为什么深度学习和神经网络要使用 GPU?
本篇文章的目标是帮助初学者了解 CUDA 是什么,以及它如何与 PyTorch 配合使用,更重要的是,我们为何在神经网络编程中使用 GPU。
图形处理单元 (GPU)
要了解 CUDA,我们需要对图形处理单元 (GPU) 有一定的了解。GPU 是一种擅长处理 专门化 计算的处理器。
这与中央处理单元 (CPU) 形成对比,CPU 是一种擅长处理 通用 计算的处理器。CPU 是为我们的电子设备上大多数典型计算提供动力的处理器。
GPU 可以比 CPU 快得多,但并非总是如此。GPU 相对于 CPU 的速度取决于正在执行的计算类型。最适合 GPU 的计算类型是能够 并行 进行的计算。
并行计算
并行计算是一种将特定计算分解为可以同时进行的独立较小计算的计算类型。然后将得到的计算结果重新组合或同步,以形成原始较大计算的结果。

一个较大任务可以分解为的任务数量取决于特定硬件上包含的内核数量。内核是实际在给定处理器内进行计算的单元,CPU 通常有四、八或十六个内核,而 GPU 可能有数千个内核。
还有其他一些技术规格也很重要,但本描述旨在传达一般概念。
有了这些基础知识,我们可以得出结论,使用 GPU 进行并行计算,并且最适合使用 GPU 解决的任务是能够并行完成的任务。如果计算可以并行完成,我们就可以通过并行编程方法和 GPU 加速我们的计算。
神经网络是令人尴尬的并行
现在让我们关注神经网络,看看为何深度学习如此大量地使用 GPU。我们刚刚了解到 GPU 适合进行并行计算,而这一事实正是深度学习使用它们的原因。神经网络是 令人尴尬的并行。
在并行计算中,一个 令人尴尬的并行 任务是指几乎不需要将整体任务分解为一组可以并行计算的较小任务。
令人尴尬的并行任务是那些很容易看出一组较小任务彼此独立的任务。

神经网络之所以令人尴尬的并行,原因就在于此。我们使用神经网络进行的许多计算可以很容易地分解为较小的计算,使得一组较小的计算彼此不依赖。一个这样的例子是卷积。
卷积示例
让我们来看一个示例,卷积操作:
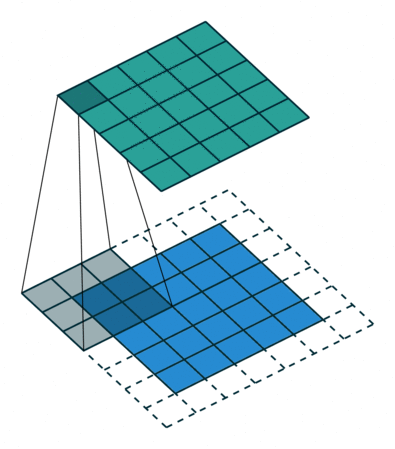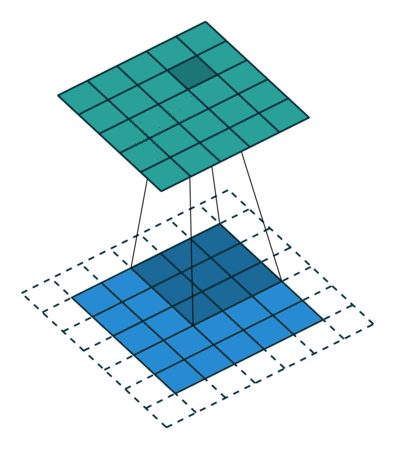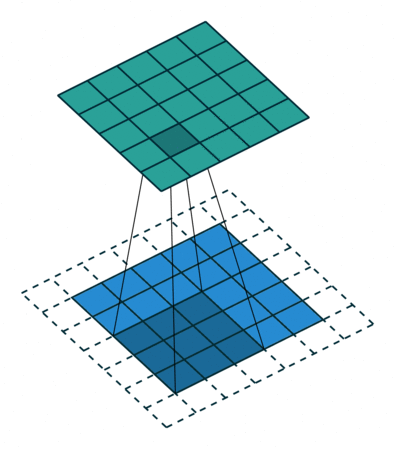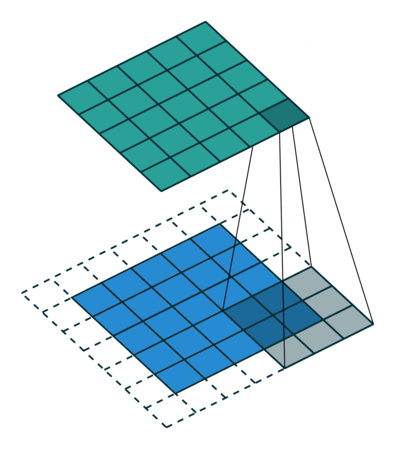
这个动画展示了没有数字的卷积过程。我们在底部有一个蓝色的输入通道。一个在底部阴影的卷积滤波器在输入通道上滑动,以及一个绿色的输出通道:
- 蓝色(底部) - 输入通道
- 阴影(在蓝色上方) -
3 x 3 卷积滤波器 - 绿色(顶部) - 输出通道
对于蓝色输入通道上的每个位置,3 x 3 滤波器都会进行一次计算,将蓝色输入通道的阴影部分映射到绿色输出通道的相应阴影部分。
在动画中,这些计算是依次一个接一个地进行的。然而,每次计算都与其他计算独立,这意味着没有计算依赖于其他任何计算的结果。
因此,所有这些独立的计算都可以在 GPU 上并行进行,并产生整体的输出通道。
这使我们能够看到,通过使用并行编程方法和 GPU,可以加速卷积操作。
Nvidia 硬件 (GPU) 和软件 (CUDA)
这就是 CUDA 发挥作用的地方。Nvidia 是一家设计 GPU 的技术公司,他们创建了 CUDA 作为一个软件平台,与他们的 GPU 硬件配合使用,使开发人员更容易构建利用 Nvidia GPU 并行处理能力加速计算的软件。

