目前常用语音相对评估指标(参考)4个,绝对评估(无参考)指标3个。简述如下所示:**
相对指标:
1、pesq:共综合以下5个方面打分,分别为音频清晰度、音量、背景噪音音频中的可变延迟或滞后、丢失、音频干扰,PESQ 评分是从 -0.5 到 4.5 的分数,分数越高表示质量越好。可根据以下分数区间进行参考:
-0.5 – 1.99:语音质量极差,完全听不清楚语音的具体内容;
2.00 – 2.39 :语音质量很差,需要集中很多精神或注意力才能听清楚具体内容;
2.40 – 2.79 :语音质量较差,需要集中较多的精神或注意力才能听到具体内容;
2.80 – 3.29 :语音质量一般,仅需要稍微集中一下注意力就能听很清楚;
3.30 – 3.79 :语音质量较好,无需集中注意力就可听的很清楚;
3.80 – 4.50 :语音质量极佳,放松简单的就可以听清楚说话内容;
2、stoi:短时客观可懂度,反映人类的听觉感知系统对语音可懂度的客观评价,STOI 值介于0~1 之间,值越大代表语音可懂度越高,越清晰。
3、bsseval:盲源分离指标,用于测试盲源分离的性能指标;
4、sisdr:标度不变源失真比,用于测试盲源分离,值越高越好。越高代表语音干扰越小、失真越小。
绝对指标(无参考):
1、nisq:基于深度学习绝对评价指标,只需入音频。其输出结果共有五个维度,共同评价语音质量:
维度1:mos_pred :语音质量指标,越高音质越好
维度2:noi_pred :噪声等级指标,越高代表噪声越小
维度3:dis_pred :语音连贯性指标,越高代表语音连贯性越好
维度4:col_pred :音色指标,越高越好听
维度5:loud_pred :语音响度指标,越高代表音量更响亮
2、mosnet:深度学习mos评分;
3、srmr:语音混响调制能量比,分数越高,混响越小,越清晰;
用法
(相对pesq、stoi、bsseval、sisdr)
备注:pesq、stoi客观指标测试,其输入的参考音频与测试音频长度必须相等;
pesq:
Windows 环境下需先安装pycharm 。 安装pypesq 库,方法:
安装方法:打开pycharm,点击Terminal,输入
$ git clone https://github.com/ludlows/python-pesq.git
$ cd python-pesq
$ pip install . # for python 2
$ pip3 install . # for python 3
$ cd …
$ rm -rf python-pesq # remove the code folder since it exists in the python package folder
程序编写可参考如下:
使用方法:
import soundfile as sf
from pypesq import pesq
path_ref = ‘gongwei_mic_mono.wav’ //参考语音
path_gen = ‘gongwei_mic_mono.wav’ //测试语音
ref,samplerate = sf.read(path_ref)
gen,samplerate = sf.read(path_gen)
peaq_score = pesq(ref ,gen ,samplerate)
print('peaq_score = ',peaq_score )
stoi:
Windows 环境下需先安装pycharm 。然后 安装stoi库,pip install pystoi ;
安装方法:打开pycharm,点击Terminal,然后输入pip install pystoi即可,具体与上步骤相似,等待安装成功;
使用方法:
程序编写可参考如下:
import soundfile as sf
from pystoi import stoi
clean, fs = sf.read(‘gongwei_mic_mono.wav’) //参考语音
