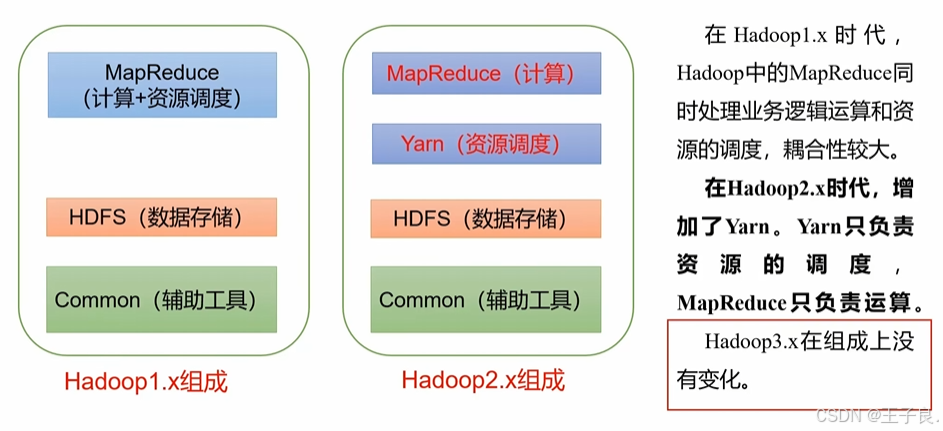
一、从基础的客户端说起
Kafka 提供了非常简单的生产者(Producer)和消费者(Consumer)API。通过引入相应依赖后,可以快速上手编写生产者和消费者的示例。
1. 消息发送者主流程
一个最基础的 Producer 发送消息的步骤如下:
-
设置 Producer 核心属性
- 例如:
bootstrap.servers(集群地址)、key.serializer、value.serializer等。 - 大多数核心配置在
ProducerConfig中都有对应的注释说明。
- 例如:
-
构建消息
- Kafka 消息是一个
Key-Value结构,Key常用于分区路由,Value则是业务真正要传递的内容。
- Kafka 消息是一个
-
发送消息
- 单向发送:
producer.send(record);仅发出消息,不关心服务端响应。 - 同步发送:
producer.send(record).get();获取服务端响应前会阻塞。 - 异步发送:
producer.send(record, callback);服务端响应时会回调。
- 单向发送:
示例核心代码示意:
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());Producer<String,String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record =new ProducerRecord<>(TOPIC, key, value);
// 单向发送
producer.send(record);
// 同步发送
producer.send(record).get();
// 异步发送
producer.send(record, new Callback() { ... });
2. 消息消费者主流程
在 Consumer 侧,同样有三步:
-
设置 Consumer 核心属性
- 例如:
bootstrap.servers、group.id、key.deserializer、value.deserializer等。
- 例如:
-
拉取消息
- Kafka 采用 Pull 模式:消费者主动调用
poll()拉取消息。
- Kafka 采用 Pull 模式:消费者主动调用
-
处理消息,提交位点
- 手动提交:
consumer.commitSync()或consumer.commitAsync() - 自动提交:设置
enable.auto.commit = true及相应提交周期参数。
- 手动提交:
示例核心代码示意:
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BOOTSTRAP_SERVERS);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(TOPIC));while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));for (ConsumerRecord<String, String> record : records) {// 业务处理}// 手动提交 offsetconsumer.commitSync();
}
二、从客户端属性来梳理客户端工作机制
Kafka 的核心特色在于高并发、高吞吐以及在网络不稳定、服务随时会崩溃等复杂场景下仍能保证消息安全性。以下属性与机制能帮助我们从客户端视角理解 Kafka。
1. 消费者分组消费机制
- Group 机制
每个Consumer都会指定一个group.id。同一个 Consumer Group 内,Topic 的每个 Partition 只会被同组里的一个 Consumer 消费。不同组之间则是互不影响、各自消费。 - offset 提交
- offset 保存在 Broker 端,但由 Consumer “主导”提交。
- 提交方式有:
- 同步:
commitSync(),安全但速度慢; - 异步:
commitAsync(),快但可能丢失或重复消费。
- 同步:
- auto.offset.reset
- 当 Broker 端没有找到该 Group 相应的 offset 时,可以根据配置(
earliest,latest,none)决定从何处开始消费。
- 当 Broker 端没有找到该 Group 相应的 offset 时,可以根据配置(
提示:Offset 提交与消息处理之间并非完全同步,一旦无法保证强一致性,可能出现消息重复与消息丢失。可根据业务需求与场景选择手动提交或自动提交,也可将 offset 存入外部存储(如 Redis)自行管理。
2. 生产者拦截器机制
- 通过配置
interceptor.classes可以指定一个或多个实现了ProducerInterceptor接口的拦截器。 - 典型功能:在发送前统一添加/修改消息内容,或者在发送后做监控/统计等操作。
3. 消息序列化机制
- Producer 端:
key.serializer/value.serializer:将对象序列化为byte[]。- 内置如
StringSerializer、IntegerSerializer等;可自定义自定义序列化类。
- Consumer 端:
key.deserializer/value.deserializer:将byte[]反序列化为业务对象。
- 如果使用自定义类型(POJO)进行传输,则需要编写自定义 Serializer/Deserializer。
- 核心思想:定长字段与不定长字段的序列化与反序列化。
4. 消息分区路由机制
- Producer 侧:
- 通过
partitioner.class指定自定义的分区器(Partitioner接口)。Kafka 内置默认逻辑:- 若无 key,则采用黏性分区策略(Sticky Partition);
- 若指定 key,则对 key 进行哈希得到分区;
- 也可改为轮询策略(RoundRobinPartitioner)。
- 通过
- Consumer 侧:
- 通过
partition.assignment.strategy指定分区分配策略,内置RangeAssignor,RoundRobinAssignor,StickyAssignor,CooperativeStickyAssignor等。- Range:按顺序将分区切块分配。
- RoundRobin:轮询分配。
- Sticky:尽可能保持现有分配不变,同时保证分配均匀。
- 通过
5. 生产者消息缓存机制
生产者为了提高吞吐量,会将消息先写入一个本地缓存(RecordAccumulator),然后 sender 线程批量发送到 Broker:
buffer.memory:缓存总大小,默认 32MB。batch.size:每个分区发送批次大小,默认 16KB。linger.ms:即便batch.size未填满,等待linger.ms毫秒后也会将消息批量发送。max.in.flight.requests.per.connection:同一连接上未收到响应的请求数上限。
6. 发送应答机制
acks用于控制生产者发送完消息后何时认为消息“成功”:acks=0:不等待 Broker 确认,吞吐量高,安全性低。acks=1:只等待 Leader 分区写入,常见设置。acks=all或-1:等待所有副本写入,安全性最高,吞吐量相对低。
- 还需配合 Broker 端
min.insync.replicas参数,控制副本个数不足时直接返回错误。
7. 生产者消息幂等性
- 为保证 Exactly-once 语义,需要开启
enable.idempotence(幂等性)。 - 幂等性主要依赖
PID+SequenceNumber机制:- Producer 向同一分区发送消息时,每条消息都有一个单调递增的序列号。
- Broker 针对
<PID, Partition>维护序列号,只接收递增消息,防止消息重复写入。
- 幂等性要求:
acks=allretries>0max.in.flight.requests.per.connection<=5
8. 生产者消息事务
- 幂等性只能保证单个分区的 Exactly-once,如果涉及 多个分区/Topic 则需要“事务”来保证一批消息的一致性。
- 主要 API:
initTransactions()beginTransaction()commitTransaction()abortTransaction()
- 事务依赖于
transaction.id来区分不同的 Producer 实例,以便在崩溃重启后继续补偿或回滚先前未完成的事务,保证多分区的一致写入。
三、客户端流程总结
-
Producer:
- 属性配置(序列化、分区器、拦截器、幂等性/事务等) → 将消息提交到
RecordAccumulator→Sender线程批量发送到 Broker → 按acks等待 Broker 响应 → 提交或重试。
- 属性配置(序列化、分区器、拦截器、幂等性/事务等) → 将消息提交到
-
Consumer:
- 属性配置(反序列化、消费组、分区分配策略等) →
poll()拉取消息 → 业务处理 → 提交 offset(手动或自动),与 Broker 同步消费进度。
- 属性配置(反序列化、消费组、分区分配策略等) →
-
重点:
- 消息在 Producer 端的缓存发送机制 与 消息在 Consumer 端的主动拉取、分组消费、offset 提交 是理解 Kafka 高并发、高吞吐、高可用的关键。
- 其他如 幂等性(保证单分区 Exactly-once)和 事务(保证多分区一致性)是针对数据安全性和业务需求的更深入扩展。
四、Spring Boot 集成 Kafka
Spring Boot 中集成 Kafka 本质也是对上述 Producer/Consumer 的封装。
-
引入依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId> </dependency> -
在
application.properties中配置 Kafka 相关参数- 和原生 Kafka 参数名称基本一致,如
spring.kafka.producer.*、spring.kafka.consumer.*等。 - 典型参数:
bootstrap-servers,acks,batch-size,enable-auto-commit,auto-offset-reset等。
- 和原生 Kafka 参数名称基本一致,如
-
使用
KafkaTemplate发送消息@RestController public class KafkaProducerController {@Autowiredprivate KafkaTemplate<String, Object> kafkaTemplate;@GetMapping("/kafka/send/{message}")public void sendMessage(@PathVariable("message") String msg) {kafkaTemplate.send("topic1", msg);} } -
使用
@KafkaListener声明消息消费者@Component public class KafkaConsumerListener {@KafkaListener(topics = {"topic1"})public void onMessage(ConsumerRecord<?, ?> record) {System.out.println("消费内容:" + record.value());} }
结语
- 想要真正掌握 Kafka,重点在于建立整体的数据流转模型:
- Producer 端如何将消息分区、缓存、发送、应答、重试、保证幂等与事务;
- Consumer 端如何分组消费、订阅分区、拉取消息、提交 offset。
- 熟悉这些机制后,再去看各种客户端配置就会轻松许多,能够结合实际业务场景做灵活配置与调优。
- Spring Boot 也只是对原生 Kafka 客户端的进一步封装,一旦理解 Kafka 底层机制与各项参数原理,使用 Spring Boot 时只需“对号入座”地进行配置即可。