一、问题由来
随着国标GB18030的推行,各行各业都在如火如荼的落实改造。自己在工作中也发现很多问题,查阅了很多资料都未解决自己的问题。经过慢慢摸索,对生僻字经常出现的问题进行总结,现分享如下。
二、问题描述
1. oracle存储不了生僻字。
2. 在PL/SQL Developer 中输入生僻字时,该生僻字无法正常显示。
3. pl/sql能录入能显示,通过jdbc不能显示。
4. jdbc能录入能显示,通过pl/sql不能显示。
三、原因
1.对于数据库而言,不区分什么生僻字,它仅仅是存储一堆的字节而已。能否存储生僻字主要是看以下几个方面:
a.数据库自身设置的字符集(该字符集会影响jdbc或odbc驱动与服务器的传输编码,不像mysql那样可以指定传输编码。这个没有找到相关资料辅佐,有兴趣可以抓包验证),这里面有两个关键的参数,一个是针对varchar2,一个是针对nvarchar2,这两个的区别可自行百度,资料比较多。

如图所示,我自己的数据库varchar2类型我设置的是AL32UTF8(all language 32位即4个字节 utf-8编码)。nvarchar2我也是用的utf-8。utf8和gbk的区别这儿也不做描述,百度资料很多。这儿可以看到我的数据库是大字符集的,能存储生僻字。
b.客户端的字符集,这个可通过环境变量或注册表等修改(环境变量名为NLS_LANG,不会修改可自行百度)。
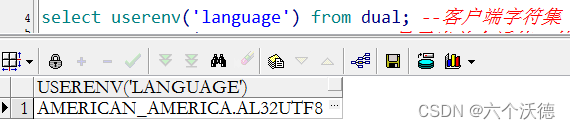
如图,我的客户端也是使用utf-8编码。网上的很多oracle显示中文乱码的问题差不多就到这儿了,确定了这两步差不多就可以解决中文乱码问题了。但是现在要说的是生僻字,为啥一会儿能显示一会儿又不能显示让人很迷惑,下面一一讲解。
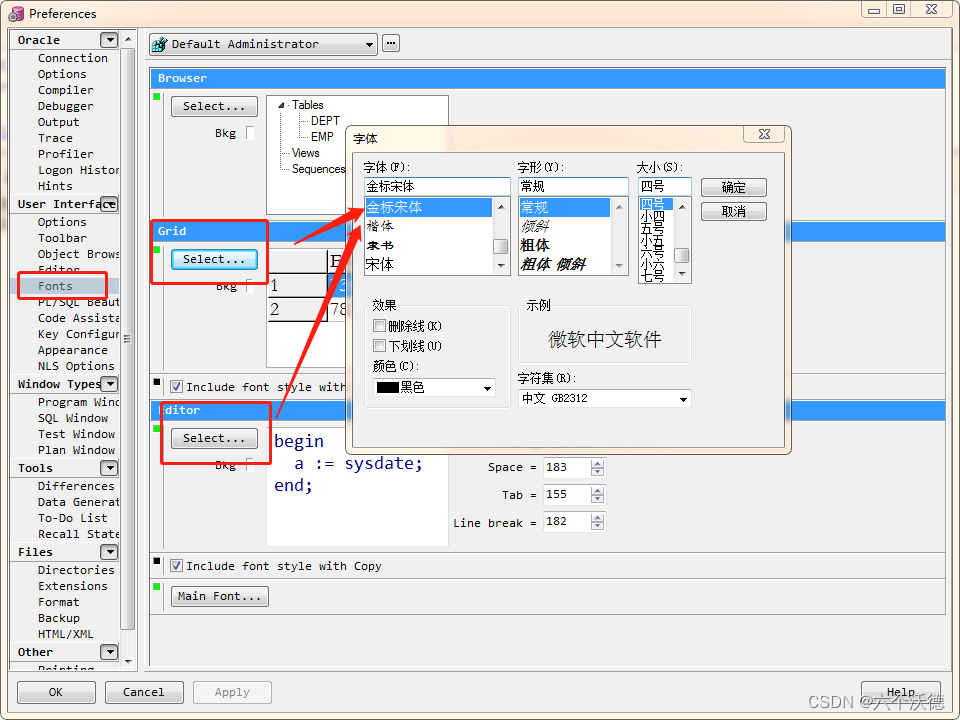
2.数据库能存储生僻字后,想着插入一个生僻字来做测试,但是pl/sql却不能显示该生僻字,这个原因首先取决于你有没有安装能显示相关生僻字的字库(目前市面的大多字库都不能显示生僻字),其次是pl/sql工具要选择生僻字的字库,这样在pl/sql的编辑界面和结果界面才能显示生僻字。
3.设计了一张varchar2字段的表,pl/sql能插入和显示生僻字,但是程序(jdbc或odbc)读取不到该字。该字“𫍣”为生僻字,没相关字库是显示不出来的。
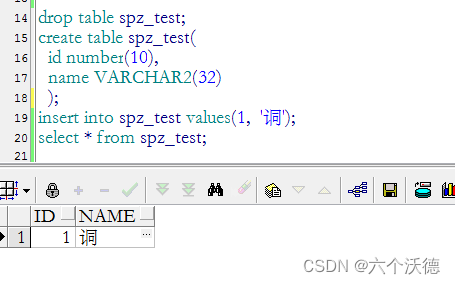
如图上,该字通过pl/sql能插入,也能显示,以为没有没有问题了,但是发现用程序读取时,却是无法解析,若是应用程序的话那就乱码了,例如我通过jdbc读取如下:
