前言
嗨喽~大家好呀,这里是魔王呐 ❤ ~!

开发环境:
-
Python 3.8
-
Pycharm 2021.2
模块使用:
第三方模块
-
requests >>> pip install requests
-
tqdm >>> pip install tqdm 简单实现进度条效果
自带模块
-
os
-
base64

采集代码
导入模块
# 数据请求模块 --> 第三方模块 需要安装 pip install requests
import requests
import base64
from pprint import pprint
import os
from tqdm import tqdm
“”"
1. 发送请求, 模拟浏览器对url地址发送请求
-
模拟浏览器: 请求头 headers
字典数据类型, 一定要构建完成键值对
多页数据采集 --> 分析请求url 请求参数变化规律
“”"
for page in range(1, 13):print(f'==================正在采集第{page}页的数据内容==================')# 请求url地址 <复制>url = f'https://www.网站.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page={page}'# 模拟伪装 <复制>headers = {# User-Agent 用户代理 表示浏览器基本身份信息'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}
🎯 博主所有文章素材、解答、源码领取处:点击
发送请求
调用requests模块里面get请求方法对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量response接收返回数据
response = requests.get(url=url, headers=headers)# <Response [200]> 响应对象, 表示请求成功print(response)
2. 获取数据, 获取服务器返回响应数据
开发者工具 --> response
response.json() 获取响应json字典数据, 返回的数据必须是完整json数据格式
当你遇到 simplejson.errors.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
解决方法:
-
先获取文本数据
response.text目的看一下我返回数据是什么样子的 <得到数据了呢, 还是得到数据有问题呢>
-
当你看到返回的数据
getLiveListJsonpCallback(里面字典样子花括号)把链接里面
Callback参数删掉
3. 解析数据, 提取我们想要的数据内容
-
主播名字
-
主播照片url
response.json() --> 字典数据类型
根据键值对取值: 根据冒号左边的内容[键], 提取冒号右边的内容[值]
# for循环遍历, 把列表里面元素一个一个提取出来for index in response.json()['data']['datas']:# 提取主播名字name = index['nick']# 提取照片img_url = index['screenshot']
“”"
4. 保存数据, 把图片保存本地文件夹
发送请求 img_url , 获取数据 获取二进制数据
response.content 获取响应二进制数据
图片/音频/视频/特定格式文件 —> 获取二进制数据进行保存
只要可以得到数据, 实现效果, 过程不重要
D:\自游\颜值检测\img\
\ 转义字符 把含有特殊含义字符, 转义成除了字符本身以外, 不含有任何意义
“”"
img_content = requests.get(url=img_url, headers=headers).content# 'img\\'<文件夹> + name<文件名> + '.jpg'<文件后缀> wb 保存方式, 二进制保存with open('img\\' + name + '.jpg', mode='wb') as f:f.write(img_content)print(name, img_url)
效果

