1.如何对系统的OOM异常进行监控和报警
(1)最佳的解决方案
最佳的OOM监控方案就是:建立一套监控平台,比如搭建Zabbix、Open-Falcon之类的监控平台。如果有监控平台,就可以接入系统异常的监控和报警,可以设置当系统出现OOM异常,就发送报警给对应的开发人员。这是中大型公司里最常用的一种方案。
监控平台一般会监控系统的如下几个层面:
一.机器资源(CPU、磁盘、内存、网络)的负载
二.JVM的GC频率和内存使用率
三.系统自身的业务指标
四.系统的异常报错
(2)搭建系统监控体系的建议
建议一:对机器指标进行监控
一.首先可以看到机器的资源负载情况
比如CPU负载,可以看到现在CPU目前的使用率有多高。比如磁盘IO负载,包括磁盘上发生了多少数据量的IO、一些IO耗时等。当然一般业务系统不会直接读写本地磁盘,最多就是写一些本地日志。但是一般业务系统也应该关注本地磁盘的使用量和剩余空间,因为有的系统可能会因为一些代码bug,导致一直往本地磁盘写东西。万一把磁盘空间写满了就麻烦了,磁盘满了也会导致系统无法运行。
二.其次可以看到机器的内存使用量
这个是从机器整体层面去看的,看看机器对内存使用的一些变化。当然内存这块,比较核心的还是JVM的监控,通过监控平台可以看到JVM各个内存区域的使用量的变化的。
三.还有一个比较关键的是JVM的FGC频率
一般会监控一段时间内的FGC次数,比如5分钟内发生了几次FGC。
四.最后就是机器上的网络负载
就是通过网络IO读写了多少数据、一些耗时等。
其实线上机器最容易出问题的主要有三方面:
一是CPU(必须要监控CPU的使用率),如果CPU负载过高(如长期超过90%)就报警。
二是内存(必须要监控内存的使用率),如果机器内存使用率超过一定阈值(如超90%)则可能内存不够。
三是JVM的FGC频率,假设5分钟内发生了10次FGC,那一定是频繁FGC了。
建议二:对业务指标进行监控
另外比较常见的就是对系统的业务指标进行监控。比如在系统每创建一个订单时就上报一次监控,然后监控系统会收集1分钟内的订单数量。这样就可以设定一个阈值,比如1分内要是订单数超过100就报警。因为订单过多可能涉及一些刷单行为,这就是业务指标监控。
建议三:对系统异常进行监控
最后就是对系统中所有的try catch异常报错,都接入报警。一旦发现有try catch异常,就上报到监控平台。然后监控平台就能通告这次异常,让相关负责人收到报警。比如一旦发现有OOM异常,就能马上通知相关开发人员。
2.如何在JVM内存溢出时自动dump内存快照
(1)解决OOM问题的一个初步思路
如果发生OOM,则说明系统中某个区域的对象太多,塞满了那个区域。而且一定是无法回收掉区域中的那些对象,最终才会导致内存溢出。
要解决OOM,首先得知道是什么对象太多了,从而最终导致OOM的。所以必须有一份JVM发生OOM时的dump内存快照,只要有了那个dump内存快照,就可以用MAT工具分析什么对象太多了。
那么现在一个关键问题来了:到底怎么做才可以在JVM内存溢出时自动dump出一份内存快照呢?
(2)在OOM时自动dump内存快照
如果JVM发生OOM,JVM是不是完全来不及处理然后突然进程就没了?也就是JVM是不是非常突然的、自己都无法控制,就挂掉了?
