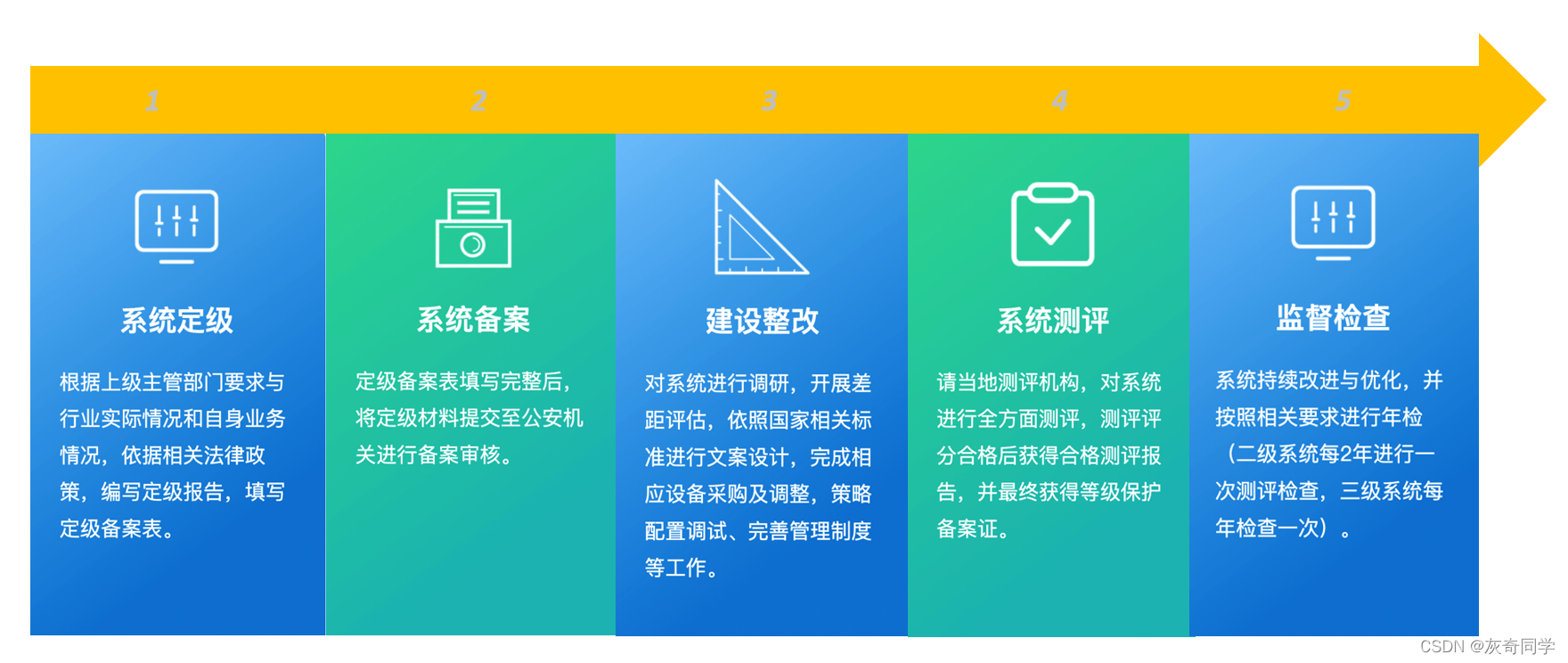
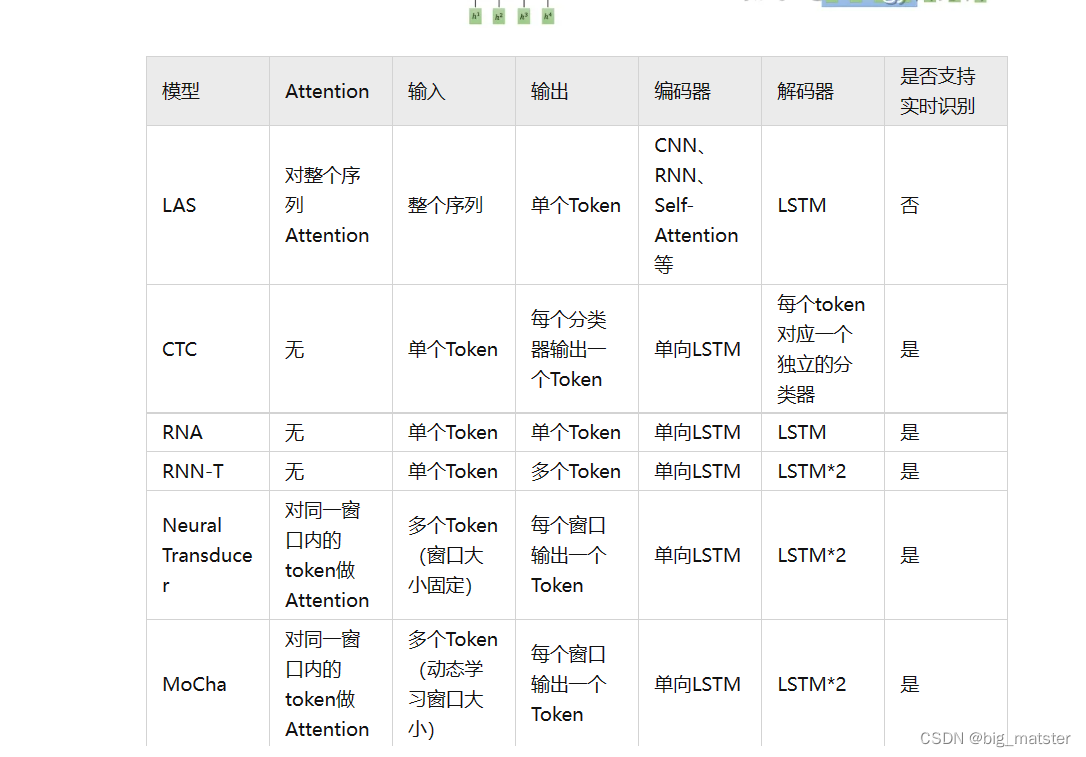
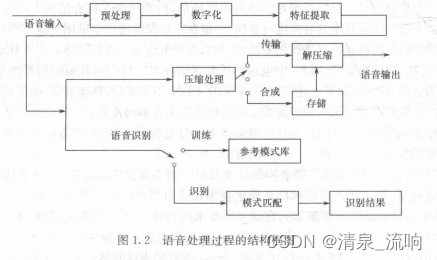
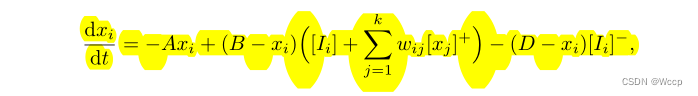文章目录
- 一、安装ffmpeg
- 二、安装torch等相关组件
- 三、安装Whisper
- 四、下载模型
- 五、测试效果
- 六、cpu与gpu解码的耗时对比
- 参考文献
一、安装ffmpeg
yum localinstall --nogpgcheck https://download1.rpmfusion.org/free/el/rpmfusion-free-release-7.noarch.rpm
yum install ffmpeg ffmpeg-devel
二、安装torch等相关组件
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2 -c pytorch
三、安装Whisper
pip install git+https://github.com/openai/whisper.git
如果上述报错,就改为下面的方法:
pip install --upgrade pip
git clone git@github.com:openai/whisper.git
cd whisper/
pip install setuptools-rust
pip install -r requirements.txt
python setup.py develop
四、下载模型
import whisper
model = whisper.load_model("large") # 此处会下载模型