检测代码
🎯 博主所有文章素材、解答、源码领取处:点击
# 数据请求模块 --> 第三方模块 需要安装 pip install requests
import requests
import base64
from pprint import pprint
import os
from tqdm import tqdm
def beauty(img):'''现成复制的获取 access_token 值'''try:# client_id 为官网获取的AK, client_secret 为官网获取的SKhost = ''response = requests.get(host)access_token = response.json()['access_token']'''人脸检测与属性分析'''# 读取文件内容 照片内容f = open(f'img\\{img}', mode='rb')# 读取出来文件 转成 base64 编码格式img_base64 = base64.b64encode(f.read())"""现成API调用代码"""request_url = ""params = {"image": img_base64, # 需要传递 图片 base64"image_type": "BASE64","face_field": "beauty"}request_url = request_url + "?access_token=" + access_tokenheaders = {'content-type': 'application/json'}response = requests.post(request_url, data=params, headers=headers)beauty = response.json()['result']['face_list'][0]['beauty']return beautyexcept:return '识别失败'# 读取文件内容 或者 文件名字
lis = []
files = os.listdir('img\\')
print('正在进行颜值检测, 稍后.......')
for file in tqdm(files[100:200]):num = beauty(file)if num != '识别失败':title = file.split('.')[0]dit = {'主播': title,'颜值': num}lis.append(dit)lis.sort(key=lambda x:x['颜值'], reverse=True)i = 1
for li in lis:print(f'颜值排名第{i}的是{li["主播"]}, 颜值评分是{li["颜值"]}')i += 1
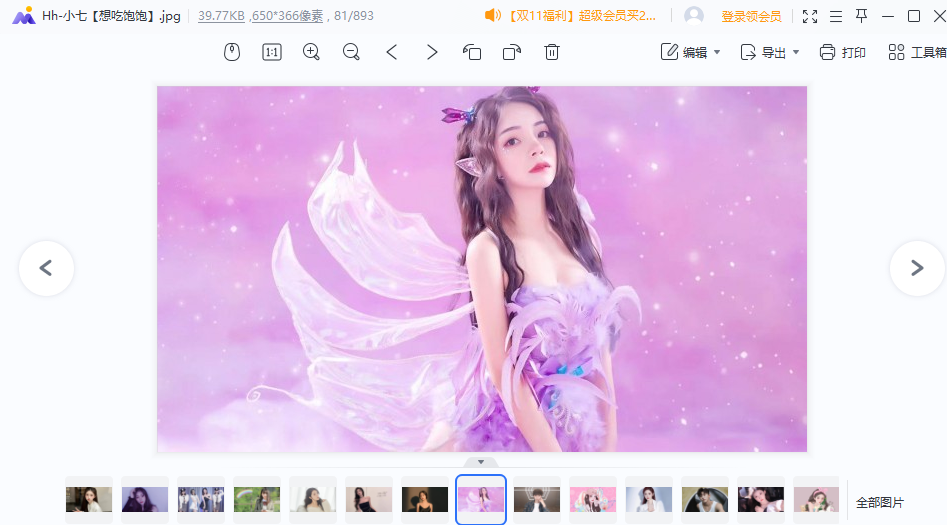
颜值检测效果



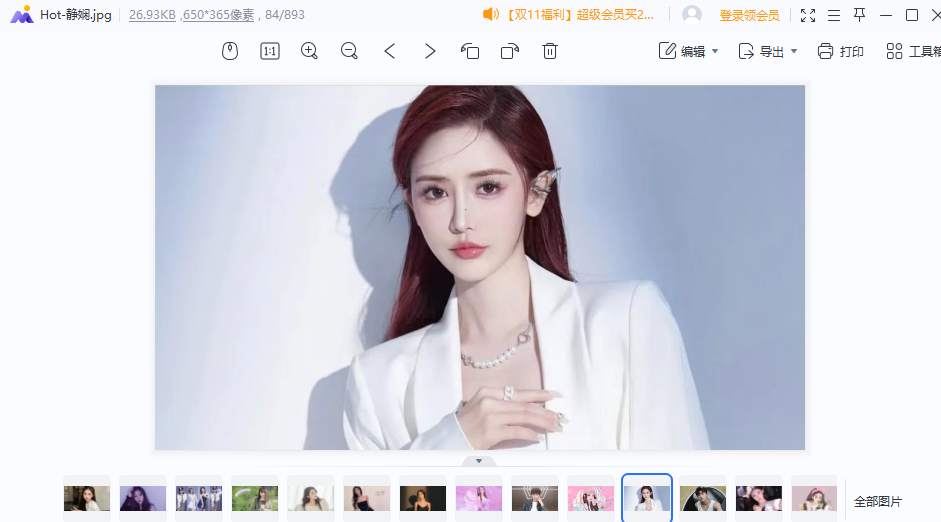
首先我们来搜一下第一名,看看长什么样吧

咳咳,那我们在来看一下最后一名,通常第一都是都点迷惑得~

按照的窝得经验之谈,一般七、八十分得长得都是还不错的~
我们来看看吧~








推荐往期文章
🎯 博主所有文章素材、解答、源码领取处:点击
对python感兴趣的小伙伴也可以看一下博主其他相关文章哦~
python小介绍:
python是什么?工作前景如何?怎么算有基础?爬数据违法嘛?。。
python数据分析前景:
用python分析“数据分析”到底值不值得学习,以及学完之后大概能拿到多少工资
python基础自测题:
Python 800 道习题 (°ー°〃) 测试你学废了嘛
最后推荐一套Python视频给大家,希望对大家有所帮助:
全套教程!你和大佬只有一步之遥【python教程】
尾语
好了,今天的分享就差不多到这里了!
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