目录
python下载方法:
设置环境变量
~/.bashrc
缓存目录,默认模型下载目录
安装方法:
python 下载无token:
python 下载带token
常见报错
登录后创建Read token
2.3 创建token
使用token登录
python下载方法:
设置环境变量
Linux
export HF_ENDPOINT=https://hf-mirror.com~/.bashrc
export HUGGINGFACE_HUB_CACHE=/mnt/xxx/huggingface/
export HF_DATASETS_CACHE=/xxx/huggingface/export TRANSFORMERS_CACHE=/mnt/xxx/huggingface/
export TORCH_HOME=/mnt/pfs/models/torch/
export PIP_CACHE_DIR=/mnt/xxx/cache/
export HF_ENDPOINT=https://hf-mirror.com缓存目录,默认模型下载目录
~/.cache/huggingface
Windows Powershell
$env:HF_ENDPOINT = "https://hf-mirror.com"下载脚本:
huggingface-cli download --resume-download jianzongwu/lgvi-i --local-dir ckpt
安装方法:
pip install -U huggingface_hub
huggingface-cli download --h
$env:HF_ENDPOINT = "https://hf-mirror.com"
huggingface-cli download --resume-download gpt2--local-dir gpt2
python 下载无token:
报错,和浏览器的一样,401错误
# 设置环境变量
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"# 代码下载
from huggingface_hub import hf_hub_download
hf_hub_download(repo_id="black-forest-labs/FLUX.1-dev" ,filename="model_index.json" ,local_dir="./qafacteval")python 下载带token
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"from huggingface_hub import snapshot_downloadlocal_dir = r"B:\data\aigc1"
repo_id = "black-forest-labs/FLUX.1-dev"
token = "xxxxxx"snapshot_download(repo_id=repo_id, local_dir=local_dir, resume_download=True, local_dir_use_symlinks=False, token=token)# 没成功:
# from huggingface_hub import hf_hub_download
# hf_hub_download(repo_id="black-forest-labs/FLUX.1-dev" ,filename="model_index.json" ,local_dir="./qafacteval")常见报错
- huggingface-cli: error: invalid choice: ‘download’ (choose from ‘env’, ‘login’, ‘whoami’, ‘logout’, ‘repo’, ‘lfs-enable-largefiles’, ‘lfs-multipart-upload’, ‘scan-cache’, ‘delete-cache’)
- 可能是由于python版本<3.8,下载的huggingface-cli版本过低;在python>=3.8环境下运行
pip install -U huggingface_hub命令后解决
- 可能是由于python版本<3.8,下载的huggingface-cli版本过低;在python>=3.8环境下运行
- ModuleNotFoundError: No module named ‘chardet’
- 安装对应模块即可:
pip install chardet
- 安装对应模块即可:
annot instantiate this tokenizer from a slow version. If it's based on sentencepiece, make sure you have sentencepiece installed.
解决方法:
pip install transformers[sentencepiece]
登录后创建Read token
- 点击提交后,会有提示settings中会有消息。Settings页面如下图操作就可以找到。
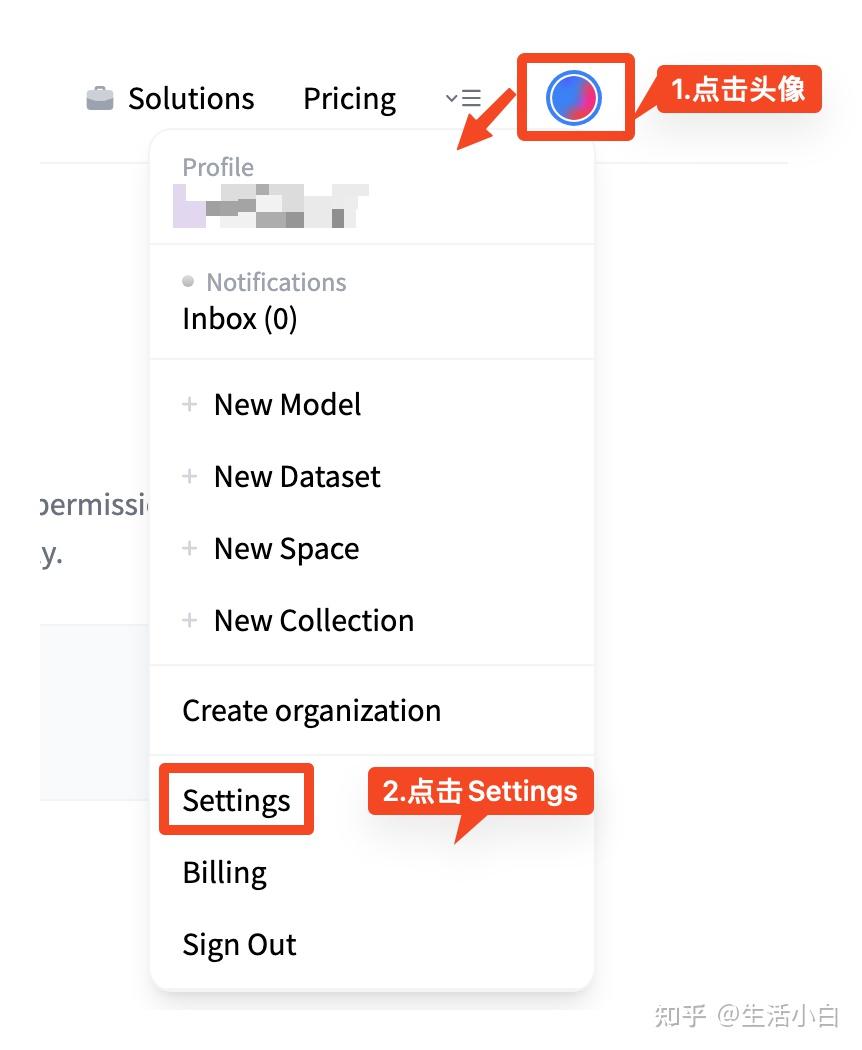
Settings页面查找方式
2.3 创建token
- 当注册账号的邮箱收到邮件后,可以进入Settings页面,按照如下图操作。
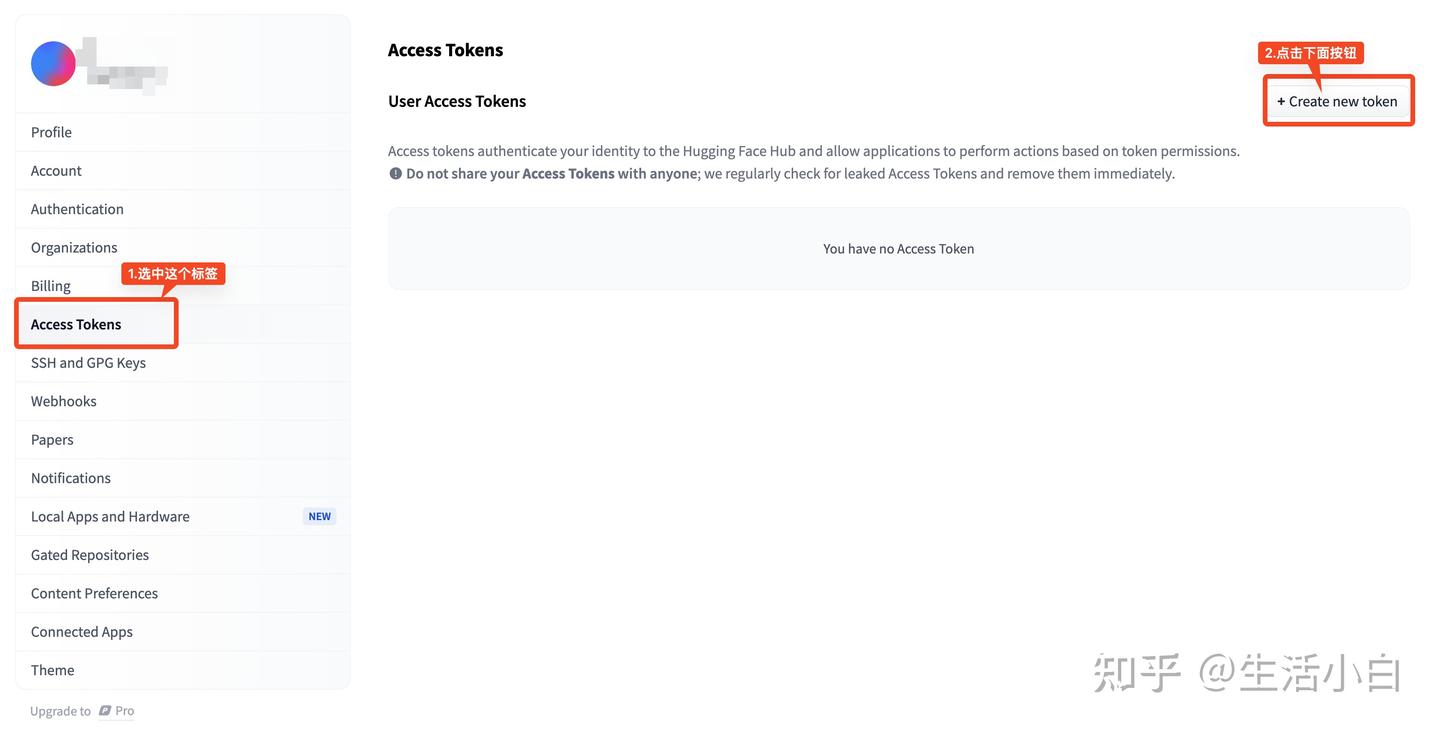
Access token页面
- 点击【Create new token】后,最先遇到的就是token type的选择了。页面列举了三类,需要根据自己的使用场景进行选择。
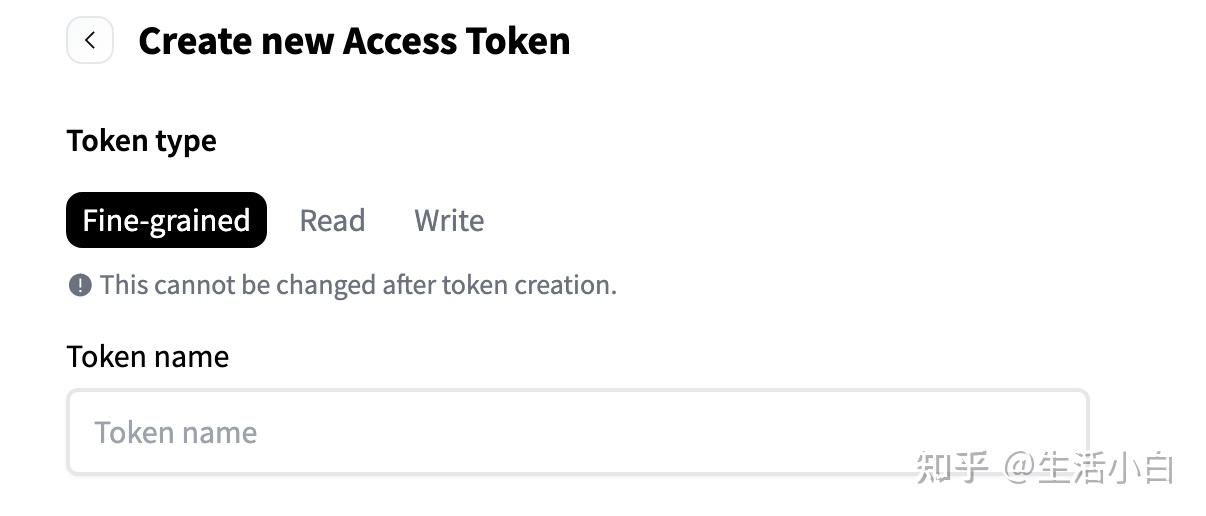
创建新的token
三种Token类型的权限:
Fine-grained:
适用场景: 允许特定操作(如读取、写入或微调),则可以选择“Fine-grained”权限。这种类型适合需要精细管理访问权限的用户,特别是在团队协作或项目中。
Read:
适用场景: 如果您只需要访问模型进行推理或下载模型,而不打算进行任何修改或训练,选择“Read”权限即可。
Write:
适用场景: 如果您打算对模型进行修改、上传新的模型权重或更新现有模型,则需要选择“Write”权限。这通常适用于开发者或研究人员,他们需要将自己的工作成果上传到Hugging Face平台。
使用token登录
huggingface-cli login
会提示输入 token,鼠标右键后,回车。
然后提示输入y,没报错就可以下载了。