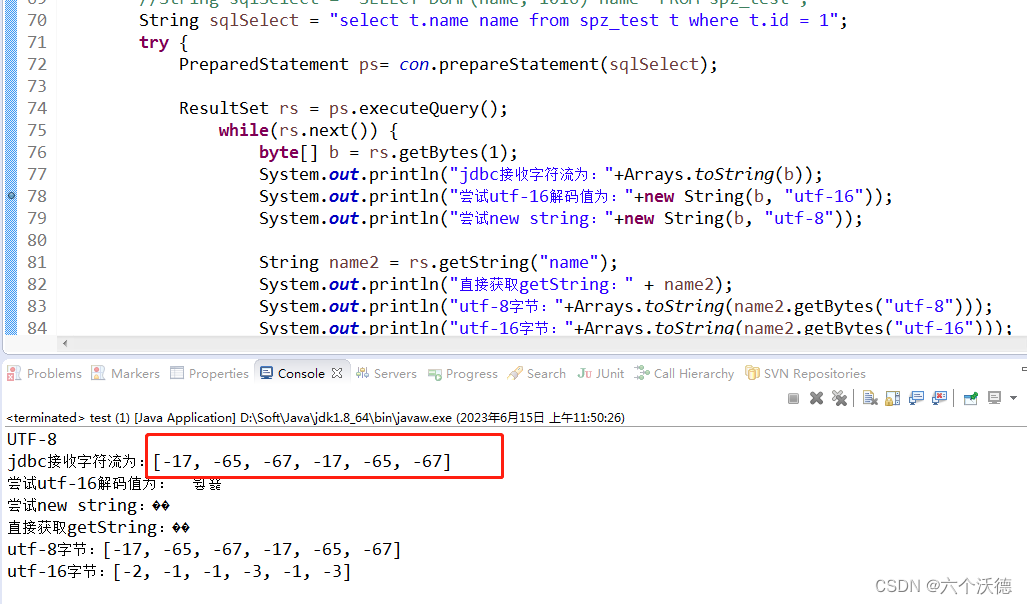
当看到-17,-65,-67这几个字符时, 条件反射想到这是转码有问题。在unicode编码里面,有几个特殊的码点可以记一下,对查问题时很有用。

其中字符�,码点为FFFD,utf-8编码为 EF,BF,BD,即-17,-65,-67。该特殊码点表示替换字符,当你给定一段字节信息,用UTF-8解码时,如果解码失败,就会把该字转换为�。那为啥会存在解码失败,原因就是你的字节信息不是UTF-8的编码,但你却用UTF-8解码,那当然就会失败。最常见的就是你的字节流是GBK的,但解码时用UTF-8,这样就会存在字符替换。如下图:
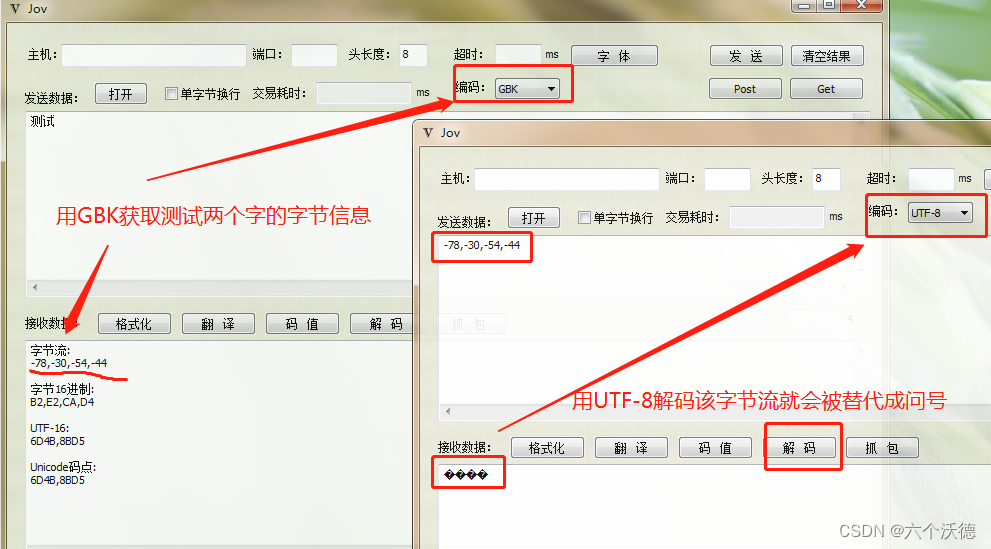
顺便一提,还有一个常见的字符显示错误还有一个:锟斤拷。这个又是怎么来的?同上面的道理,GBK转到UTF-8失败后,得到的是字符�,当有用该字符的字节信息通过GBK解码时,因为一个汉字只用两个字节,该字解出来就是我们看到的锟斤拷,如下图:
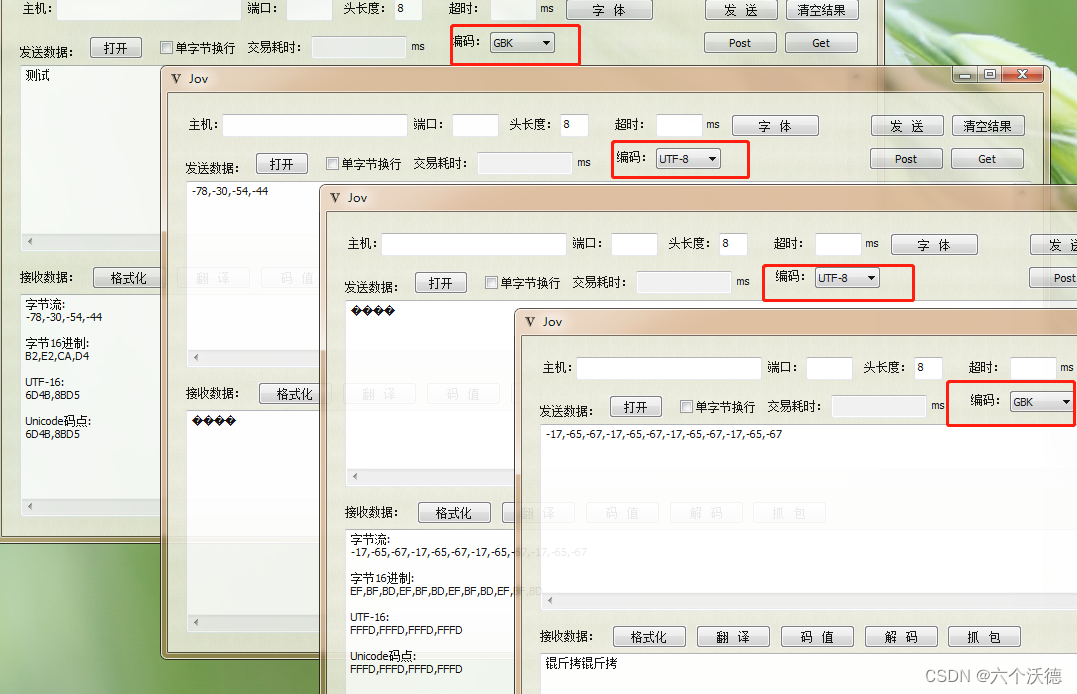
自此大家看到 �或者锟斤拷的时候,就知道是编码不一致问题,不用再好奇星号怎么来的。
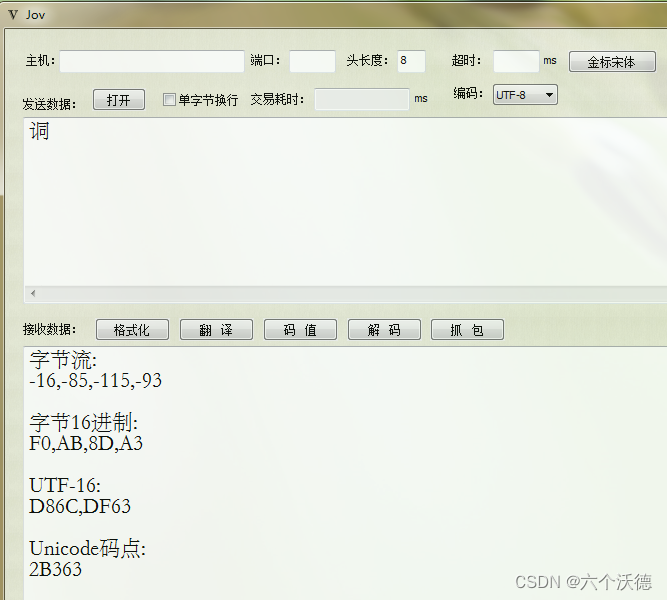
回到主题,为啥jdbc读到的是-17,-65,-67,是存储了错误的字节?还是传输时转码了字节流信息?所幸oracle提供了一个函数可以查看数据库存储的究竟是什么字节——dump函数,函数具体怎么使用还是自行百度,下面看一下数据库里面存储的究竟是啥。
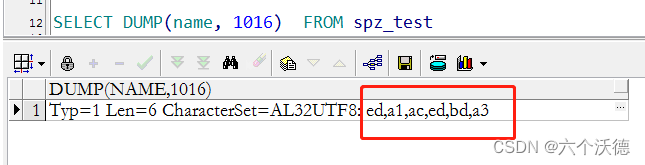
存储了6个字节,而我们数据库设置的字符集为utf8,这个生僻字utf8编码却是F0,AB,8D,A3这4个字节,显然差异不是一点半点。那数据库中存储的这个字节到底怎么来的?我们知道不管jdbc还是pl/sql等其他工具,最终和服务器通信就是网络包,而包里的内容若没加密就是一个个字节流(即使加密也是一个个字节,只是读不出来)而已,既然这样,直接抓包看看就知道了。抓包结果如下图:
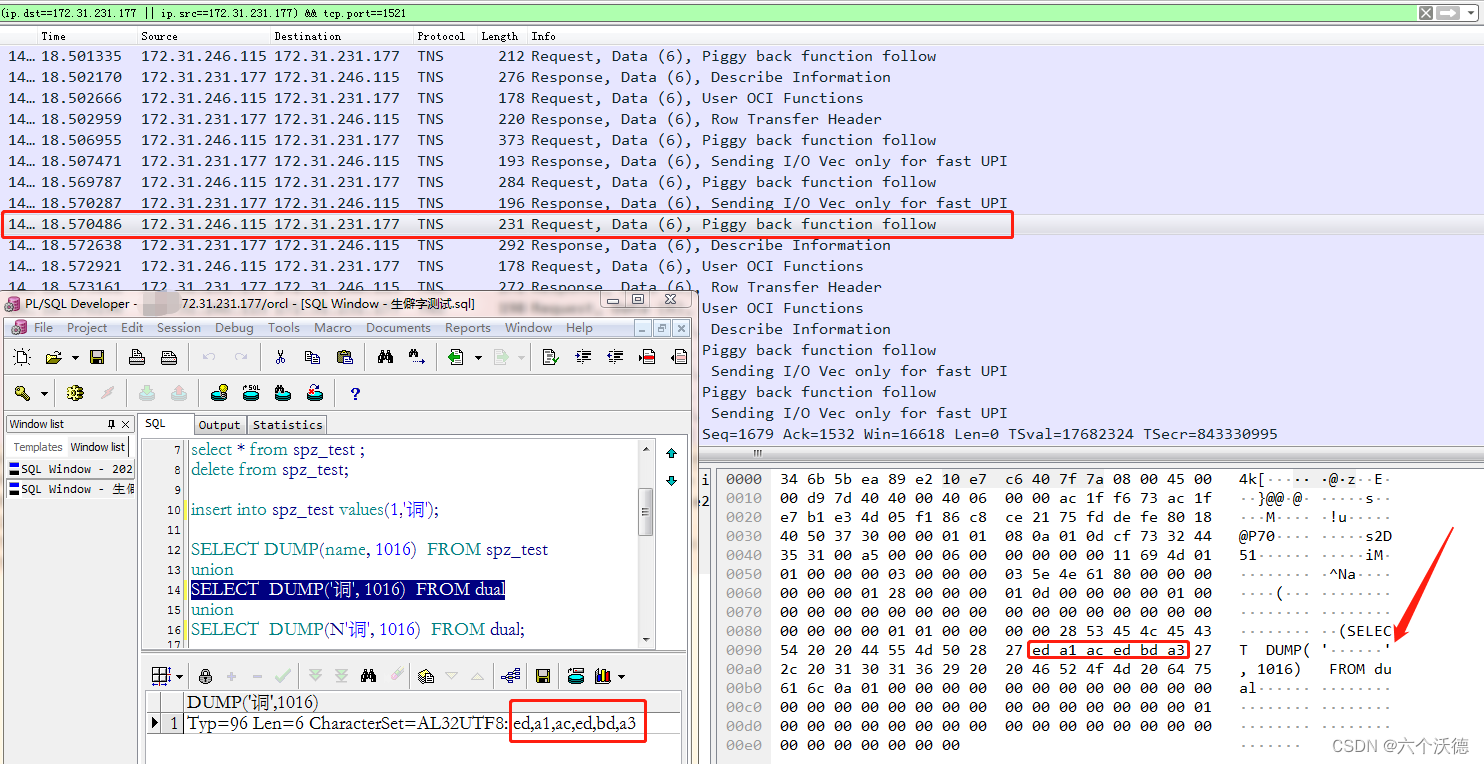
还好oracle的网络通讯没有加密,很容易就找到发送的包信息,从上图可以很清晰的看出oracle存储的字符集是由客户端获取的,而至于pl/sql客户端获取该字的utf8码为什么是一个6字节,这个就不清楚了,有知道原因的同学可以告知一下。猜测这个是系统开发环境有关(可以这么理解,如果你的工具支持unicode,那编码解码就是我们理解utf的规则,例如自己写的工具JOV,用的VS2013开发的,平台支持unicode,生僻字字符是用是4个字节表示,其实就是utf-16。而pl/sql,xshell等工具应该是不支持unicode,遇到生僻字这种会进行转码表示,不知道具体是什么规则,但肯定有东西在里面的,不然也不会获取到6个字节,正常的汉字获取的utf8编码大家都是一样的),从码值上看正常的utf8是F0,AB,8D,A3,pl/sql获取到的是ed,a1,ac,ed,bd,a3,可以看到最后一个字节始终是相同的,他们之间的转换规则有知道的可以告知一下。
到此可以理解为什么pl/sql能插入和显示生僻字,而其他jdbc获取到的却是乱码的问题了,根本原因是你用的工具能否支持unicode,虽然你的数据库字符集已经设置是utf8了,但真正存储的是你工具传给oracle的utf8的字节信息,你传入的是非主流的utf8(如上存入的ed,a1,ac,ed,bd,a3),别人肯定就读不出来(别人只认识F0,AB,8D,A3)。
同理,回答第四个问题,原因也是一样的,用你的程序(以java为例,java肯定支持unicode的,你获取utf8很容易getBytes("utf-8")就可以获得,该值获得的就是正常的字节信息)插入该生僻字后,数据库中存储的就是F0,AB,8D,A3,而pl/sql读取生僻字它有他的规则,它认识的是6个字节的那个,4个字节的它就不认识了,如下图:
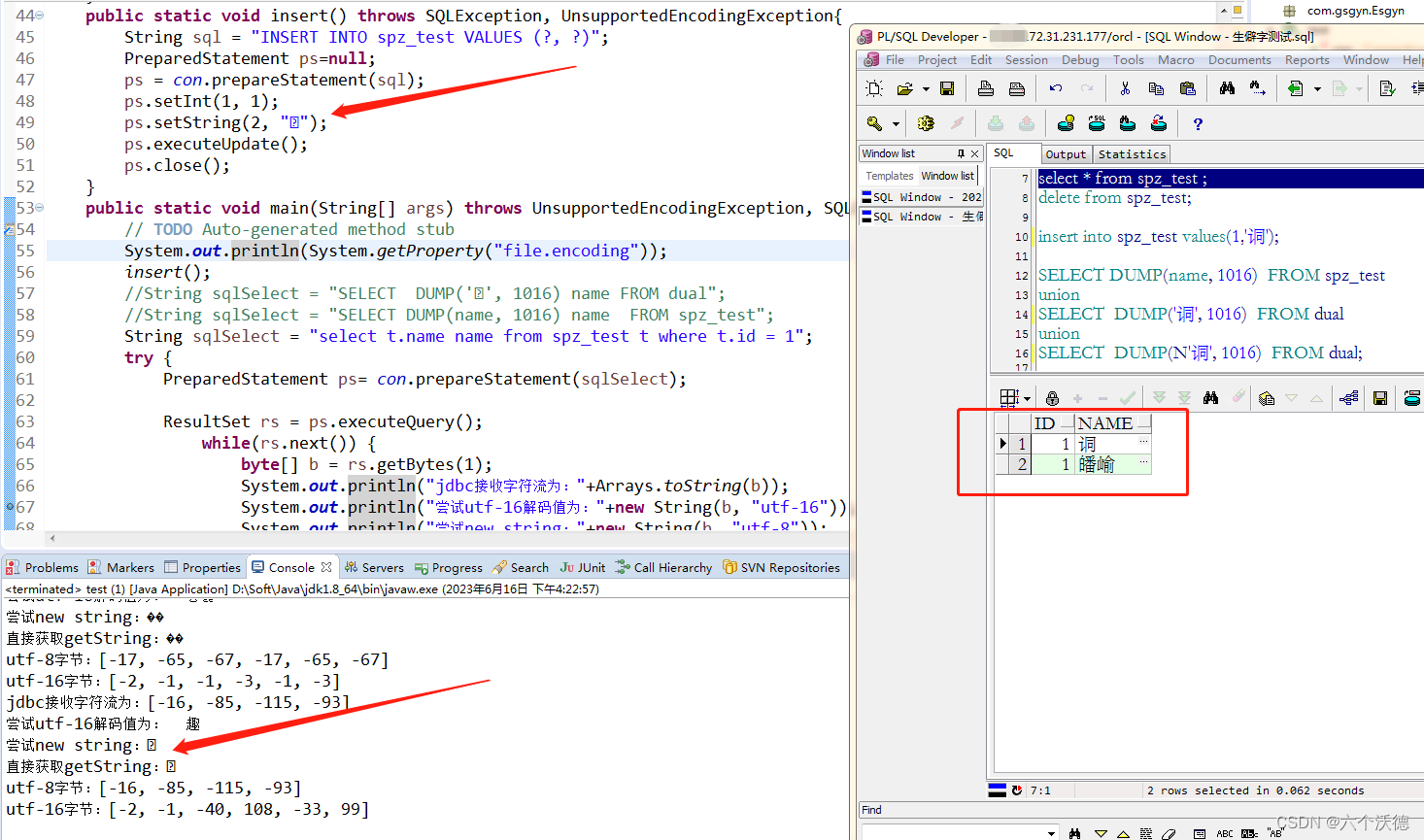
可以看到自己的程序插入和显示都正常,但是pl/sql工具却把它当两个汉字来处理了,很好理解嘛,因为oracle存储了4个字节(一般情况下gbk一个普通汉字占2个字节,一个普通汉字utf8占3个字节),两个汉字它就当gbk码处理了, 下图也可以验证。
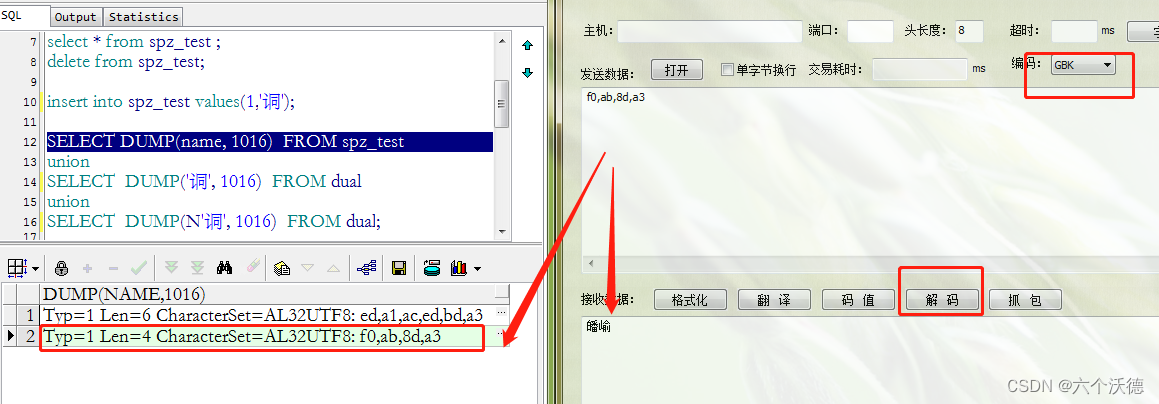
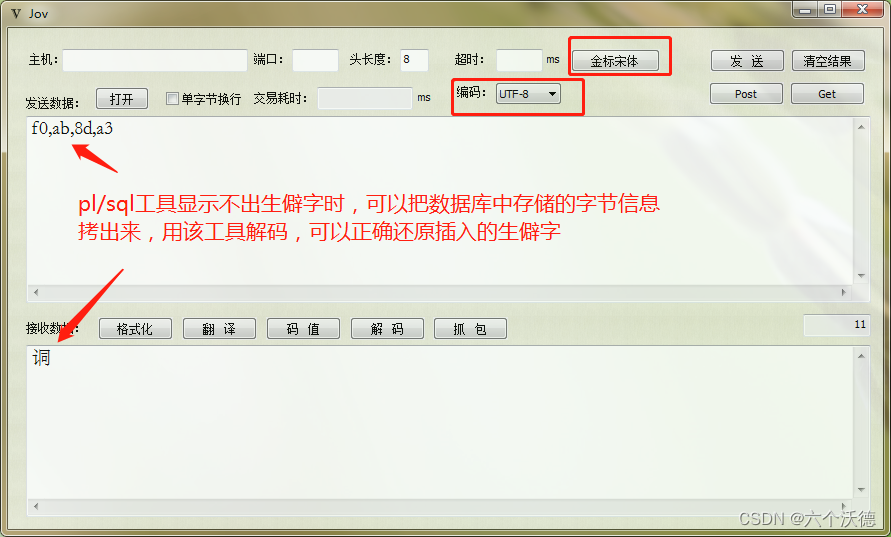
至此oracle生僻字不能显示或不能存储的问题差不多描述清楚了,也解释了为什么,还有不明白的就多读几遍吧。文章中使用的工具:pl/sql developer, wireshark, eclipse, jov。jov工具已开源,有兴趣的可以去之前的文章找,最新版也可以去下载。https://download.csdn.net/download/jerome_jun/87815045