denoised, fs = sf.read(‘gongwei_mic_mono.wav’) //测试语音
stoi_score = stoi(clean, denoised, fs, extended=False)
print('stoi = ’ ,stoi_score)
bsseval、sisdr:
pip install numpy
pip install git+https://github.com/aliutkus/speechmetrics#egg=speechmetrics[cpu]
完成后输入以下脚本:
import speechmetrics window_length = 15 # seconds
path_to_estimate_file = ‘test.wav’ #test audio path
path_to_reference = ‘reference.wav’ #reference audio path
metrics = speechmetrics.load([‘bsseval’, ‘sisdr’], window_length) scores = metrics(path_to_estimate_file, path_to_reference)
print(scores)
(绝对 NISQ、MOSNET、SRMR)
NISQ为基于深度学习绝对评价指标,只需入音频。其输出结果共有五个维度,共同评价语音质量:(网站: gabrielmittag/NISQA: NISQA - Non-Intrusive Speech Quality and TTS Naturalness Assessment (github.com))
维度1:mos_pred :语音质量指标,越高音质越好
维度2:noi_pred :噪声等级指标,越高代表噪声越小
维度3:dis_pred :语音连贯性指标,越高代表语音连贯性越好
维度4:col_pred :音色指标,越高越好听
维度5:loud_pred :语音响度指标,越高代表音量更响亮
使用方法:
在终端执行以下命令:
1、git clone https://github.com/gabrielmittag/NISQA.git
2、conda env create -f env.yml
3、conda activate nisqa
4、创建输出文件的文件夹(输出文件为积分记录表),如输出文件夹在outputfile,就创建一个名为outputfile的文件夹;
5、在步骤4所创建的文件夹中,创建NISQA_outputfile.csv;
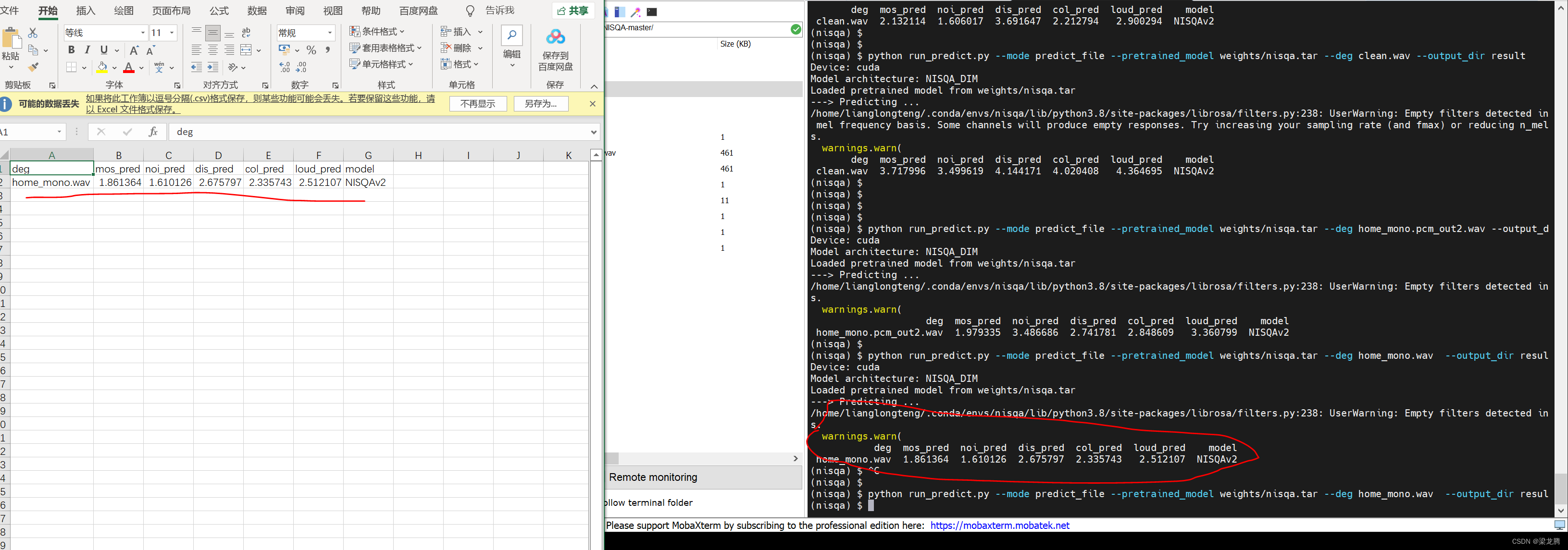
6、执行 python run_predict.py --mode predict_file --pretrained_model weights/nisqa.tar --deg test.wav --output_dir outputfile
predict_file:模式选择为推理模式,默认不用改;
weights/nisqa.tar:为推理时所用到的模型,默认不用改;
test.wav:需要评估的音频;
outputfile:音频评估分数表输出目录
结果图例:
MOSNET、SRMR
pip install numpy
pip install git+https://github.com/aliutkus/speechmetrics#egg=speechmetrics[cpu]
完成后输入以下脚本:
import speechmetrics
window_length = 20# seconds
reference = ‘test.wav’ #audio path
metrics = speechmetrics.load(‘absolute’, window_length)
scores = metrics(reference)
print(scores)
或直接使用以下脚本;
结果图例: