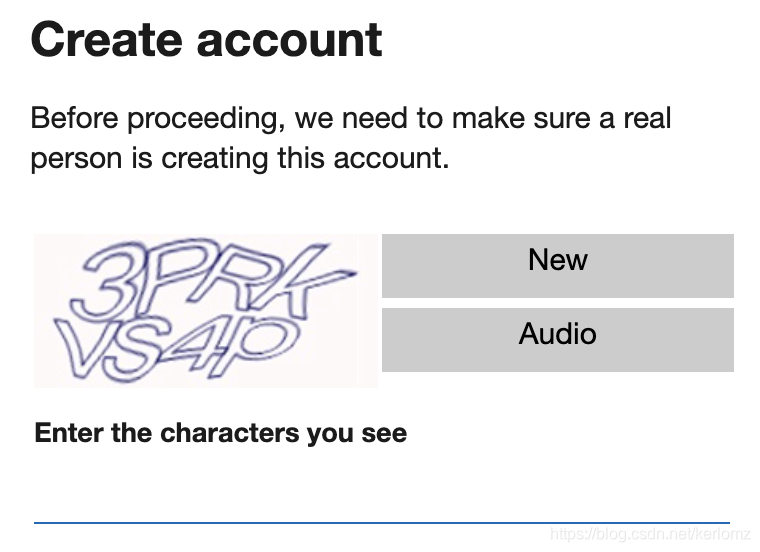
如图所示,微软Hotmail的验证码与我们往常所见的验证码略有不同,他是 【双层粘结】 的验证码,这对于我们识别有什么影响呢?
我们先来看CTC算法的TimeStep在语音识别中的表示:
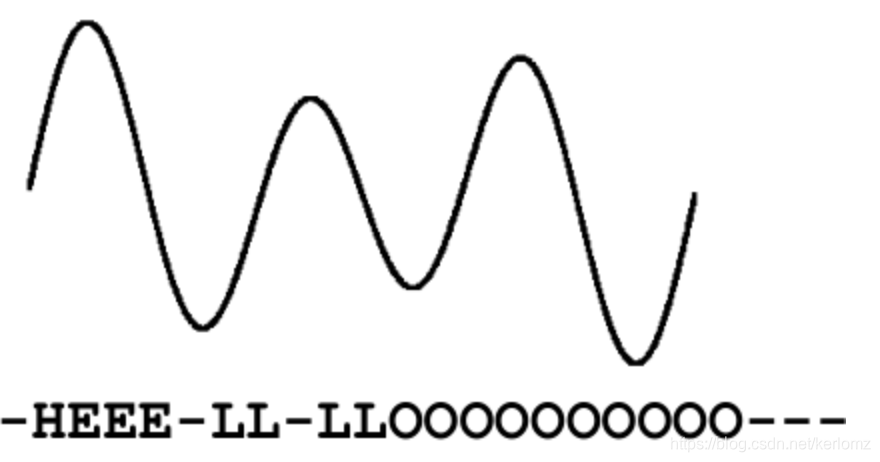
因为位数不固定,一般通过端到端做验证码识别的话会采用LSTM+CTC的方法,而根据上图所示,CTC的TimeStep对图像识别而言相当于水平方向的切片。

显而易见,无法同时识别多行文字内容,每一个时间片所对应的标签内容只能是一个,这导致了一般的训练法方法无法训练这种图示的验证码。那么该怎么训练呢?
解决方案:
我们经常看到验证码超过边界以外,即使只有一半,比如这样:

是否也不影响我们理解图片的内容?方法其实很简单,其实只要训练的时候对图片进行水平拼接就可以实现了,笔者使用的是github的captcha_trainer项目直接支持的水平拼接训练方法:

测试结果:
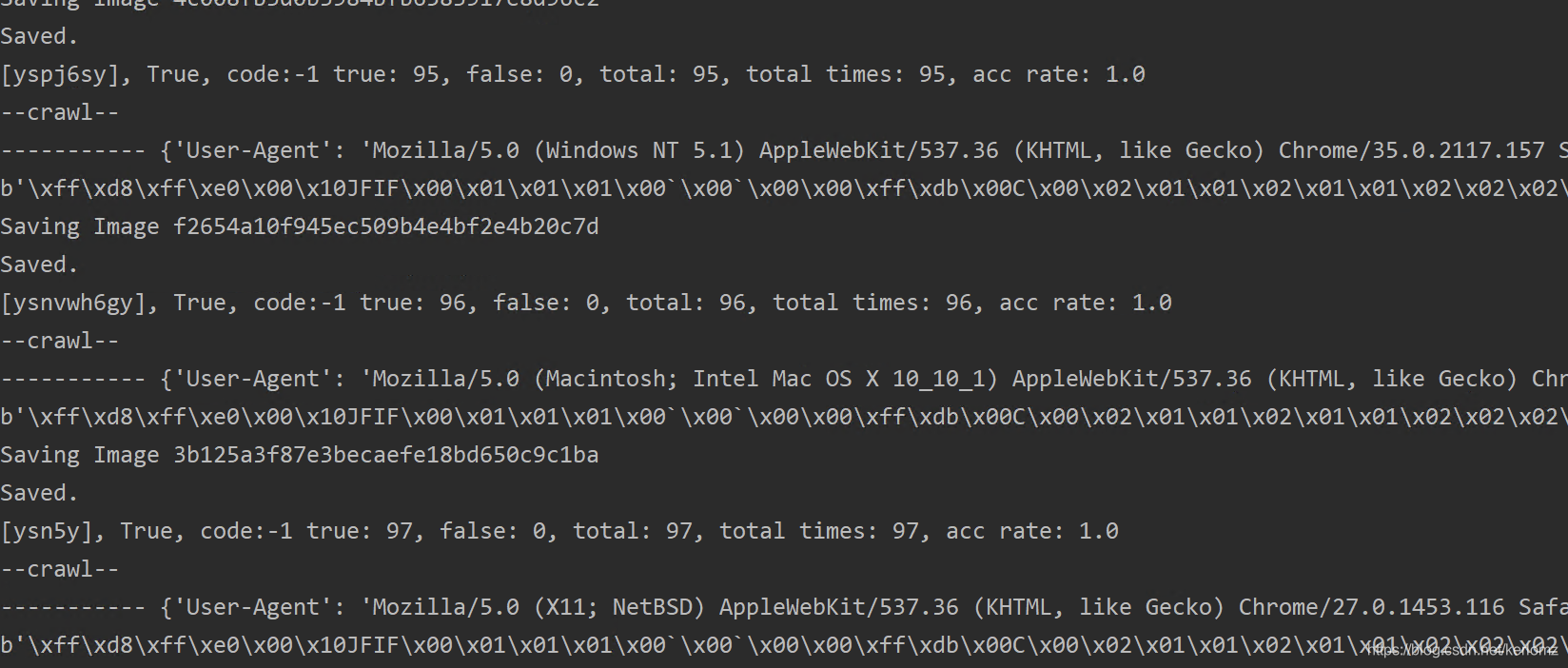

挂上一天测试大概有97%识别率。
对训练工具感兴趣的可以 github 搜索 captcha_trainer