一、实验目的:
调用线程进行超大文本文件单词频数统计,测试并讨论不同线程数对代码耗时的影响
二、实验环境:
(1)c/c++,编辑器:Visual Studio与code:blocks;(2)python,编辑器:pycharm
三、实验说明:
通过在pycharm上编写代码(makefile.py)生成1G大小的单词文件(small_file)并生成各单词的数量文件(result.txt),再编写c++代码不同数目的线程统计单词数量的耗时并与result.txt进行对比判断结果是否正确。
四、实验代码:
见cod文件夹
五、实验步骤
(1)编写.py文件
①定义词典与计数器,单词文件里的单词即词典中的单词,计数器统计各单词数量
# 词典
dictionary = ['one ', 'two ', 'three ', 'four ', 'five ', 'big ', 'small ', 'light ']
# 计数器
counter = [0 for i in range(len(dictionary))]
②定义build_file函数,生成1G大小的单词文件
def build_file(file_name):
file = open(file_name, 'w')
file_size = os.path.getsize(file_name)
if file_size <= oneG :
# 文件大小小于1G
while file_size <= oneG:
file.writelines(getWords())
file_size = os.path.getsize(file_name)
③定义getWords()函数,统计各单词数量
def getWords():
list = []
for i in range(random.randint(1, 2)):
index = random.randint(0, len(dictionary) - 1)
counter[index] += 1
list.append(dictionary[index])
list.append('\n')
return list
(2)编写.cpp文件
①定义多线程共享变量dirc_loop和互斥量m
std::vector<std::map<std::string, int>> dirc_loop;
std::mutex m;
②定义getFileSize函数,获得单词文件大小
int getFileSize(std::string file)
{
if (file.empty())
return 0;
struct stat filestat;
if (stat(file.c_str(), &filestat) < 0) {
perror("error: ");
}
return filestat.st_size;
}
③定义fileExist函数,判断单词文件是否存在
int fileExist(std::string file)
{
if (file.empty())
return 0;
struct stat filestat;
if (stat(file.c_str(), &filestat) < 0) {
perror("error: ");
return 0;
}
printf("file exist\n");
return 1;
}
④定义readFile函数,统计各单词数量
int readFile(std::string fileName, size_t file_offsize, size_t end)
{
std::map<std::string, int> dirc;
std::fstream file;
file.open(fileName, std::ios::in);
if (!file.is_open())
return -1;
// 设置文件指针位置
file.seekg(file_offsize, std::ios::beg);
// 查找新的完整单词开始位置
if (file_offsize != 0) {
int last_c = file.seekg(-1, std::ios::cur).get();
if (last_c != ' ' && last_c != '\n') {
while (true) {
int c = file.get();
if (c == ' ' || c == '\n')
break;
}
}
}
printf("read start\n");
// 开始读取
std::string line;
while (file >> line) {
if (dirc.find(line) != dirc.end())
dirc[line] += 1;
else
dirc[line] = 1;
size_t endPos = file.tellg();
if (endPos + 1 >= end)
break;
}
m.lock();
dirc_loop.push_back(dirc);
m.unlock();
return 0;
}
⑤主函数
int main()
{
printf("start\n");
std::fstream file;
std::string fileName = "D:\\PyCharm\\workspace\\Project\\计操\\small_file"; // 文件名
if (!fileExist(fileName))
return 0;
printf("file size: %d\n", getFileSize(fileName));
int parts = 4; //设置线程数
int dater = getFileSize(fileName) / parts;
std::vector<std::thread> t_loop;
auto start_time = std::chrono::system_clock::now();
for (int i = 0; i < parts; i++) t_loop.push_back(std::thread(readFile, fileName, i * dater, (i + 1) * dater));
for (int i = 0; i < parts; i++) t_loop[i].join();
std::cout << "SPENT TIME: " << std::chrono::duration_cast<std::chrono::microseconds>((std::chrono::system_clock::now() - start_time)).count() << " 微秒" << std::endl;
printf("read over\n");
// 汇总结果
for (int i = 0; i < dirc_loop.size(); i++)
{
if (i == 0) continue;
for (auto d : dirc_loop[i]) {
if (dirc_loop[0].find(d.first) != dirc_loop[0].end()) {
dirc_loop[0][d.first] += d.second;
}
else {
dirc_loop[0][d.first] = d.second;
}
}
}
// 输出
for (auto i : dirc_loop[0])
{
printf("%s %d\n", i.first.c_str(), i.second);
}
}
六、结果分析
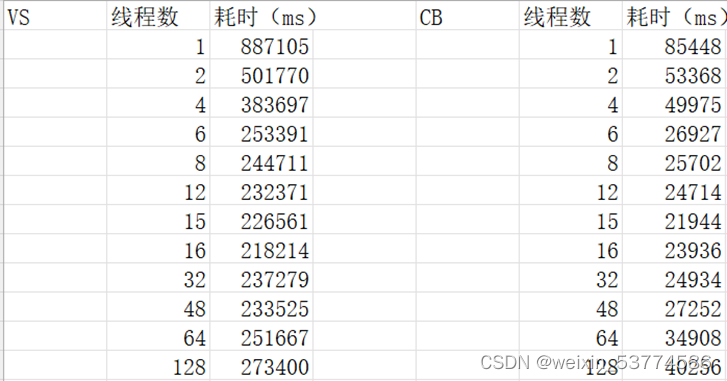
由此图可以看出,随线程数的增加,程序耗时先减少后增加且不同编译器的耗时相差较大。线程多了可以提高程序并行执行的速度,但是并不是越多越好,其中,每个线程都要占用内存,多线程就意味着更多的内存资源被占用,其二,如果线程太多,cpu必须不断的在各个线程间快回更换执行,线程间的切换无意间消耗了许多时间,所以cpu有效利用率反而是下降的。并且不同的编译器对由源文件经编译生成目标文件,然后经过连接生成可执行文件的优化各不相同,故不同编译器的相同程序耗时不同。最后由于异步性,相同代码的每次执行耗时也略有差异。