-rawheight="617" class="origin_image zh-lightbox-thumb" width="1161" data-original="https://pic3.zhimg.com/v2-c585cc94d4a65eac19069423062e5582_r.png">

右边展示的是围棋比赛,大家都知道AlphaGo非常火,使用了深度增强学习的技术,经过了非常长的训练时间,引用了大量数据做self-play,最终是以压倒性的优势,4:1战胜了当时的世界冠军李世石。在去年的IJCAI上面,AlphaGo主要的开发人员做了一个keynote,说自战胜了李世石之后,AlphaGo并没有停下脚步,因为它是一个self-play的process,可以继续训练,只要给他足够的运算时间和样例,它就可以不断地去训练。所以也能理解为什么今年年初Master重新回到大家视野里,可以对围棋高手60连胜,因为这个差距太大了。
这些事情都是以前人们觉得人工智能不可以去企及的领域。但正是因为这些计算机科学家、人工智能科学家不断地去模仿人的决策过程,比如他们训练了value network,训练了policy network,就是怎么样根据现在的棋局去评估胜率,去决定下一步该走什么子,而不是走简单的穷举,用这些value network来对搜索树进行有效的剪枝,从而在有限的时间内完成一个非常有意义的探索,所有这些都是人工智能技术取得的本质的进展,让我们看到了一些不一样的结果。
说了人工智能的这些辉煌之后,其实有很多问题是需要我们去冷静思考和回答的。
<img src="https://pic1.zhimg.com/v2-35fb4e11a0719721a5f937a4fa875830_b.png" data-rawwidth="1214" data-rawheight="618" class="origin_image zh-lightbox-thumb" width="1214" data-original="https://pic1.zhimg.com/v2-35fb4e11a0719721a5f937a4fa875830_r.png">

我们的主题是开启智能计算的研究之门,我想从一个研究者的角度跟大家讨论一下我们还能做些什么,甚至是更有意义的是去做些什么。人工智能表面看起来很火,其实如果把这张魔术的台布展开,你就会发现它千疮百孔,各种各样非常基础的问题其实并没有解决,甚至有很多哲学的方法论的东西从我们的角度来看可能也不准确。
面对这样的情况,更有意义的事情可能是冷静下来,去从事一些能够改变人工智能现状以及未来的很本质的基础研究工作,甚至是去反思人工智能发展的路线图,看看我们是不是应该重启一条道路。这些事情才能使得我们不仅仅是随波逐流,不仅仅是变点现,骗点钱,而是在人工智能发展的真正道路上留下我们自己的足迹,过了几十年当大家回忆的时候,另外一个人站在台上讲述人工智能一百年的时候,他会在那个图上标着一个星星,那里面讲的是你的故事。
前面这些人工智能现象的背后是什么?说到技术层面,现在最火的两个词,一个叫Deep Learning(深度学习),一个叫Reinforcement Learning(增强学习)。深度学习是什么?通俗地讲,它就是一个端到端的学习,我们不需要一些feature engineering,而是用一个非常复杂的、容量很大的模型去直接拟合输入输出,让模型自己探索有意义的中间表达。
什么是增强学习?通俗地讲,就是学习机器不断地跟环境做自主的互动,在互动的过程中用长远的收益来指导当下该做什么决策,通过不断的跟环境互动去调整决策的最优性。
<img src="https://pic2.zhimg.com/v2-cdf40e087fef0172677514cf5be2da4d_b.png" data-rawwidth="1600" data-rawheight="832" class="origin_image zh-lightbox-thumb" width="1600" data-original="https://pic2.zhimg.com/v2-cdf40e087fef0172677514cf5be2da4d_r.png">
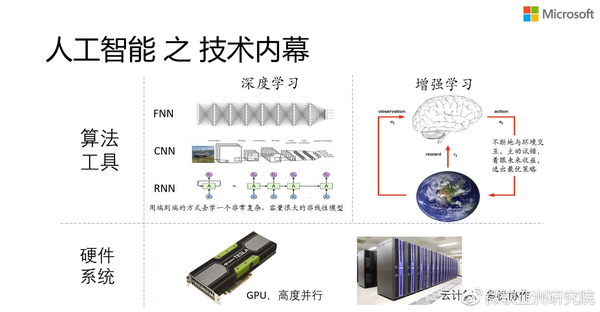
之所以现在深度学习和增强学习能够取得很大的成功,背后有一个很大的原因,就是基于巨大的数据和巨大的运算量训练出的拥有巨大容量的模型,所以它们的成功离不开硬件系统,这也是为什么现在GPU这么火,包括云计算、多机协作已经成了我们必不可少的环节。
这是现在人工智能的现状。面对这样的现状,我们是按照大家指定的这条道路去走,多搞几个GPU去训练一些模型跟别人PK,还是反思一下这条路对不对,有没有什么问题,接下来我想跟大家讨论的就是人工智能的诸多问题。我只列了一些其中的代表,但其实问题远远不止这些。
第一件事,现今的人工智能技术,尤其是以深度学习为代表的,需要大量的标注数据,来让我们能够训练一个有效的模型,它不太依赖于人的先验知识,要learning from scratch。如果想从零开始学习就需要有大量的样本提供规律。比如,图像分类,现在通常会用上千万张图像来训练;语音识别,成千上万小时的有标注的语音数据;机器翻译一般都是在千万量级的双语语对上去做训练,这样的数据之前是不可想象的,但是我们这个时代是大数据时代,所以有了这些数据,就使得深度学习训练成为了可能。但这是不是一剂万能的灵药呢?其实在很多领域里是不可能或者是很难获得类似的数据的。比如医疗上面,很多疑难杂症,全世界也没有几例,那怎么能够对这个类别搜集大数据。所以从这个意义上讲,如果我们能够找到一种方法克服对大的标注数据的需求,我们才能够使得现在的人工智能技术突破目前数据给它划定的边界,才能够深入到更多的领域里面去。
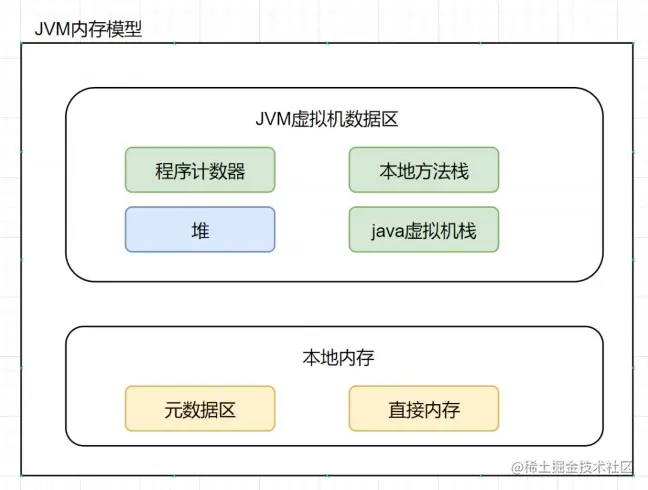
第二个挑战是关于模型大小以及模型训练难度的问题,前面提到了深度神经网络有很多层,而且一般参数都很大,几十亿的参数是家常便饭。面对这样的网络,至少有两个困难,一个是我们经常提到的梯度消减和梯度爆炸的问题,当深层网络有非常多层次的时候,输出层和标签之间运算出来的残差或者是损失函数,是很难有效地传递到底层去的。所以在用这种反向传播训练的时候,底层的网络参数通常不太容易被很有效的训练,表现不好。人们发明了各种各样的手段来解决它,比如加一些skip-level connection,像我们微软亚洲研究院发明的ResNet技术就是做这件事情的,还有很多各种各样的技巧。但这些其实都只是去解决问题的技巧,回过头来,原来的这个问题本身是不是必要的,是需要我们反思的。
再有就是模型爆炸。前面说了几十亿的参数是家常便饭,几十亿甚至上百亿个参数意味着什么,意味着模型本身的存储量是非常大的。举一个简单的例子,如果我们用神经网络来做语言模型,给出的训练数据集是Clueweb整个网络上的网页,大概有十亿个网页的量级。 这样的一个数据,如果要去用循环神经网络去训练一个语言模型,简单计算一下就会知道,它需要用到的模型的大小大概是80G到100G的大小,听起来好像不太大,但是现在主流的GPU板上的存储24G已经算是高配,换句话说,80G到100G的大小已经远远超过一个GPU卡的容量,那么就一定要做分布式的运算,还要做模型并行,有很多技术难度在里面。即便有一个GPU卡,能够放下这80G或100G的模型,如此大的训练数据过一遍也可能要用上百年的时间,这听起来也相当不靠谱。到底需不需要这么大的模型,有没有必要我们非要把自己放在一个内存也不够用,计算时间也非常长,也不能忍受的境地呢,这个是值得思考的问题。
<img src="https://pic1.zhimg.com/v2-6d6e276e14f4044d92f8d105f5df30bc_b.png" data-rawwidth="1158" data-rawheight="613" class="origin_image zh-lightbox-thumb" width="1158" data-original="https://pic1.zhimg.com/v2-6d6e276e14f4044d92f8d105f5df30bc_r.png">
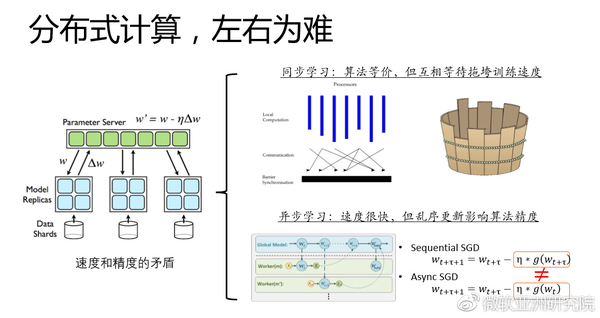
说到大模型,标注数据很大,那必然要提到分布式运算,分布式运算听起来是一个相对成熟的领域,因为系统领域已经对分布式计算研究了很多年。但是回到我们分布式机器学习这件事情上是有所不同的:这里我们做分布式运算的目的是为了让我们能够用更多的资源来容纳更大的模型,使得运算的时间缩短到能接受的程度,但是我们不想丢掉运算的精度。
举个例子,原来用上百年的时间可以得到一个非常精准的语言模型,现在有100台机器,虽然算的很快,但出来的语言模型不能用了,这件得不偿失。
说到分布式运算有两个主流的方式,一个是同步的并行方式,一个是异步的并行方式。同步的并行方式是什么,就是很多机器都分了一个子任务,大家每计算一步之后要互相等待,交换一下计算的结果,然后再往前走。这个过程能够保证对整个分布式运算的流程是可控的,可以知道发生了什么,在数学上可以做建模,能够在理论上有所保证。但它的问题就是所谓的木桶原理,这个集群里面只要有一台机器很慢,分布式运算就会被这台机器拖垮,就不会得到好的加速比。
所以人们开始做异步的并行方式,异步的意思就是每台机器各自做自己的事情,互相不等待,把当前按照各自的数据训练出来的模型更新推到某一个服务器上,再更新整体模型。但这时候又出现了一个新的问题,就是乱序更新的问题,这个过程是不能被我们原来的数学模型所描述的,违背了优化技术的一些基本假设。比如当我们使用随机梯度下降法的时候,可以证明当时用一个不断减小的学习率时,优化过程是有收敛性的。这是因为我们每一次增加的那个梯度是在上一次计算的模型基础上算出来的梯度。一旦加上去的梯度可能是旧的,不是依据前一个模型算出来的,到底优化过还能不能收敛,就不那么清楚了,所以虽然速度快,精度却可能没有保证。
第四个,我把它叫做调参黑科技,难言之隐。这件事情特别有趣,我前一段时间参加过一个论坛,一位嘉宾的一句话给我印象特别深,他说大家知道为什么现在很多公司都有深度学习实验室吗,以前没听说过有一个叫支持向量机实验室的,为什么?这是因为像SVM这样的技术训练过程非常简单,需要调节的超参数很少,基本上只要按部就班去做,得到的结果都差不多。
但深度学习这件事情,如果不来点调参黑科技,就得不到想要的结果。所谓深度学习实验室,就是一批会调参的人,没有他们深度学习就没那么好用。虽然是句玩笑,但是深度学习力要调的东西确实太多了,比如说训练数据怎么来,怎么选,如果是分布式运算怎么划分,神经网络结构怎么设计,10层、100层还是1000层,各层之间如何连接,模型更新的规则是什么,学习率怎么设,如果是分布式运算各个机器运算出来的结果怎么聚合,怎么得到统一的模型,等等,太多需要调的东西,一个地方调不好,结果可能就大相径庭。这就是为什么很多论文里的结果是不能重现的,不是说论文一定不对,但至少人家没有把怎么调参告诉你,他只告诉了你模型长什么样而已。
下一个挑战,叫做黑箱算法,不明就里。这不仅仅是神经网络的问题,更是统计机器学习多年来一直的顽疾,就是用一个表达能力很强的黑盒子来拟合想要研究的问题,里面参数很多。这样一个复杂的黑盒子去做拟合的时候,结果好,皆大欢喜。如果结果不好,出现了反例,该怎么解决呢,这里面几亿、几十亿个参数,是谁出了问题呢,其实是非常难排错的事情。相反,以前有很多基于逻辑推理的方法,虽然效果没有神经网络好,但是我们知道每一步是为什么做了决策,容易分析、排错。所以最近几年有一个趋势,就是把基于统计学习的方法和基于符号计算的方法进行结合,造出一个灰盒子,它既具备很强的学习能力,又能在很大程度上是可理解、可支配、可调整的。
<img src="https://pic1.zhimg.com/v2-8a874b260a505752f60a6b0933664278_b.png" data-rawwidth="1601" data-rawheight="786" class="origin_image zh-lightbox-thumb" width="1601" data-original="https://pic1.zhimg.com/v2-8a874b260a505752f60a6b0933664278_r.png">

到现在为止,这几件事都是现在人工智能技术层面的问题。接下来,谈的是更像方法论和哲学的问题,仅为个人的观点,跟大家一起分享。
其中一条,我叫做蛮力解法,舍本逐末。这句话什么意思?刚才我提到过深度学习之所以这么成功,是因为它有一个特别强的表达能力,在历史上人们证明过深层神经网络有universal approximation theorem,只要隐结点的数目足够多,任意给一个连续函数,它都可以无限逼近这个函数,换言之,有了很强的表达能力,什么问题都可以学的很好。听起来好像是挺美好的事,但实际上它背后存在一个问题:它拟合的是数据的表象,数据表象可以非常复杂,但是数据背后驱动的规律是不是真的那么复杂呢,如果我们只看到表象不去研究数据产生的本质,很可能你花了很大的力气去拟合,但是浪费了很多时间,得到的结果也不鲁棒。
举个例子,我们发现大自然也好,人类社会也好,其实没有想象的那么复杂,虽然你看到的很多数据很复杂,它们背后的规律可能非常简单。像量子力学有薛定谔方程、量子化学、流体力学、生物遗传学、经济学、社会学也都有类似的简单方程,科学家发现那么纷繁复杂的现象都可以被一个动态系统所刻划,而动态系统背后的规律可能就是一个最高二阶的偏微分方程。大家可以想象,如果不知道这些机理,不对动态系统做建模,只对动态系统的产出数据做建模,就会觉得这个问题非常复杂,要有一个容量非常大的神经网络去逼近这个数据。但反过来,如果目光焦点在这个动态系统身上,可能就两三个参数的一个二阶微分方程就搞定了。
下面也是一个值得思考的问题——动物智能,南辕北辙,虽然前面提到人工智能产生了很多的进步,但其实目前所做的还主要是认知的事情,做一个Pattern Recognition,听听声音,看看图像,这是动物也能做的事。今天的人工智能没有回答一个关键的问题,就是动物和人的区别。可能有人会讲,据说猴子的大脑比人的大脑小很多,有可能是体量的不同。但人的祖先跟大猩猩在包容量上应该没有本质的区别,那到底为什么经过漫长的进化,人能成为万物之灵主宰地球了呢?
