coding: utf-8
Google招聘需求分析
Google是技术人员梦寐以求的工作圣地,想进入Google,需要什么样的条件?Google在哪些地区有招聘机会?我们一起探索。
这个项目中,我们将处理以csv文件格式存储的数据。数据为从https://careers.google.com/ 爬取的google招聘职位需求。
载入文件
我们尝试使用Pandas的read_csv载入数据,并查看前面的几行内容。
In[1]:
import pandas as pdfile = "./data/job_skills.csv"df = pd.read_csv(file)df.head()
1.读取数据.png
从天气数据样本中,我们可以看到数据的一些特征
- Company:公司名字,这里绝大部分是Google
- Title:工作头衔
- Category:职位类别
- Location:工作地点
- Responsibilities: 职责
- Minimum Qualifications:最低要求
- Preferred Qualifications:加分项
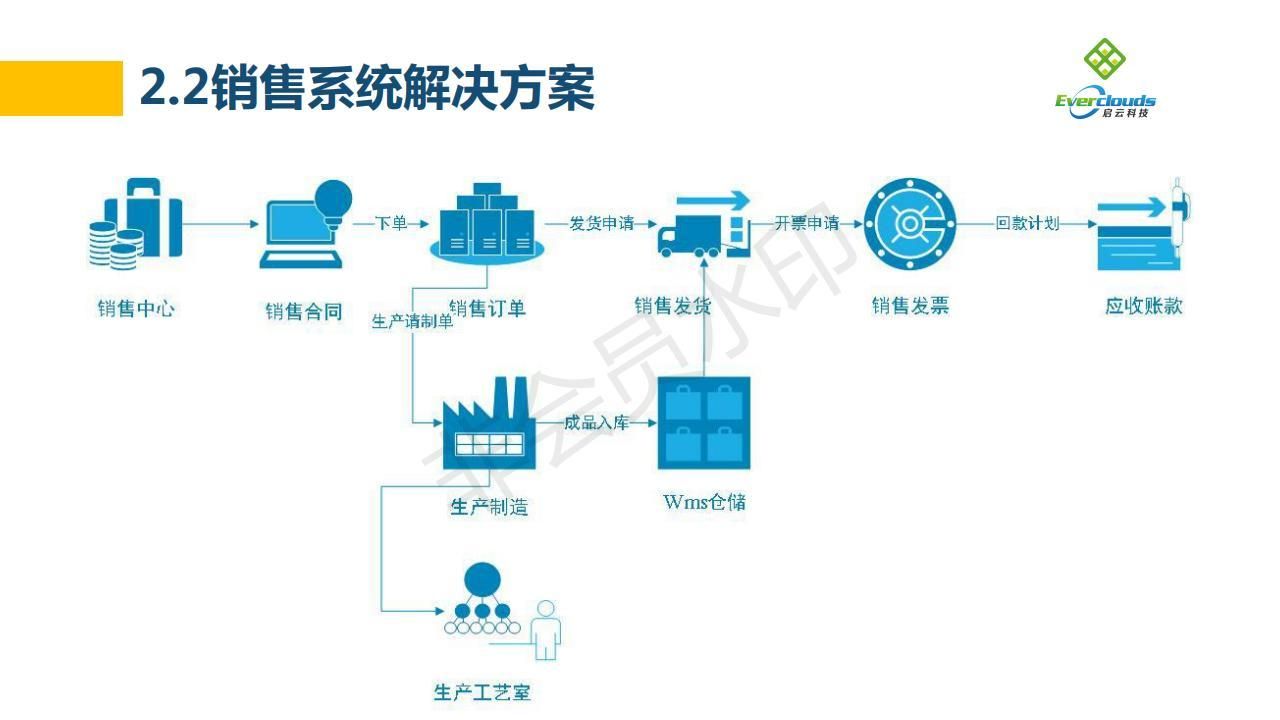
技能语言排名
尝试在Minimum Qualifications中,查找各编程语言出现的次数。
我们考察的语言包括python、java、c++、php、javascript、object-C、ruby、perl、c、c#、sql、swift、scala、r。
In[2]:
import re
# 定义语言列表
lang_list = ['python', 'java', 'c++', 'php', 'javascript', 'objective-c', 'ruby', 'perl', 'c', 'c#', 'sql', 'swift', 'scala', 'r']# 定义统计函数,输入字符串,从中提取包含的‘python’、'java'等语言单词的次数
def lang_count(miniumum_qualifications_string, lang_dict):'''该函数被以下all_lang_count调用,统计lang_dict中已经有的key在miniumum_qualifications_string中出现的次数。输入:miniumum_qualifications_string:str类型,被查询的字符串()'''# 从miniumum_qualifications_string中提取单词(可以参考Python正则表达式文档: https://docs.python.org/3/library/re.html)# 将如下re.sqlit中的第一个参数修改为正确的表达式,split 方法按照能够匹配的子串将字符串分割后返回列表""""+?" 重复1次或更多次,但尽可能少重复\.| 匹配文本中的“.”| | 匹配空格|\s| 匹配空白,即空格,tab|\n| 匹配换行|\/| 匹配斜杠|\r| 匹配回车|\(| 匹配左括号|\) 匹配右括号|\v| 匹配纵向制表符 |"""for w in re.split(r'[\.| |,|;|\s|\n|\/|\r|\(|\)]+?', miniumum_qualifications_string):# 如果单词为lang_list中的某一种语言(注意单词大小写问题),将字典lang_dict对应项累加for lang in lang_list:if w.lower() == lang:lang_dict[lang] += 1def all_lang_count(df):'''统计Minimum Qualifications列的内容中,语言出现的次数输入:df:DataFrame,其中包含Minimum Qualifications列。输出:字典类型,其中key为语言名字如'python'、'java'等,value为单词在Minimum Qualifications中出现的次数。'''# 初始化字典变量lang_dict, 以lang_list中的语言名字为key,出现次数为0lang_dict = {'python':0, 'java':0, 'c++':0, 'php':0, 'javascript':0, 'objective-c':0, 'ruby':0, 'perl':0, 'c':0, 'c#':0, 'sql':0, 'swift':0, 'scala':0, 'r':0}# 对于Minimum Qualifications列中的每一项,调用lang_count方法for word in df['Minimum Qualifications']:lang_count(str(word), lang_dict)return lang_dictlang_dict = all_lang_count(df)print(lang_dict)
