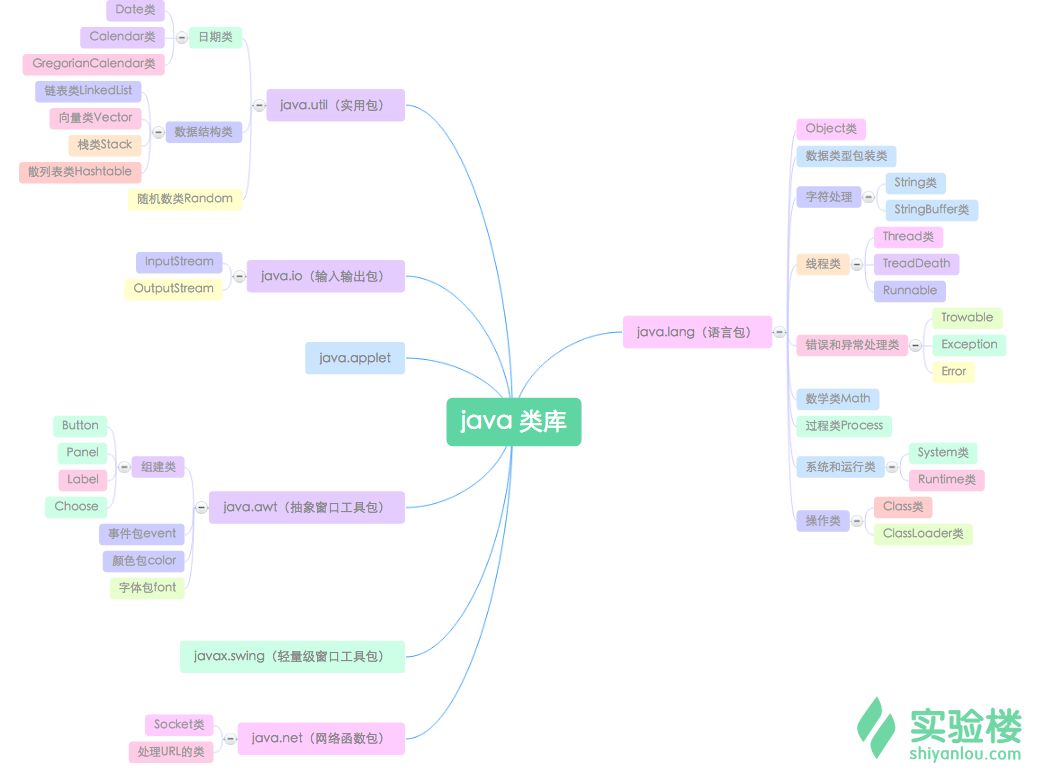
1月初,微软在官网发布了2025年6大AI预测,分别是:AI模型将变得更加强大和有用、AI Agents将彻底改变工作方式、AI伴侣将支持日常生活、AI资源的利用将更高效、测试与定制是开发AI的关键以及AI将加速科学研究突破。
值得一提的是,微软在序言部分强调了AI Agents在未来工作中的重要影响。到2025年,AI将以自主、自动的方式完成更多的复杂工作流程,来提升工作、家庭方面的效率。

【图片来源于网络,侵删】
1.AI模型将变得更加强大和有用

【图片来源于网络,侵删】
微软提到,过去一年,AI模型进步显著。大规模的前沿模型如OpenAI o1, 已经能用逻辑步骤解决复杂问题,在科学、编码、数学、法律和医学等领域发挥作用。
除了模型本身的创新,数据整理和后期训练的突破同样关键。例如,微软的Phi系列小型模型表明,高质量数据的精心筛选可以显著提升模型的性能与推理水平。Orca和Orca 2则展示了合成数据对小型语言模型训练后优化的作用,使其达到以往大型语言模型的性能水平,并在特定任务中表现更好。
这些技术进展将推动模型运行变得更快、更精准、更专业,为2025年带来全新的AI应用场景,尤其是在AI Agents领域的应用。
2. AI Agents将彻底改变工作方式

【图片来源于网络,侵删】
近年来,AI领域发展势头迅猛,AI Agents作为其中的突出成果,正逐渐走进人们的视野。
所谓AI Agents,既可以是软件程序,也能够以AI 助手的形式集成于各类设备之中,它们具备理解自然语言指令的能力,通过自主学习与推理,不但可以应对复杂任务的挑战,还能与用户实现自然流畅的交互。
2025 年,新一代AI Agents不仅能够承接更多类型的任务,甚至还能代替用户执行一些具体操作。微软方面透露,在财富 500 强企业里,接近 70% 的员工已经借助 Microsoft 365 Copilot 中的 Agents,轻松处理诸如自动筛选电子邮件、在 Teams 会议期间自动做笔记并生成摘要等大量重复性的日常工作。
3. AI伴侣将支持日常生活

【图片来源于网络,侵删】
2025年,人工智能有望让生活更轻松。AI伴侣不仅能提升生活效率,还能增强与用户的互动。例如,根据用户阅读的新闻提供摘要,或通过视觉能力理解网页内容并给出即时反馈。在家居生活方面,AI还能推荐合适家具、帮助布置家居环境,甚至提供风水建议。

【图片来源于网络,侵删】
随着技术进步,我们有理由相信未来的AI伴侣将更智能、更有情感,提供更个性化和贴心的服务,让生活更加便捷和丰富。
4. AI资源的利用将更高效

【图片来源于网络,侵删】
尽管AI需要消耗能源,但创新技术正在帮助缓解这一挑战。以数据中心为例,2020年的全球数据中心工作负载是2010年的九倍,但用电量仅增加了 10%。
这是因为微软正与AMD、Intel 和 NVIDIA等公司合作,提升硬件的效率。微软已在数据中心采用更高效的硬件和冷却技术,降低能耗,提升系统运行效率。
微软还将继续投资并使用无碳能源,如风能、地热能、核能和太阳能。公司正在进行长期投资,以将更多的无碳电力引入其运营的电网,并继续倡导全球清洁能源解决方案的扩展。
5. 测试与定制是开发AI的关键

【图片来源于网络,侵删】
测试是定义和评估AI中的风险,对于负责任地构建AI至关重要。2025年AI的发展可以用两个词来概括——测试和定制。
随着AI技术在各行业的广泛应用,完善的测试和定制体系可以帮助开发人员识别和消除AI系统中的漏洞。这一趋势预示着,未来我们在享受AI便利的同时,也能保障它的风险可控和安全可靠。
6. AI将加速科学研究突破

【图片来源于网络,侵删】
AI已经在世界各地产生了巨大影响,推动了从超级计算到天气预报等各个领域的进步。它正在推动科学研究的历史性突破,并有望在自然科学、可持续材料、药物发现和人类健康等领域释放新的能力。
在2024年,微软研究院利用AI驱动的蛋白质模拟系统,找到了一种新的方法(AI2BMD)来模拟生物分子动力学。这种方法可以帮助科学家解决以前难以解决的问题,并推动蛋白质设计、酶工程和药物发现等生物医学研究。
微软研究院副总裁兼董事总经理Ashley Llorens表示,2025年最令人兴奋的事情之一将是AI在科学研究中的使用,如何推动解决世界上的一些最紧迫问题的进展。
从更强大的AI模型到支持日常生活的AI伴侣,再到彻底改变工作方式的Al Agents,AI技术正在深入每个领域。小编相信,未来AI将继续引领创新,并为全球个人与组织释放更多潜力,为人类带来前所未有的效率和创新可能性。
关于未来的AI发展趋势,大家有什么看法呢?欢迎在评论区留言讨论~