目录
Python正则表达式re库的基本用法
引入re库
各函数功能
总结
使用方法举例
正则表达式语法与书写方式
正则表达式的常用操作符
思科ASA防火墙数据
数据1
数据2
书写正则表达式
Python中pydantic的使用
导入基础数据模板
根据数据采集目标定义Pydantic数据类型
数据分析采集函数
Python正则表达式re库的基本用法
引入re库
import re各函数功能
| 函数 | 用法 |
| re.match() | 从字符串起始位置用正则表达式进行数据匹配,匹配到一个数据立即结束并返回第一个匹配到的结果,返回一个Match object对象 |
| re.search() | 从字符串起始位置用正则表达式进行数据匹配,返回一个Match object对象,含有第一个匹配到数据的位置 |
| re.findall() | 从字符串起始位置用自定义的正则表达式进行数据匹配,一直尝试匹配到字符串结束,返回匹配到的所有子串,是一个列表 |
| re.split() | 从字符串起始位置用自定义的正则表达式进行数据匹配,一直尝试匹配到字符串结束,将字符串按正则表达式匹配到的结果进行分割,返回被分割的子串,是一个列表 |
| re.sub() | 从字符串起始位置用自定义的正则表达式进行数据匹配,一直尝试匹配到字符串结束,将字符串中按正则表达式匹配到的子串全部替换为自定义的内容,返回被替换后的字符串 |
| re.finditer() | 从字符串起始位置用自定义的正则表达式进行数据匹配,一直尝试匹配到字符串结束,返回一个callable_iterator object对象,可以被迭代,里面每个数据是Match object对象 |
总结
其实在数据处理中我使用re.search()居多,在使用上也很符合查找内容的惯性思维,把需要采集的数据拆分书写成一个个短小的正则表达式,写出的代码也容易维护,缺点是会对字符串进行多次匹配,会浪费资源,如果设涉及大量数据的分析采集推荐使用re.match()或者是混合使用其他函数,并书写单个较长的正则表达式可以达到节省资源的目的
使用方法举例
data = re.match(正则表达式,需要处理的字符串,匹配选项)
在Python中正则表达式的格式为:r'...正则表达式内容...'
例如data = re.match(r'[0-9]', '123')
正则表达式语法与书写方式
正则表达式的常用操作符
其余可自行搜索用法,本文主要涉及这几个
| 符号 | 说明 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符 |
| \d | 匹配一个数字,等价于[0-9] |
| \D | 匹配一个任何非数字字符,等价于[^0-9] |
| \s | 匹配一个任何空白字符,如空格 |
| \S | 匹配一个任何非空白字符 |
| \n | 匹配一个换行符 |
| * | 匹配前一个字符0次或无限次 |
| + | 匹配前一个字符1次或无限次 |
| () | 用于标明匹配组,方便用一个正则表达式匹配多个内容 |
在学习如何书写正则表达式之前需要先了解下需要处理的数据
思科ASA防火墙数据
数据1
用Python脚本连接思科ASA防火墙执行如下命令获取(此文章不介绍如何采集数据,数据均为样例,和真实环境也会有出入)
show interface ip brief回显内容
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 192.168.1.1 YES manual up up
Ethernet0/1 10.1.1.1 YES manual up up数据2
执行命令
show interface detail回显内容
Interface Ethernet0 "outside", is up, line protocol is upHardware is i82558, BW 100 Mbps, DLY 100 usecAuto-Duplex(Full-duplex), Auto-Speed(100 Mbps)Input flow control is unsupported, output flow control is unsupportedMAC address 001e.4f9c.2345, MTU 1500IP address 172.16.0.1, subnet mask 255.255.255.128132463 packets input, 9245212 bytes, 0 no bufferReceived 24 broadcasts, 0 runts, 0 giants0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort0 pause input, 0 resume input0 L2 decode drops238982 packets output, 15789347 bytes, 0 underruns0 pause output, 0 resume output0 output errors, 0 collisions, 0 interface resets0 babbles, 0 late collisions, 0 deferred0 lost carrier, 0 no carrier0 input reset drops, 0 output reset dropsinput queue (curr/max packets): hardware (0/1) software (0/8)output queue (curr/max packets): hardware (0/9) software (0/1)Traffic Statistics for "outside":132463 packets input, 9245212 bytes238982 packets output, 15789347 bytes3258 packets dropped1 minute input rate 2 pkts/sec, 110 bytes/sec1 minute output rate 7 pkts/sec, 980 bytes/sec1 minute drop rate, 0 pkts/sec5 minute input rate 3 pkts/sec, 150 bytes/sec5 minute output rate 8 pkts/sec, 1012 bytes/sec5 minute drop rate, 0 pkts/secControl Point Interface States:Interface number is 1Interface config status is activeInterface state is activeInterface Ethernet1 "inside", is up, line protocol is upHardware is i82558, BW 100 Mbps, DLY 100 usecAuto-Duplex(Full-duplex), Auto-Speed(100 Mbps)Input flow control is unsupported, output flow control is unsupportedMAC address 001e.4f9c.6789, MTU 1500IP address 192.168.10.1, subnet mask 255.255.255.0204892 packets input, 14235129 bytes, 0 no bufferReceived 18 broadcasts, 0 runts, 0 giants0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored, 0 abort0 pause input, 0 resume input0 L2 decode drops174562 packets output, 20982145 bytes, 0 underruns0 pause output, 0 resume output0 output errors, 0 collisions, 0 interface resets0 babbles, 0 late collisions, 0 deferred0 lost carrier, 0 no carrier0 input reset drops, 0 output reset dropsinput queue (curr/max packets): hardware (0/1) software (0/10)output queue (curr/max packets): hardware (2/10) software (0/1)Traffic Statistics for "inside":204892 packets input, 14235129 bytes174562 packets output, 20982145 bytes5124 packets dropped1 minute input rate 4 pkts/sec, 360 bytes/sec1 minute output rate 6 pkts/sec, 890 bytes/sec1 minute drop rate, 1 pkts/sec5 minute input rate 5 pkts/sec, 480 bytes/sec5 minute output rate 7 pkts/sec, 910 bytes/sec5 minute drop rate, 0 pkts/secControl Point Interface States:Interface number is 2Interface config status is activeInterface state is active书写正则表达式
先来一个简单的例子,在执行了show interface ip brief后会显示出接口状态和其ip地址等信息
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 192.168.1.1 YES manual up up
Ethernet0/1 10.1.1.1 YES manual up up现在假设我只对接口名称和其对应的ip地址感兴趣,想要用正则表达式将他们提取出来可以使用如下正则表达式,这个表达式还有一些小瑕疵,下面来拆解看一下他的含义:
推荐正则表达式辅助书写和练习的工具:regex101: build, test, and debug regex
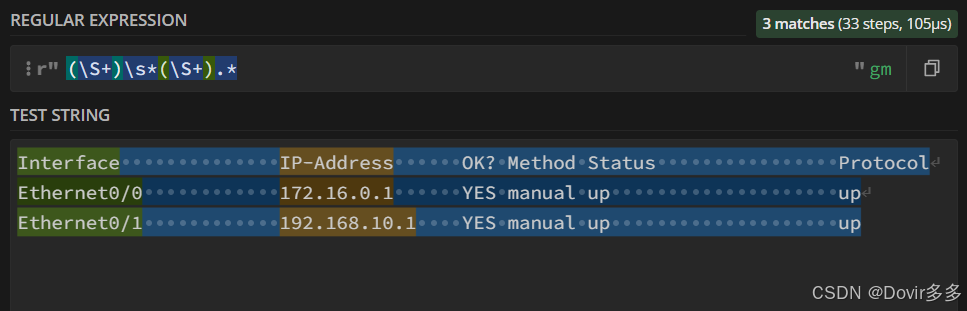
(\S+)\s*(\S+).*
其中被"()"括起来的内容为我们想要捕获的数据,获取第一个"()"中的内容可对返回的对象使用.group(1)方法来获取以此类推获取第二个可用.group(2)来获取
\S匹配一个任何非空白字符,后面添加“+”符号代表连续匹配1个以上的非空白字符:
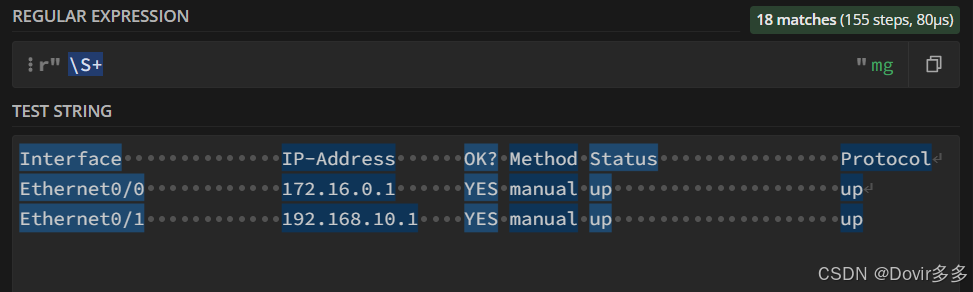
\s匹配一个任何空白字符,如空格,后面加“*”代表连续匹配0个以上的非空白字符:
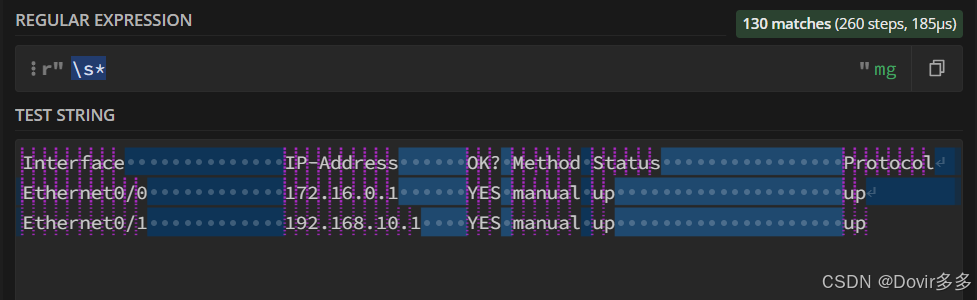
将这两者组合起来:
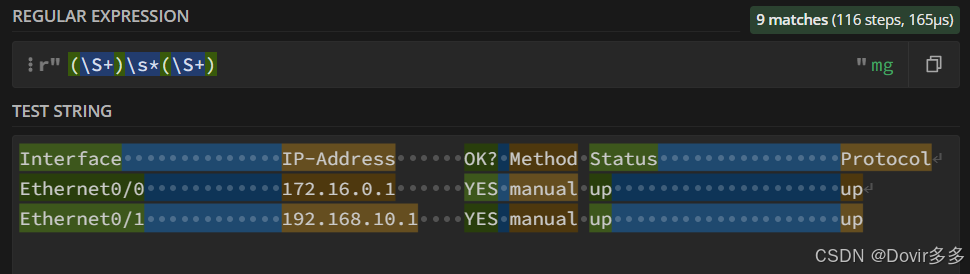
发现除了名称和ip之外还匹配到了其他内容,可以在后面加上“.*”直接代替其余内容直到出现换行符\n:
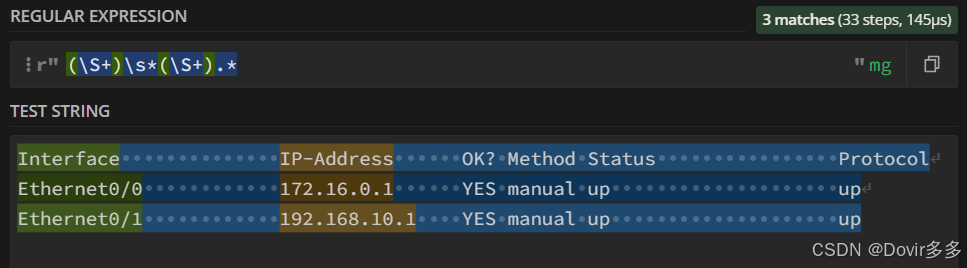
发现还有一个小细节没考虑到,会匹配到上面的描述字段“Interface” 、“IP-Address”,这时可以观察感想要匹配数据的特征来做一个排除,“Ethernet0/0”可以拆分成多个字符+一个数字的形式,即拆分成:“Ethernet0/”和“0”,其余数据也适用,都可以堪称一个字符+结尾一个数字的格式,这时可以做一下修改,把“(\S+)”修改为“(\S+\d)”:
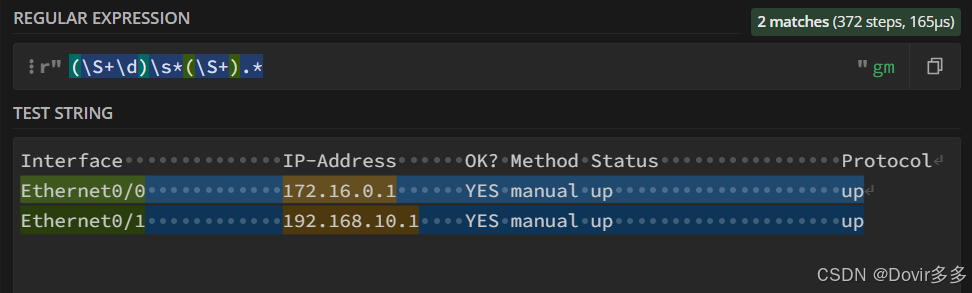
这样就可以成功获取到想要的数据了,可以编写python代码来试验一下:
import redata = """
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 192.168.1.1 YES manual up up
Ethernet0/1 10.1.1.1 YES manual up up
"""interface_match = re.search(r'(\S+\d)\s*(\S+).*', data)print(interface_match.group(1))
print(interface_match.group(2))输出结果:
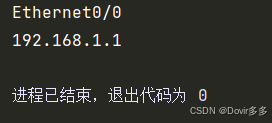
re.search方法会在查找到第一个数据后停止匹配,返回第一次匹配到的结果,如果想要捕获所有的Interface数据,可以先将data按行进行分割再进行匹配:
import redata = """
Interface IP-Address OK? Method Status Protocol
Ethernet0/0 192.168.1.1 YES manual up up
Ethernet0/1 10.1.1.1 YES manual up up
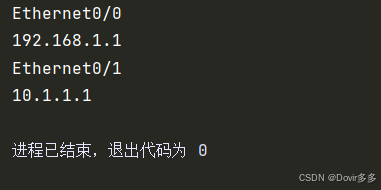
"""data_list = data.split('\n')
for line in data_list:interface_match = re.search(r'(\S+\d)\s*(\S+).*', line)if interface_match:print(interface_match.group(1))print(interface_match.group(2))输出结果:
Python中pydantic的使用
导入基础数据模板
from pydantic import BaseModel一个简单的例子
pydantic在python开发中可以将数据类型明确,也方便对数据的校验
from pydantic import BaseModelclass User(BaseModel):id: intname: strpermission: list[str]user = User(id=123456, name='admin',permission=['can_add_student','can_edit_student'])print(user)
根据数据采集目标定义Pydantic数据类型

# 定义Pydantic数据类型
class Count(BaseModel):packets: intpackets_rate: strbytes: intbytes_rate: strclass Input(Count):passclass Output(Count):passclass Dropped(Count):passclass InterfaceStatus(BaseModel):input_status: Inputoutput_status: Outputdrop_status: Droppedclass InterfaceBaseInfo(BaseModel):name: strstatus: strprotocol_status: strip_address: strsubnet_mask: strmac_address: strbandwidth: strdelay: strmtu: inthardware_type: strclass Interface(BaseModel):base_info: InterfaceBaseInfodetail_info: InterfaceStatusclass ASAData(BaseModel):outside_interface: Interfaceinside_interface: Interface数据分析采集函数
