关于Word2Vec,上篇文章文本分类特征提取之Word2Vec中已有还算详尽的叙述。简单总结下:word2vec是Google在2013年提出的一款开源工具,其是一个Deep Learning模型(实际上该模型层次较浅,严格上还不能算是深层模型,如果word2vec上层再套一层与具体应用相关的输出层,如Softmax,便更像是一个深层模型),它将词表征成实数值向量,采用CBOW(Continuous Bag-Of-Words Model,连续词袋模型)和Skip-Gram(Continuous Skip-GramModel)两种模型。具体原理,网上有很多。
文本语料训练数据集
下面提供一些网上能下载到的中文的好语料,供研究人员学习使用。
(1)中科院自动化所的中英文新闻语料库
http://www.datatang.com/data/13484
中文新闻分类语料库从凤凰、新浪、网易、腾讯等版面搜集。
英语新闻分类语料库为Reuters-21578的ModApte版本。

(2)搜狗的中文新闻语料库
http://www.sogou.com/labs/resource/cs.php
包括搜狐的大量新闻语料与对应的分类信息。有不同大小的版本可以下载。
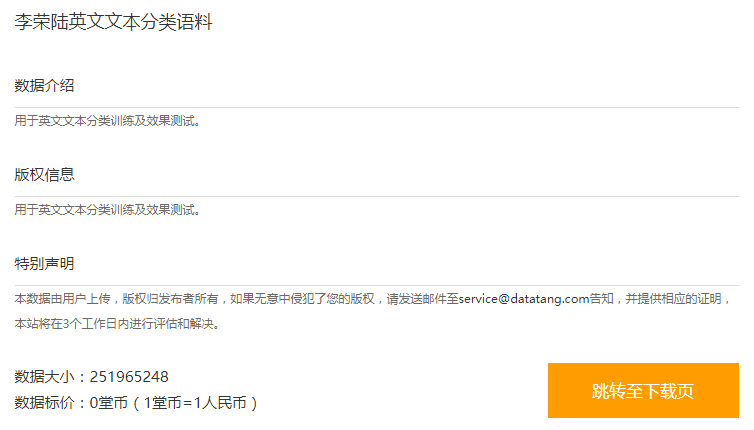
(3)李荣陆老师的中文语料库
http://www.datatang.com/data/11968
压缩后有240M大小
(4)谭松波老师的中文文本分类语料
http://www.datatang.com/data/11970
不仅包含大的分类,例如经济、运动等等,每个大类下面还包含具体的小类,例如运动包含篮球、足球等等。能够作为层次分类的语料库,非常实用。这个网址免积分(谭松波老师的主页):http://www.searchforum.org.cn/tansongbo/corpus1.php

(5)网易分类文本数据
http://www.datatang.com/data/11965
包含运动、汽车等六大类的4000条文本数据。

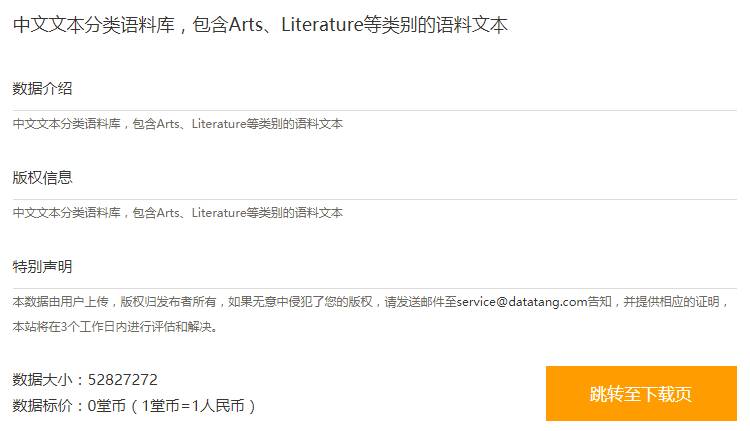
(6)中文文本分类语料
http://www.datatang.com/data/11963
包含Arts、Literature等类别的语料文本。
(7)更全的搜狗文本分类语料
http://www.sogou.com/labs/resource/cs.php
搜狗实验室发布的文本分类语料,有不同大小的数据版本供免费下载.
StandardAnalyzer(中英文)
ChineseAnalyzer(中文)
CJKAnalyzer(中英文)
IKAnalyzer(中英文,兼容韩文,日文)
paoding(中文)
MMAnalyzer(中英文)
MMSeg4j(中英文)
imdict(中英文)
NLTK(中英文)
Jieba(中英文)
这几种分词工具的区别,可以参加:http://blog.csdn.net/wauwa/article/details/7865526。
更多资料
文本分类特征提取之Word2Vec
干货|开放数据集
LR如何在语言理解NLU中实现文本分类
自然语言处理入门资料推荐
书单下载 | 关于算法、编程、机器学习等书籍,也许正是你所需要的
机器学习资源共享
... ...
免责声明,如若侵犯到您的原创保护,请联系我们并立即处理。本人才疏学浅,如有不当之处,欢迎高手不吝赐教。
星光不问赶路人
时光不负有心人

更多干货内容请关注微信公众号“AI 深入浅出”
长按二维码关注