其实不是的,JVM在发生OOM之前会尽可能进行GC腾出一些内存空间。如果GC后还是没有空间,放不下对象, 才会触发内存溢出。所以JVM自己对OOM情况的发生是完全有把控权的。
JVM知道什么时候会触发OOM,它是在无法放下对象的时候才会触发的。因此OOM的发生并不是突然内存太多,连JVM自己都没反应过来就崩溃。
JVM如果知道自己将要发生OOM了,那么此时完全可以让它做点事情。比如可以让JVM在OOM时dump一份内存快照,事后只要分析这个内存快照,就可以知道是哪些对象导致OOM的了。为此,需要在JVM的启动参数中加入如下参数:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/app/oom第一个参数的意思是:在OOM时自动进行dump内存快照。第二个参数的意思是:把内存快照放到哪里。只要加入了这两个参数,可以事后再获取OOM时的内存快照进行分析。
(3)一份比较全面的JVM参数模板
-Xms4096M -Xmx4096M -Xmn3072M -Xss1M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M-XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFaction=92 -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSParallelInitialMarkEnabled -XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -XX:+PrintGCDetails -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/app/oom这份JVM参数模板基本上涵盖了所有需要的一些参数。首先是各个内存区域的大小分配,这个需要精心调优的。其次是两种垃圾回收器的指定。接着是一些常规的CMS垃圾回收参数,可优化偶尔发生的FGC性能。最重要的,就是平时要打印出GC日志。GC日志可以配合jstat工具分析GC频率和性能的时候使用。jstat可分析出GC频率,但每次具体的GC情况则要结合GC日志来看。还有次重要的,就是发生OOM时能自动dump内存快照。这样即使突然发生OOM,且事后才知道,都可以分析当时的内存快照。
3.Metaspace区域内存溢出时应如何解决(OutOfMemoryError: Metaspace)
(1)解决思路
面对Metaspace区域内存溢出,思路如下:首先分析GC日志,然后再让JVM自动dump出内存快照。最后用MAT来分析这份内存快照,从内存快照里寻找OOM的原因。
(2)示例代码
public class Demo1 {public static void main(String[] args) {long counter = 0;while (true) {Enhancer enhancer = new Enhancer();enhancer.setSuperclass(Car.class);enhancer.setUseCache(false);enhancer.setCallback(new MethodInterceptor() {@Overridepublic Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {if (method.getName().equals("run")) {System.out.println("Check before run");return methodProxy.invokeSuper(o, objects);} else {return methodProxy.invokeSuper(o, objects);}}});Car car = (Car) enhancer.create();car.run();System.out.println("目前创建了" + (++counter) + "个Car类的子类了");}}static class Car {public void run() {System.out.println("Run...");}}static class SafeCar extends Car {@Overridepublic void run() {System.out.println("Safe Run...");super.run();}}
}接着JVM参数修改为如下,因为我们想看一下GC日志和导出内存快照。
-XX:+UseParNewGC-XX:+UseConcMarkSweepGC-XX:MetaspaceSize=10m-XX:MaxMetaspaceSize=10m-XX:+PrintGCDetails-Xloggc:gc.log-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=./注意,上面那个HeapDumpPath参数调整为当前项目下,这样方便查看。
(3)分析GC日志
接下来用上述JVM参数运行这段程序,会发现项目下多了两个文件:一个是gc.log,一个是java_pid910.hprof。当然不同的机器运行这个程序,导出的hprof文件的名字是不太一样的,因为hprof文件会用PID进程id作为文件名字。
步骤一:首先分析gc.log
分析它是如何不断往Metaspace区放入大量生成的类,然后触发FGC的。接着回收Metaspace区,回收后还是无法放下更多类,才抛出OOM。
步骤二:然后用MAT分析OOM时的内存快照
也就是使用MAT工具找到Metaspace内存溢出问题的原因,GC日志如下:
CommandLine flags: -XX:CompressedClassSpaceSize=2097152 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./ -XX:InitialHeapSize=268435456 -XX:MaxHeapSize=4294967296 -XX:MaxMetaspaceSize=10485760 -XX:MaxNewSize=348966912 -XX:MaxTenuringThreshold=6 -XX:MetaspaceSize=10485760 -XX:OldPLABSize=16 -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
0.716: [GC (Allocation Failure) 0.717: [ParNew: 139776K->2677K(157248K), 0.0038770 secs] 139776K->2677K(506816K), 0.0041376 secs] [Times: user=0.03 sys=0.01, real=0.00 secs]
0.771: [Full GC (Metadata GC Threshold) 0.771: [CMS: 0K->2161K(349568K), 0.0721349 secs] 20290K->2161K(506816K), [Metaspace: 9201K->9201K(1058816K)], 0.0722612 secs] [Times: user=0.12 sys=0.03, real=0.08 secs]
0.843: [Full GC (Last ditch collection) 0.843: [CMS: 2161K->1217K(349568K), 0.0164047 secs] 2161K->1217K(506944K), [Metaspace: 9201K->9201K(1058816K)], 0.0165055 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
0.860: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1217K(349568K)] 1217K(506944K), 0.0002251 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.860: [CMS-concurrent-mark-start]
0.878: [CMS-concurrent-mark: 0.003/0.018 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
0.878: [CMS-concurrent-preclean-start]
Heappar new generation total 157376K, used 6183K [0x00000005ffe00000, 0x000000060a8c0000, 0x0000000643790000)eden space 139904K, 4% used [0x00000005ffe00000, 0x0000000600409d48, 0x00000006086a0000)from space 17472K, 0% used [0x00000006086a0000, 0x00000006086a0000, 0x00000006097b0000)to space 17472K, 0% used [0x00000006097b0000, 0x00000006097b0000, 0x000000060a8c0000)concurrent mark-sweep generation total 349568K, used 1217K [0x0000000643790000, 0x0000000658cf0000, 0x00000007ffe00000)
Metaspace used 9229K, capacity 10146K, committed 10240K, reserved 1058816Kclass space used 794K, capacity 841K, committed 896K, reserved 1048576K一.第一行GC日志如下
0.716: [GC (Allocation Failure) 0.717: [ParNew: 139776K->2677K(157248K), 0.0038770 secs] 139776K->2677K(506816K), 0.0041376 secs] [Times: user=0.03 sys=0.01, real=0.00 secs]这行日志,这是第一次GC,它本身是一个Allocation Failure的问题。也就是说,在Eden区中分配对象时,已经发现Eden区内存不足了,于是就触发了一次YGC。
二.那么这个对象到底是什么对象
回到代码中,可知Enhancer是一个对象,它是用来生成类的,如下所示:
Enhancer enhancer = new Enhancer();接着会基于new Enhancer生成类对象来生成那个子类的对象,如下所示:
Car car = (Car) enhancer.create();上述代码会在while(true)里不停创建Enhancer对象和Car的子类对象,因此Eden区慢慢就会被占满了,于是会看到上述日志:
[ParNew: 139776K->2677K(157248K), 0.0038770 secs] 这行日志就是说:在默认的内存分配策略下,新生代一共可用空间是150M左右。然后大概用到140M,Eden区都占满了,就会触发Allocation Failure。即没有Eden区的空间去分配对象了,此时就只能触发YGC。
三.接着来看如下GC日志
0.771: [Full GC (Metadata GC Threshold) 0.771: [CMS: 0K->2161K(349568K), 0.0721349 secs] 20290K->2161K(506816K), [Metaspace: 9201K->9201K(1058816K)], 0.0722612 secs] [Times: user=0.12 sys=0.03, real=0.08 secs]这行日志说明就是发生FGC了,而且通过Metadata GC Threshold清晰看到,是Metaspace区域满了,这时看后面的日志:
20290K->2161K(506816K);这就是说堆内存(新生代+老年代)一共是500M,有20M被使用了,这20M的内存是被新生代使用的。
然后FGC必然会带着一次YGC,因此这次FGC执行了YGC,所以回收了很多对象,剩下2161K的对象,这2161K的对象大概就是JVM的一些内置对象。
然后直接就把这些对象都放入老年代,为什么呢?因为后面的日志:
[CMS: 0K->2161K(349568K), 0.0721349 secs]明显表明,FGC带着CMS进行了老年代的Old GC,结果人家本来是0K。然后从新生代转移来了2161K的对象,所以老年代变成2161K了。
接着看日志:
[Metaspace: 9201K->9201K(1058816K)]这说明此时Metaspace区域已经使用了差不多9M左右的内存了。JVM发现离限制的10M内存很接近了,于是触发了FGC。但是对Metaspace进行GC后发现类的对象全部都还存活,因此还是剩余9M左右的类在Metaspace里。
四.接着来看下一行GC日志
0.843: [Full GC (Last ditch collection) 0.843: [CMS: 2161K->1217K(349568K), 0.0164047 secs] 2161K->1217K(506944K), [Metaspace: 9201K->9201K(1058816K)], 0.0165055 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]接着又是一次FGC。其中的Last ditch collection,说明这是最后一次拯救的机会了。因为之前Metaspace回收了一次但发现没有类可以回收,所以新的类无法放入Metaspace了。因此才再最后试一试FGC,看看能不能回收掉一些。
结果发现还是:
[Metaspace: 9201K->9201K(1058816K)], 0.0165055 secs]这说明Metaspace区域还是无法回收掉任何类,Metaspace区几乎还是占满了设置的10M内存。
五.继续看如下GC日志
0.860: [GC (CMS Initial Mark) [1 CMS-initial-mark: 1217K(349568K)] 1217K(506944K), 0.0002251 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.860: [CMS-concurrent-mark-start]
0.878: [CMS-concurrent-mark: 0.003/0.018 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
0.878: [CMS-concurrent-preclean-start]
Heappar new generation total 157376K, used 6183K [0x00000005ffe00000, 0x000000060a8c0000, 0x0000000643790000)eden space 139904K, 4% used [0x00000005ffe00000, 0x0000000600409d48, 0x00000006086a0000)from space 17472K, 0% used [0x00000006086a0000, 0x00000006086a0000, 0x00000006097b0000)to space 17472K, 0% used [0x00000006097b0000, 0x00000006097b0000, 0x000000060a8c0000)concurrent mark-sweep generation total 349568K, used 1217K [0x0000000643790000, 0x0000000658cf0000, 0x00000007ffe00000)
Metaspace used 9229K, capacity 10146K, committed 10240K, reserved 1058816Kclass space used 794K, capacity 841K, committed 896K, reserved 1048576K接着JVM就直接退出了,退出的时候打印了当前内存的一个情况:年轻代和老年代几乎没占用。但是Metaspace的capacity是10M,使用了9M左右。无法再继续使用了,所以触发了内存溢出。
此时在控制台会打印出如下的信息:
Caused by: java.lang.OutOfMemoryError: Metaspaceat java.lang.ClassLoader.defineClass1(Native Method)at java.lang.ClassLoader.defineClass(ClassLoader.java:763)... 11 more明确抛出异常表明OutOfMemoryError,原因就是Metaspace区域满了。
因此可以假设是Metaspace内存溢出了,然后我们自己监控到了异常。此时直接去线上机器看一下GC日志和异常信息。通过上述分析就能知道系统是如何运行、触发几次GC后引发内存溢出。
(4)分析内存快照
当我们知道是Metaspace引发的内存溢出后:就把内存快照文件从线上机器拷回本地电脑,打开MAT工具进行分析。如下图示:

从上图可以看到实例最多的就是AppClassLoader。为什么会有这么多的ClassLoader呢?一看就是CGLIB之类的东西在动态生成类的时候搞出来的,此时我们可以点击上图的Details进去看看。