2.各编程语言出现的次数.png
In[4]:
import matplotlib.pyplot as plt
# 解决图形显示中文乱码问题
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 对lang_dict.items()按照value所对应项进行排序并生成到新的列表变量lang_sorted中
lang_sorted = sorted(lang_dict.items(),key=lambda d:d[1],reverse=True)# 根据计算出的lang_sorted生成新的DataFrame
df_lang_sorted = pd.DataFrame(lang_sorted, columns = ['Language', 'Pop'])# 将Language设置为df_lang_sorted的index以便绘图时作为横坐标标签
df_lang_sorted.set_index(['Language'],inplace=True)# 绘制df_lang_sorted柱形图
ax = df_lang_sorted.plot(kind='bar', title ="Google招聘考察各编程语言出现的次数分布图",figsize=(10,5),legend=True, fontsize=12)
ax.set_xlabel("编程语言",fontsize=12)
ax.set_ylabel("次数",fontsize=12)
plt.show()
3.Google招聘考察各编程语言出现的次数分布图.png
从图形结果当中,我们可以看到,需求量排名前三的语言是Python、JavaScript和Java
更仔细的探索数据
对数据进行初步的统计得到以上结果,看起来比较惊喜。
让我们仔细看看一些数据的细节。
首先,检查下数据中包含多少空值。
In[5]:
pd.isnull(df).sum()
4.检查数据中包含的空值.png
去除空值项
In[6]:
df = df.dropna()
df.describe()
5.去除空值项.png
观察一下Company列
在执行df.head结果之后,我们可以发现Company列中的unique为2,这里除了Google,还有另外一家公司。
看看另一家是什么:
In[7]:
df['Company'].value_counts()
6.查看Company列中包含的公司.png
可以看到这里还有一家是YouTube,也是被Google收购了的金牌雇主。
为了分析,先不管这么多,把YouTube相关的行数据去掉。
In[8]:
# 去掉df中Company列为YouTube的数据
df = df[~df['Company'].isin(['YouTube'])]df.describe()
7.去掉Company列为YouTube的数据.png
观察其它列的大概状况
In[9]:
# Title列
df['Title'].value_counts().head(10)
8.观察Title列的统计情况.png
In[10]:
# 使用value_counts观察Location列的统计状况
df['Location'].value_counts().head(10)
9.观察Location列的统计状况.png
In[11]:
# 使用value_counts观察Category列的统计状况
df['Category'].value_counts().head(10)
10.观察Category列的统计状况.png
工作年限
粗略计算
In[12]:
from collections import defaultdict# 使用defaultdict构建value默认值为0的字典
years_exp = defaultdict(lambda: 0)# 定义统计函数,输入字符串,从中提取包含的xxx year字样的情况下期中xxx所描述的数字
def compute_years_exp(miniumum_qualifications_string):# 从miniumum_qualifications_string中提取xxx year中的xxx(可以参考Python正则表达式文档: https://docs.python.org/3/library/re.html)# 然后以年数(xxx)为key,将years_exp中的相应元素value加1。for w in re.findall(r'([0-9]+) year', miniumum_qualifications_string):years_exp[w] += 1# 对于Minimum Qualifications列中的每一项,调用lang_count方法