还有一个问题,有人想我既想在pl/sql工具里面插入查看,又想应用程序能正确读取,那有办法吗?答案当然是肯定的,既然都知道了不能读取的原因,oracle如何存储信息,那当然可以解决。思路有两种:一是不改变现在的数据库字符集信息,自己写一个小工具提供插入和显示,需要支持更改字库,支持unicode编码,项目也不难,有兴趣的可以去写一个,没编程能力的当我白说。第二种方式是还记得上面提到的NVARCHAR2吗,这个设计本身就是针对这种字符集的情况,申请到的字符长度是多少就是多少,它也是可以设置字符集的,那究竟设置成啥呢?AL16UTF16了解一下,老规矩自行百度这个编码规则是啥。其实很多应用他们支持unicode码时,具体的表现形式用的就是UTF-16,像之前提到的VS2013和java,它的中文unicode码都是用utf-16存储的,优点缺点大家也可以自行去百度。回到主题,当你的NVARCHAR2设置为AL16UTF16后,你会发现ps/sql工具获取的utf-16编码和其他工具都一样了,大家存储的字节信息都一致了,这样大家就能正常访问了。那你可能会问varchar2直接设置成AL16UTF16好了嘛,不同工具不是都可以插入、修改、查询了嘛,很会举一反三,要是地主家儿子你是可以这么干的,这个问题嘛可以看看chatGPT怎么回答的:

整个排查问题分享得差不多了,有不恰当之处欢迎指导。