Nvidia GPU 是实现并行计算的硬件,而 CUDA 是为开发人员提供 API 的软件层。
因此,你可能已经猜到,要使用 CUDA,需要一个 Nvidia GPU,CUDA 可以从 Nvidia 的网站免费下载和安装。
开发人员通过下载 CUDA 工具包来使用 CUDA。工具包中包含专门的库,如 cuDNN,CUDA 深度神经网络库。

PyTorch 内置 CUDA
使用 PyTorch 或任何其他神经网络 API 的一个好处是并行性已经内置在 API 中。这意味着作为神经网络程序员,我们可以更多地专注于构建神经网络,而不是性能问题。
对于 PyTorch 来说,CUDA 从一开始就内置其中。不需要额外下载。我们只需要有一个支持的 Nvidia GPU,就可以使用 PyTorch 利用 CUDA。我们不需要直接了解如何使用 CUDA API。
当然,如果我们想在 PyTorch 核心开发团队工作或编写 PyTorch 扩展,那么直接了解如何使用 CUDA 可能会很有用。
毕竟,PyTorch 是用所有这些编写的:
- Python
- C++
- CUDA
在 PyTorch 中使用 CUDA
在 PyTorch 中利用 CUDA 非常容易。如果我们希望某个特定的计算在 GPU 上执行,我们可以通过在数据结构 (张量) 上调用 cuda() 来指示 PyTorch 这样做。
假设我们有以下代码:
> t = torch.tensor([1,2,3])
> t
tensor([1, 2, 3])以这种方式创建的张量对象默认在 CPU 上。因此,使用这个张量对象进行的任何操作都将在 CPU 上执行。
现在,要将张量移动到 GPU 上,我们只需编写:
> t = t.cuda()
> t
tensor([1, 2, 3], device='cuda:0')这种能力使 PyTorch 非常灵活,因为计算可以选择性地在 CPU 或 GPU 上执行。
GPU 可能比 CPU 慢
我们说我们可以选择性地在 GPU 或 CPU 上运行我们的计算,但为何不将 每个 计算都运行在 GPU 上呢?
GPU 不是比 CPU 快吗?
答案是 GPU 只对特定 (专门化) 任务更快。我们可能会遇到的一个问题是瓶颈,这会降低我们的性能。例如,将数据从 CPU 移动到 GPU 是代价高昂的,所以在这种情况下,如果计算任务很简单,整体性能可能会更慢。
将相对较小的计算任务移动到 GPU 上不会让我们加速很多,实际上可能会让我们变慢。记住,GPU 适合将任务分解为许多较小任务,如果计算任务已经很小,我们将不会通过将任务移动到 GPU 上获得太多好处。
因此,通常在刚开始时只使用 CPU 是可以接受的,随着我们解决更大更复杂的问题,开始更频繁地使用 GPU。
GPGPU 计算
起初,使用 GPU 加速的主要任务是计算机图形,因此得名图形处理单元,但在近年来,出现了许多其他种类的并行任务。我们已经看到的一个这样的任务是深度学习。
深度学习以及许多其他使用并行编程技术的科学计算任务,正在导致一种新的编程模型的出现,称为 GPGPU 或通用 GPU 计算。
GPGPU 计算现在更常见地仅称为 GPU 计算或加速计算,因为现在在 GPU 上执行各种任务变得越来越普遍。
Nvidia 在这个领域一直是先驱。Nvidia 的 CEO 黄仁勋很早就设想了 GPU 计算,这就是 CUDA 在大约十年前被创建的原因。
尽管 CUDA 已经存在很长时间了,但它现在才真正开始腾飞,Nvidia 直到目前为止在 CUDA 上的工作是 Nvidia 在深度学习 GPU 计算方面处于领先地位的原因。
当我们听到黄仁勋谈论 GPU 计算栈时,他指的是 GPU 作为底部的硬件,CUDA 作为 GPU 顶部的软件架构,最后是像 cuDNN 这样的库位于 CUDA 顶部。
这个 GPU 计算栈支持在芯片上进行通用计算能力,而芯片本身是非常专门化的。我们经常在计算机科学中看到像这样的栈,因为技术是分层构建的,就像神经网络一样。
位于 CUDA 和 cuDNN 顶部的是 PyTorch,这是我们将会工作的框架,最终支持顶部的应用程序。



