为什么有一大堆在Demo1中动态生成的Car$$EnhancerByCGLIB类?看到截图中的Object数组里出现的很多这种类,就已经很清晰说明了:某个类生成了大量动态类EnhancerByCGLIB,填满了Metaspace区。所以此时直接去代码里排查动态生成类的代码即可。
解决这个问题的办法也很简单:对Enhancer进行缓存,只需要一个Enhancer实例即可,不需要无限制地生成类。
4.JVM栈内存溢出时应如何解决(StackOverflowError)
(1)栈内存溢出能否按照之前的方法解决
也就是说,GC日志、内存快照,这些东西对解决栈内存溢出有帮助吗?其实栈内存溢出跟堆内存是没有关系的,因为它的本质是一个线程的栈中压入了过多调用方法的栈桢。比如调用了几千次方法就会压入几千个方法栈桢,此时就会导致线程的栈内存不足,无法放入更多栈桢。
GC日志对栈内存溢出是没有用的,因为GC日志主要分析的是堆内存和Metaspace区域的一些GC情况。就线程的栈内存和栈桢而言,不存在所谓的GC。
线程调用一个方法时,会在线程的虚拟机栈里压入方法栈桢。接着线程执行完该方法后,方法栈桢会从线程的虚拟机栈里出栈。最后一个线程运行完毕时,它的虚拟机栈内存就会被释放。
所以本身栈内存不存在所谓的GC和回收。线程调用方法时就会给方法栈桢分配内存,线程执行完方法时就会回收掉那个方法栈桢的内存。
内存快照是分析内存占用的,同样是针对堆内存和Metaspace的。所以对线程的栈内存而言,也不需要使用内存快照。
(2)代码示例
public class Demo2 {public static long counter = 0;public static void main(String[] args) {work();}public static void work() {System.out.println("目前是第" + (++counter) + "次调用方法");work();}
}使用的JVM参数如下:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC-XX:ThreadStackSize=1m -XX:+PrintGCDetails -Xloggc:gc.log-XX:+HeapDumpOnOutOfMemoryError-XX:HeapDumpPath=./(3)运行代码后分析异常报错信息的调用栈
接着运行代码产生栈内存溢出,如下:
目前是第5549次调用方法
java.lang.StackOverflowErrorat java.io.FileOutputStream.write(FileOutputStream.java:326)at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140)at java.io.PrintStream.write(PrintStream.java:482)at sun.nio.cs.StreamEncoder.writeBytes(StreamEncoder.java:221)at sun.nio.cs.StreamEncoder.implFlushBuffer(StreamEncoder.java:291)at sun.nio.cs.StreamEncoder.flushBuffer(StreamEncoder.java:104)at java.io.OutputStreamWriter.flushBuffer(OutputStreamWriter.java:185)at java.io.PrintStream.write(PrintStream.java:527)at java.io.PrintStream.print(PrintStream.java:669)at java.io.PrintStream.println(PrintStream.java:806)at com.demo.rpc.test.Demo.work(Demo.java:9)at com.demo.rpc.test.Demo.work(Demo.java:10)上述所示异常会明确提示:出现栈内存溢出的问题,原因是不断调用Demo类的work()方法导致的。
因此对于栈内存溢出的问题,定位和解决的思路就很简单了。只要把所有的异常都写入本地日志文件,那么发现系统崩溃时,去日志里定位异常信息即可。
(4)总结
情形一:Metaspace区域溢出
通过异常信息可以直接定位出是Metaspace区域发生异常,然后分析GC日志就可以知道Metaspace发生溢出的全过程,接着再使用MAT分析内存快照,就知道是哪个类太多导致异常。
情形二:栈内存溢出
首先从异常日志中就能知道是栈内存溢出。
然后从异常日志中可以找到对应的报错方法。
知道哪个方法后,就可以到代码中定位问题。
5.JVM堆内存溢出时应该如何解决(OutOfMemoryError: Java heap space)
(1)示例代码
运行如下程序:
public class Demo3 {public static void main(String[] args) {long counter = 0;List<Object> list = new ArrayList<Object>();while(true) {list.add(new Object());System.out.println("当前创建了第" + (++counter) + "个对象");} }
}采用的JVM参数如下:
-Xms10m -Xmx10m-XX:+PrintGCDetails -Xloggc:gc.log-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./-XX:+UseParNewGC -XX:+UseConcMarkSweepGC(2)运行后的观察
其实堆内存溢出的现象也是很简单的,在系统运行一段时间之后,会发现系统崩溃了,然后登录到线上机器检查日志文件。先看到底为什么崩溃:
java.lang.OutOfMemoryError: Java heap space
Dumping heap to ./java_pid1023.hprof ...