和上面的思路一样,只是多了很多需要匹配的数据
def get_asa_data():# 声明interfaces = {}# 处理interface_detail返回数据for paragraph in interface_detail.split("Interface"):if not paragraph.strip():continue# 正则匹配base_infoname_match = re.search(r'(\S+)\s"(\S+)",', paragraph)mac_mtu_match = re.search(r'MAC\saddress\s+(\S+),\sMTU\s(\d+)', paragraph)ip_match = re.search(r'IP\saddress\s(\S+),.*mask\s(\S+)', paragraph)hardware_match = re.search(r'Hardware\sis\s(.*),\sBW\s(.*),\sDLY\s(.*)', paragraph)if not name_match or not mac_mtu_match or not ip_match or not hardware_match:continuebase_info = {"name": name_match.group(1),"status": "None", # 先做初始化,后续再从interface_ip_brief中获取"protocol_status": "None","ip_address": ip_match.group(1),"subnet_mask": ip_match.group(2),"mac_address": mac_mtu_match.group(1),"bandwidth": hardware_match.group(2),"delay": hardware_match.group(3),"mtu": int(mac_mtu_match.group(2)),"hardware_type": hardware_match.group(1),}# 正则匹配detail_infoinput_match = re.search(r'(\d+)\spackets\sinput,\s(\d+)\sbytes', paragraph)input_rate_match = re.search(r'5\sminute\sinput\srate\s(.*),\s+(.*)', paragraph)output_match = re.search(r'(\d+)\spackets\soutput,\s(\d+)\sbytes', paragraph)output_rate_match = re.search(r'5\sminute\soutput\srate\s(.*),\s+(.*)', paragraph)drop_match = re.search(r'(\d+)\spackets\sdropped', paragraph)drop_rate_match = re.search(r'5\sminute\sdrop\srate,\s(.