一、评价搭配的概念
评价搭配是指在文本中,由评价词(如 “好”“坏”“优秀”“糟糕” 等表达主观意见的词)和被评价对象(如产品名称、服务类型、人物等)组成的语义单元。例如,在 “这部手机的拍照效果很好” 这句话中,“拍照效果” 是被评价对象,“好” 是评价词,它们构成了一个评价搭配。
评价搭配能够清晰地反映出人们对事物的看法和态度,对于挖掘文本中的观点、意见等情感信息非常重要。它有助于产品开发者了解消费者对产品各个方面的评价,也有助于商家分析用户对服务的满意度等诸多应用场景。
组成部分
评价词:是表达主观评价的词汇,包括形容词(如 “美味的”“难看的”)、副词(如 “非常好” 中的 “非常” 可以加强评价程度)、动词(如 “喜欢”“讨厌”)等。评价词的情感倾向可以是正面、负面或中性,并且其强度也有所不同,例如 “很好” 比 “好” 在情感强度上更强。
被评价对象:可以是具体的产品、服务、事件、人物等实体,也可以是抽象的概念。如在 “这个课程的实用性很强” 中,“课程” 是被评价对象,“实用性” 是课程的一个属性,也被包含在被评价对象的范畴内。
二、评价搭配抽取的算法
基于规则的方法
词性标注和语法规则
原理:首先对文本进行词性标注,识别出评价词(如形容词、副词、部分动词)和名词(作为潜在的被评价对象)。然后利用语法规则来抽取评价搭配。例如,规定形容词 + 名词的模式为一种可能的评价搭配。如 “漂亮的衣服”,通过词性标注识别出 “漂亮的” 为形容词,“衣服” 为名词,根据规则提取出这个评价搭配。
优点:简单易懂,在一些结构较为规整的文本中能够有效地抽取评价搭配,不需要大量的训练数据,计算成本低。
缺点:过度依赖语法规则,对于复杂的语言现象(如省略、倒装、隐喻等)处理能力差。不同语言的语法规则差异大,通用性不强。
句法分析和依存关系
原理:利用句法分析工具来解析句子的结构,确定单词之间的依存关系。例如,在依存句法分析中,“这部电影的剧情很吸引人”,“吸引人” 的主语是 “剧情”,通过分析这种依存关系可以提取出 “剧情 - 吸引人” 这个评价搭配。可以预先定义依存关系模式来抽取评价搭配,比如评价词与被评价对象之间的 “主谓关系”“定中关系” 等模式。
优点:能够处理一些复杂的句子结构,相比简单的词性标注规则,能够更准确地抽取评价搭配,尤其是对于长句子和具有复杂语法结构的句子。
缺点:句法分析本身可能会出现错误,特别是对于口语化、不规范的文本。而且,构建和维护有效的依存关系模式需要一定的语言学知识和经验。
基于统计的方法
共现频率统计
原理:计算评价词和潜在被评价对象在文本中的共现频率。如果一个评价词和一个名词经常一起出现,那么它们很可能构成评价搭配。例如,在大量的产品评论中,“耐用” 和 “手机电池” 经常同时出现,就可以将它们作为一个评价搭配。可以通过统计窗口(如设定一个句子或者固定的单词数量范围)来计算共现次数。
优点:不需要复杂的语言知识,能够从大规模文本数据中自动发现潜在的评价搭配,对语言的适应性较强,能够处理不同领域和风格的文本。
缺点:容易受到数据稀疏性的影响,对于低频共现的评价搭配可能会遗漏。共现不一定代表真正的评价关系,可能会出现虚假搭配,比如在某些文本中两个词偶然经常一起出现,但并非评价搭配。
关联规则挖掘(如 Apriori 算法)
原理:关联规则挖掘用于发现数据项之间的关联关系。在评价搭配抽取中,将评价词和被评价对象看作数据项。以 Apriori 算法为例,它通过频繁项集的挖掘来发现评价搭配。首先找出频繁出现的单个词(评价词或被评价对象),然后逐步组合这些词,找出满足最小支持度和置信度阈值的评价搭配。例如,如果 “美味” 和 “餐厅菜品” 的支持度(同时出现的频率)和置信度(在 “美味” 出现的情况下,“餐厅菜品” 出现的概率)都达到设定的阈值,就将它们作为评价搭配。
优点:能够挖掘出隐藏在文本数据中的评价搭配关系,对于处理大规模文本数据和发现复杂的搭配模式有一定的优势。
缺点:阈值的选择比较困难,不同的阈值可能会导致抽取结果的差异很大。而且,计算频繁项集可能会消耗大量的计算资源,尤其是在数据量很大的情况下。
基于机器学习的方法
有监督学习(如支持向量机、朴素贝叶斯)
原理:将评价搭配抽取看作是一个分类问题。首先需要构建一个标注好的训练数据集,其中包含正例(真正的评价搭配)和反例(不是评价搭配的词对)。然后利用支持向量机或朴素贝叶斯等机器学习算法来训练一个分类模型。对于新的文本,将其中的词对提取出来,作为模型的输入,模型输出这个词对是否是评价搭配。例如,在训练阶段,通过大量的人工标注评论数据来训练模型,在测试阶段,让模型判断 “出色 - 性能” 在新的产品评论中是否是评价搭配。
优点:在有足够的高质量训练数据的情况下,可以取得较好的抽取效果,能够学习到评价搭配的复杂语义和语法特征。
缺点:需要大量的标注数据来训练模型,标注数据的质量会直接影响模型的性能。而且,模型的泛化能力有限,对于新的领域或文本风格可能需要重新训练。
半监督学习(如协同训练)
原理:利用少量的标注数据和大量的未标注数据来进行评价搭配抽取。以协同训练为例,首先用少量标注数据训练两个不同的分类器(基于不同的特征或算法)。然后,让这两个分类器对未标注数据进行分类,选择分类置信度高的未标注数据加入到对方的训练集中,不断迭代这个过程。例如,一个分类器基于词性特征,另一个基于词向量特征,通过协同训练来提高对评价搭配抽取的性能。
优点:减少了对标注数据的依赖,能够利用大量的未标注数据来提高模型的性能,在一定程度上缓解了有监督学习中数据标注的难题。
缺点:初始的标注数据仍然需要保证一定的质量和代表性,否则可能会导致模型偏差。而且,协同训练的过程中可能会出现错误传播的情况,即一个分类器传递给另一个分类器的错误信息会影响整个模型的性能。
什么是评价搭配
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/491652.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

【数字花园】个人知识库网站搭建:①netlify免费搭建数字花园
目录 [[数字花园]]的构建原理包括三个步骤:五个部署方案教程相关教程使用的平台 步骤信息管理 这里记录的自己搭建数字花园(在线个人知识库)的经历,首先尝试的是网上普遍使用的方法,也就是本篇文章介绍的。 后面会继续…

el-table表格嵌套子表格:展开所有内容;对当前展开行内容修改,当前行默认展开;
原文1 原文2 原文3
一、如果全部展开
default-expand-all"true"
二、设置有数据的行打开下拉
1、父table需要绑定两个属性expand-row-key和row-key <el-table:data"tableData":expand-row-keys"expends" //expends是数组,设置…

区间预测 | MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测
区间预测 | MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRDNN深度神经网络分位数回归时间序列区间预测。QRDNN模型…

用.Net Core框架创建一个Web API接口服务器
我们选择一个Web Api类型的项目创建一个解决方案为解决方案取一个名称我们这里选择的是。Net 8.0框架
注意,需要勾选的项。 我们找到appsetting.json配置文件 appsettings.json配置文件内容如下
{"Logging": {"LogLevel": {"Default&quo…

扩展SpringBoot中的SpringMVC的默认配置
SpringBoot默认已经给我们做了很多SpringMVC的配置,哪些配置?
视图解析器ViewResolver静态资料的目录默认首页index.html图标名字和图标所在目录,favicon.ico类型转换器Converter,格式转换器的Formatter消息转换器HttpMessageCon…


2024安装hexo和next并部署到github和服务器最新教程
碎碎念
本来打算写点算法题上文所说的题目,结果被其他事情吸引了注意力。其实我之前也有过其他博客网站,但因为长期不维护,导致数据丢失其实是我懒得备份。这个博客现在部署在GitHub Pages上,github不倒,网站不灭&…

【鸿睿创智开发板试用】RK3568 NPU的人工智能推理测试
目录
引言
驱动移植
例程编译
修改build.sh
执行编译
运行测试
部署libc的库文件
执行测试程序
结语 引言
鸿睿创智的H01开发板是基于RK3568芯片的,瑞芯微芯片的一大特色就是提供了NPU推理的支持。本文将对其NPU推理进行测试。
驱动移植
H01的开发板已经…
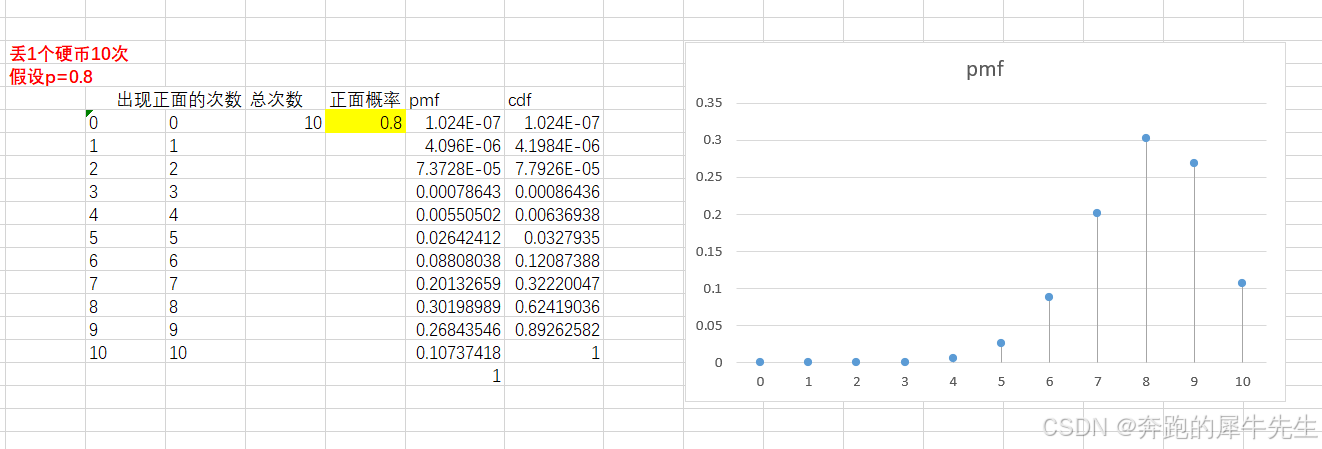
概率论得学习和整理29: 用EXCEL 描述二项分布
目录
1 关于二项分布的基本内容
2 二项分布的概率
2.1 核心要素
2.2 成功K次的概率,二项分布公式
2.3 期望和方差
2.4 具体试验
2.5 概率质量函数pmf 和cdf
3 二项分布的pmf图的改进
3.1 改进折线图
3.2 如何生成这种竖线图呢
4 不同的二项分布
4.1 p0.…


docker仓库数据传输加密
1.进行加密数据运算对配置文件底下的内容进行删除 [rootlocalhost ~]# vim /etc/docker/daemon.json 重新启动docker程序 [rootlocalhost ~]# systemctl restart docker 2.建立加密目录,生成认证key和证书 [rootlocalhost ~]# mkdir certs [rootlocalhost ~]# open…

大数据技术与应用——数据可视化(山东省大数据职称考试)
大数据分析应用-初级
第一部分 基础知识 一、大数据法律法规、政策文件、相关标准 二、计算机基础知识 三、信息化基础知识 四、密码学 五、大数据安全 六、数据库系统 七、数据仓库.
第二部分 专业知识 一、大数据技术与应用 二、大数据分析模型 三、数据科学 数据可视化
大…

【指南】03 CSC联系外导
确定外导
课题组有合作关系的国外导师与自己研究方向密切相关的国外导师国外高校官网、谷歌学术、Research Gate等平台检索不可以是中国港澳台的高校科研院所或机构注意外导所在高校排名和科研水平可列表记录注意外国签证政策
发送邮件
自我介绍简要介绍CSC介绍自己的研究对…

0基础学前端-----CSS DAY6
0基础学前端-----CSS DAY6
视频参考:B站Pink老师 今天是CSS学习的第六天,今天开始的笔记对应Pink老师课程中的CSS第三天的内容。 本节重点:CSS的三大特性以及CSS的盒子模型。
1.CSS的三大特性
CSS有三个重要特性:层叠性、继承性…

本地部署大模型QPS推理测试
目录 1、测试环境1.1、显卡1.2、模型1.3、部署环境1.3.1、docker1.3.2、执行命令 2、测试问题2.1、20字左右问题2.2、50字左右问题2.3、100字左右问题 3、测试代码3.1、通用测试代码3.2、通用测试代码(仅供参考) 4、测试结果4.1、通用测试结果4.2、RAG测…

测试工程师八股文04|计算机网络 和 其他
一、计算机网络
1、http和https的区别
HTTP和HTTPS是用于在互联网上传输数据的协议。它们都是应用层协议,建立在TCP/IP协议栈之上,用于客户端(如浏览器)和服务器之间的通信。 ①http和https的主要区别在于安全性。http是一种明…

【Tomcat】第一站:理解tomcat与Socket
目录
1. Tomcat
1.1 Tomcat帮助启动http服务器。
1.2 tomcat理解:
2. 计算机网络最基本的流程 2.1 信息是怎么来的?
2.2 端口是干什么的?
3. 简单的Socket案例
服务端
客户端
启动:
3.2 在Tomcat发送信息,看…

抖音SEO短视频矩阵源码系统开发分享
在数字营销的前沿阵地,抖音短视频平台凭借其独特的魅力和庞大的用户基础,已成为社交媒体领域一股不可小觑的力量。随着平台影响力的持续扩大,如何有效提升视频内容的可见度与流量成为了内容创作者关注的焦点。在此背景下,一套专为…

使用 DeepSpeed 微调 OPT 基础语言模型
文章目录 OPT 基础语言模型Using OPT with DeepSpeedmain.py 解析1、导入库和模块2、解析命令行参数3、main 函数3.1 设备与分布式初始化3.2 模型与数据准备3.3 定义评估函数3.4 优化器与学习率调度器设置3.5 使用 deepspeed 进行模型等初始化3.6 训练循环3.7 模型保存 4、dsch…

window QT/C++ 与 lua交互(mingw + lua + LuaBridge + luasocket)
一、环境与准备工作
测试环境:win10 编译器:mingw QT版本:QT5.12.3 下载三种源码: LuaBridge源码:https://github.com/vinniefalco/LuaBridge LUA源码(本测试用的是5.3.5):https://www.lua.org/download.html luasocket源码:https://github.com/diegonehab/luasocket 目…