Heap dump file created [13409210 bytes in 0.033 secs]Exception in thread "main" java.lang.OutOfMemoryError: Java heap space这个就表明了:是Java堆内存溢出了,而且还导出了一份内存快照。此时GC日志都不用分析,因为堆内存溢出往往对应着大量的GC日志。这些大量的GC日志分析起来很麻烦,可以直接将线上自动导出的内存快照拷贝回本地,然后使用MAT分析。
(3)用MAT分析内存快照
采用MAT打开内存快照后会看到下图:

这次MAT非常简单,直接在内存泄漏报告中告诉我们。内存溢出原因只有一个,因为它没提示任何其他的问题。接下来仔细分析一下MAT提供的分析报告。
一.首先看下面的提示
The thread java.lang.Thread @ 0x7bf6a9a98 main keeps local variables with total size 7,203,536 (92.03%) bytes.意思是main线程通过局部变量引用了7230536个字节的对象(7M),考虑到总共就给堆内存10M,所以7M基本上个已经到极限了。
二.接着看下面的提示
The memory is accumulated in one instance of "java.lang.Object[]" loaded by "<system class loader>".这句话的意思是内存都被一个实例对象占用了,就是java.lang.Object[]。
三.这时还不能判断,得点击Details

在Details里能看到这个东西,即占用了7M内存的的java.lang.Object[]。这里会列出该Object数组的每个元素,可见是大量的java.lang.Object,而这些java.lang.Object其实就是我们在代码里创建的。至此真相大白,就是大量的Object对象占用了7M的内存导致内存溢出。
四.接着分析这些对象是如何创建出来的
此时可以回到上一级页面进行查找,如下:

这个意思是可以查看创建那么多对象的线程,它的一个执行栈。从线程执行栈中就可知这个线程在执行什么方法时创建了大量的对象。
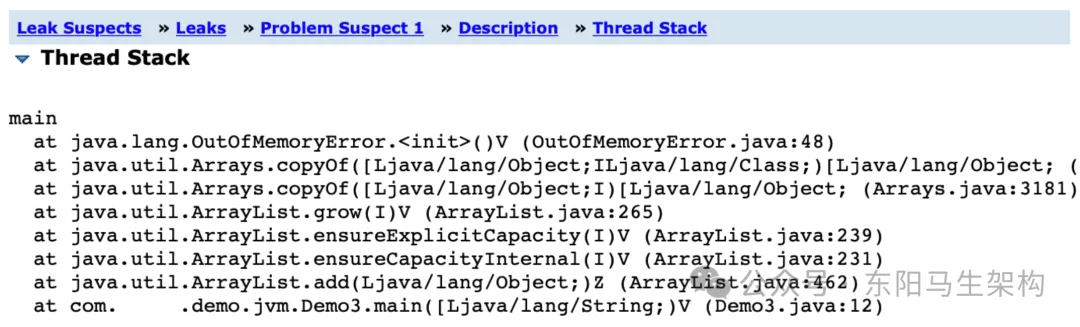
从上面的调用栈可以看到:Demo3.main()方法会一直调用ArrayList.add()方法,然后引发OOM。所以接下来只要在对应代码里看一下,就知道怎么回事了。接着优化对应的代码即可,这样就不会发生内存溢出了。
(4)总结
堆内存溢出问题的分析和定位:
一是加入自动导出内存快照的参数
二是到线上看一下日志文件里的报错
如果是堆溢出,则用MAT分析内存快照。
MAT分析的时候一些顺序和技巧:
一.首先看占用内存最多的对象是谁
二.然后分析那个线程的调用栈
三.接着看哪个方法引发内存溢出
四.最后优化代码即可
文章转载自:东阳马生架构
原文链接:JVM实战—12.OOM的定位和解决 - 东阳马生架构 - 博客园
体验地址:引迈 - JNPF快速开发平台_低代码开发平台_零代码开发平台_流程设计器_表单引擎_工作流引擎_软件架构