*)', paragraph)detail_info = {"input_status": Input(packets = int(input_match.group(1)) if input_match else -1,bytes = int(input_match.group(2)) if input_match else -1,packets_rate = input_rate_match.group(1) if input_rate_match else "None",bytes_rate = input_rate_match.group(2) if input_rate_match else "None",),"output_status": Output(packets = int(output_match.group(1)) if output_match else -1,bytes = int(output_match.group(2)) if output_match else -1,packets_rate = output_rate_match.group(1) if output_rate_match else "None",bytes_rate = output_rate_match.group(2) if output_rate_match else "None",),"drop_status": Dropped(packets = int(drop_match.group(1)) if drop_match else -1,bytes = -1,packets_rate = drop_rate_match.group(1) if drop_rate_match else "None",bytes_rate = "None",),}interface_name = name_match.group(2)interfaces[interface_name] = Interface(base_info=InterfaceBaseInfo(**base_info),detail_info=InterfaceStatus(**detail_info),)# 处理interface_ip_brie返回数据for line in interface_ip_brief.strip().split("\n"):match = re.search(r'(\S+)\s+(\S+)\s+\S+\s+\S+\s+(\S+)\s+(\S+)', line)if match:name, ip, status, protocol_status = match.groups()for interface in interfaces.values():if interface.base_info.ip_address == ip:interface.base_info.status = statusinterface.base_info.protocol_status = protocol_statusasa_data = ASAData(outside_interface=interfaces.get("outside"),inside_interface=interfaces.get("inside"),)# 将数据格式化为json返回return(asa_data.json())打印输出结果
# 打印输出结果
print(get_asa_data())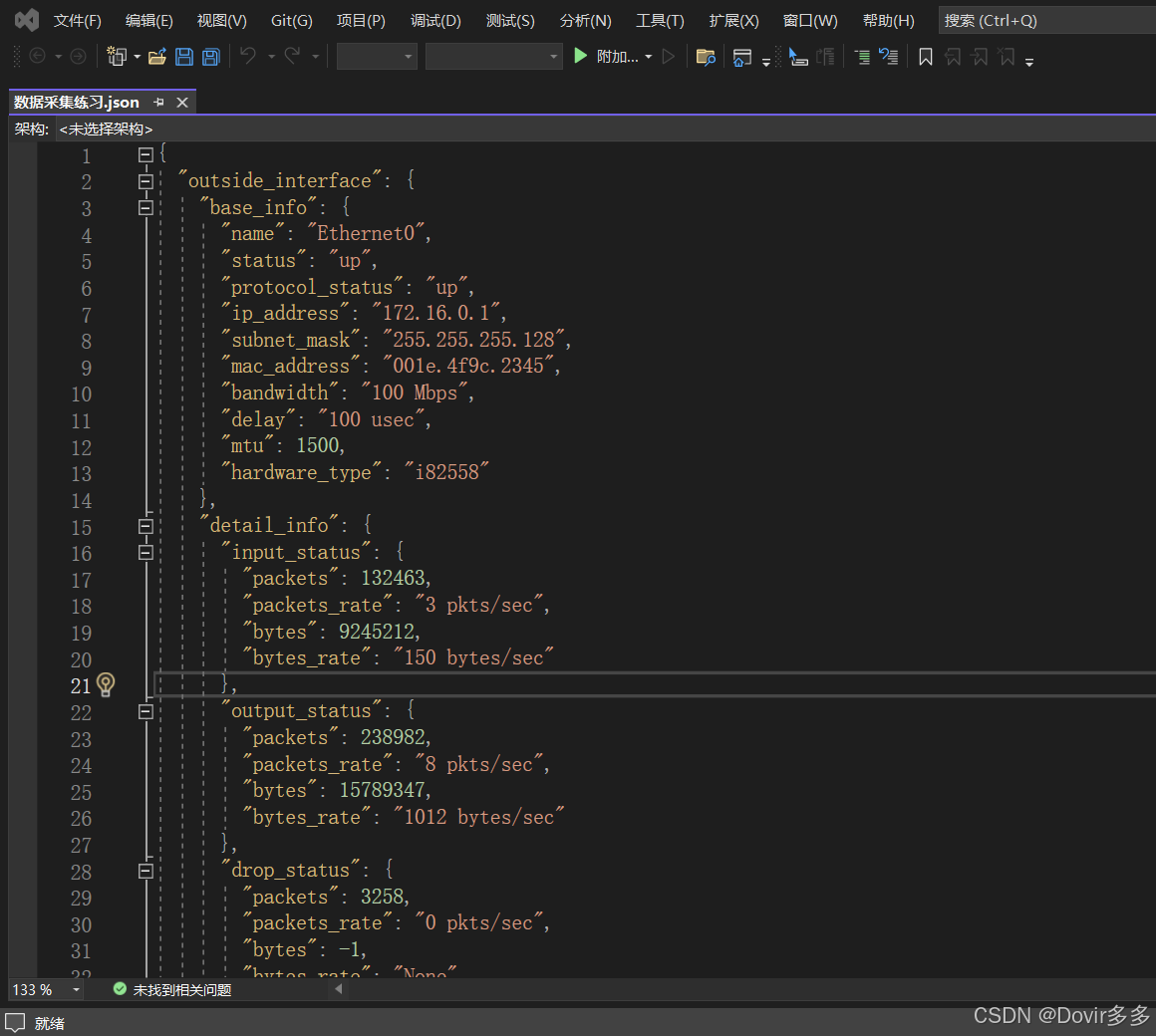










![[Python机器学习]:Anaconda3实践环境安装和使用](https://i-blog.csdnimg.cn/direct/484e641b18114b94970d9e6a488d8c68.png)







![【Linux系列】Shell 脚本中的条件判断:`[ ]`与`[[ ]]`的比较](https://img-blog.csdnimg.cn/img_convert/a08571f736dc04b5bef51cd09e8e3a0a.gif#pic_center)