我自己的观点是因为人类发明了很多动物界没有的机制和规律。比如我们有文字,我们可以把我们对世界的认知,总结出来的规律写下来,把它变成书,变成资料传给我们的下一代。当老一辈的人去世之后,孩子们读读书,就掌握了之前几百年几千年人们对世界的认识。但是老一代大猩猩死掉之后,它的孩子就要从头学起。另外,我们人类有强大的教育体系,人从幼儿园开始,小学,中学,一直进入大学,用了十几年的时间,就把几百年、几千年的知识都掌握在身上了,可以站在巨人的肩膀上继续往前走,这非常了不起。好的老师,会教出好的学生,教学相长,薪火相传。
这些人类的精髓在今天的人工智能技术里面是并没有充分体现,而没有它们我们怎么能指望深度神经网络达到人的智商呢?
前面列了很多方面,是我们对人工智能领域的一些看法,不管是从技术层面,还是方法论层面,都有很多值得进一步挖掘的点,只有这些问题真正解决了,人工智能才可能稳稳妥妥的往前走,而不只是昙花一现。
<img src="https://pic3.zhimg.com/v2-a0b536b084befef7aba7948d4177123a_b.png" data-rawwidth="1257" data-rawheight="673" class="origin_image zh-lightbox-thumb" width="1257" data-original="https://pic3.zhimg.com/v2-a0b536b084befef7aba7948d4177123a_r.png">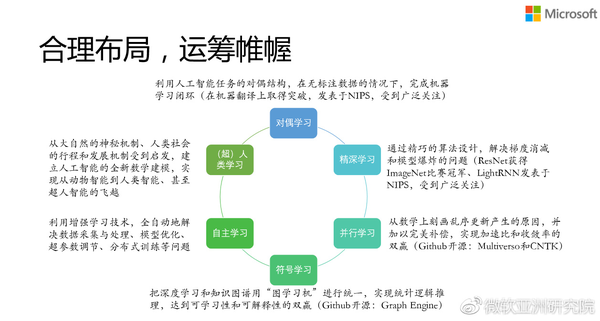
基于这些考虑,我所在的微软亚洲研究院机器学习组,对研究方向做了一个相应的布局,比如对偶学习,它解决的就是没有大规模标注数据的时候,该怎么训练一个神经网络、怎么训练一个增强学习模型。该论文发表在去年的NIPS大会上,获得了很大的反响。
还有,我们叫精深学习(Light Learning),为什么叫Light?前面提到很多模型太大,放不到GPU里,训练时间很长,我们这个研究就是去回答是否真的需要那么大的模型。我们展示了一个很有趣的深度学习算法,叫Light RNN,用该技术,只需要用一个非常小的模型在几天之内就可以把整个Clueweb数据学完,而且它得到的结果要比用大模型训练很长时间得到的结果还要好。
并行学习,之前提到并行学习有很多同步异步之间的权衡,我们发明了一个技术,它有异步并行的效率,但是能达到同步并行的精度,中间的技术解决方案其实很简单,在网上也有论文。我们用了泰勒展开,一个非常简单的数学工具,把这两者给结合在一起。
符号学习,就是想去解决黑白之间的那个灰盒子问题。
自主学习,是想去解决深度学习调参的黑科技,既然调参这么复杂,能不能用另外一个人工智能算法来调呢,能不能用增强学习的方法来调呢,所以我们做了一系列的工作来解决怎么去调各种各样的参数,怎么用另外一个机器学习来做这个机器学习。
最后一个方向,我们叫做超人类学习,我们想受大自然的启发,受人类社会发展的启发,去使得我们的人工智能技术接近人类,甚至超过人类,这背后是整个人工智能方法论的变化。
如果大家感兴趣,可以关注我们微软亚洲研究院机器学习组,跟我们共同从事机器学习的基础研究。
——这里是回答结束的分割线——
感谢大家的阅读。
本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。
微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。
也欢迎大家关注我们的微博和微信账号(搜索:微软亚洲研究院AI头条),了解更多我们研究。
http://weixin.qq.com/r/PUliejrEzWeyrX4Z9xwv (二维码自动识别)