模型的默认下载路径在:~/.cache/whisper/large-v2.pt
如果网速不佳,可以先在网速好的服务器上先下载好模型,再拷贝到本机
五、测试效果
从下面cpu的结果看,tiny模型的结果不忍直视,而large_model的耗时,也无法忍受。
| 模型名称 | cpu执行时间 | 结果 | gpu执行时间 | 占显存 |
|---|---|---|---|---|
| large_model | 15.5456秒 | 喂 王阳 能听到我说话吗 今天天气怎么样 | 超过16G | 超16G |
| medium_model | 9.1108秒 | 喂,王阳,想听到我说话吗?今天天气怎么样? | 1.7336秒 | 10G |
| small_model | 3.2420秒 | 喂,完了,那听到我说话吗?今天天气怎么样? | 1.1716秒 | 3.3G |
| base_model | 1.5984秒 | 喂 王雅能聽到我說話嗎今天天氣怎麼樣 | 0.3483秒 | 1.6G |
| tiny_model | 1.0238秒 | 喂 玩呀那听到我说话吗今天听见怎么样 | 0.2637秒 | 1.3G |
六、cpu与gpu解码的耗时对比
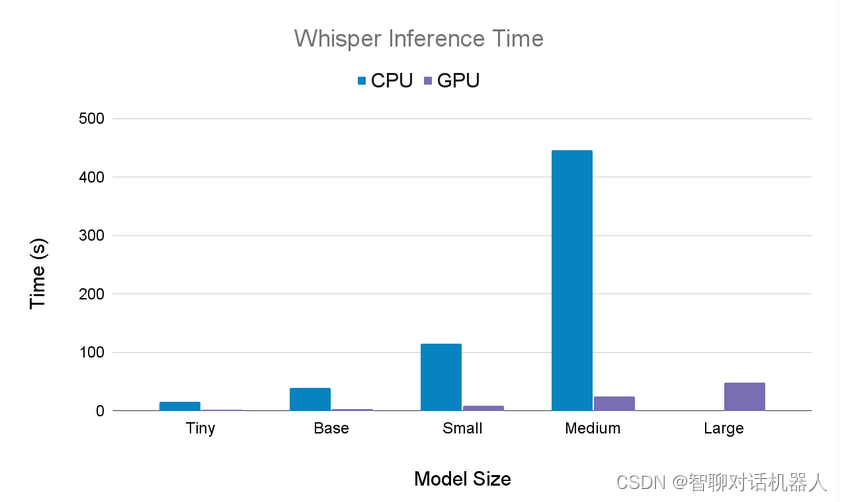
参考文献
- https://www.assemblyai.com/blog/how-to-run-openais-whisper-speech-recognition-model/
- https://github.com/AppleHolic/chatgpt-streamlit
- https://github.com/openai/whisper
- https://github.com/Joooohan/audio-recorder-streamlit