for word in df['Minimum Qualifications']:compute_years_exp(str(word))print(dict(years_exp))
11.查看各工作年限出现的次数.png
In[13]:
# 对dict(years_exp)按照value进行排序并生成到新的列表变量years_exp_sorted中
years_exp_sorted = sorted(years_exp.items(),key=lambda d:d[1],reverse=True)# 根据计算出的years_exp_sorted生成新的DataFrame,列名为Years以及Pop
df_years_exp_sorted = pd.DataFrame(years_exp_sorted, columns = ['Years', 'Pop'])# 将Years设置为df_years_exp_sorted的index以便绘图时作为横坐标标签
df_years_exp_sorted.set_index(['Years'],inplace=True)# 绘制df_years_exp_sorted柱形图
ax = df_years_exp_sorted.plot(kind='bar', title ="Google招聘考察各工作年限出现的次数分布图",figsize=(10,5),legend=True, fontsize=12)
ax.set_xlabel("工作年限",fontsize=12)
ax.set_ylabel("次数",fontsize=12)
plt.show()
12.Google招聘考察各工作年限出现的次数分布图.png
从图形结果当中,我们可以看到,需求量排名前二的工作经验年限是5年和3年
逐行处理
针对每一行,生成一个新列Minimum_years_experience,从当前行的Minimum Qualifications列中,提取xxx year 字样前面的xxx
In[14]:
# 生成df['Minimum_years_experience'],每行元素为对应行的Minimum Qualifications这列中xxx year 字样前面的xxx。
# df['Minimum_years_experience']每个元素的类型为列表
df['Minimum_years_experience'] = df['Minimum Qualifications'].apply(lambda x: re.findall(r'([0-9]+) year',x))df.head()
13.提取Minimum Qualifications列中要求的工作经验.png
从结果中,我们可以看出,某些行会提取出多个数字,某些行却一个数字也提取不出来,需要做进一步处理。
空值填充
将df['Minimum_years_experience']中的[]转换成[0]
In[15]:
# 将df['Minimum_years_experience']中的[]转换成[0],(提示:可以使用apply)
df['Minimum_years_experience'] = df['Minimum_years_experience'].apply(lambda x: [0] if len(x)==0 else x)df.head()
14.将df['Minimum_years_experience']中的[]转换成[0].png
处理多值
当df['Minimum_years_experience']中出现多个元素时,比如[x, y, z],将df['Minimum_years_experience']转换成[max(x, y, z)]
In[16]:
# 当df['Minimum_years_experience']中出现多个元素时,比如[x, y, z],将df['Minimum_years_experience']转换成[max(x, y, z)]
def find_maximum(years):yearList = []for year in years:yearList.append(int(year))return max(yearList)
df['Minimum_years_experience'] = df['Minimum_years_experience'].apply(find_maximum)df.head()
15.将df['Minimum_years_experience']转换成[max(x, y, z)].png
In[17]:
# 基于df['Minimum_years_experience']数据,绘制箱线图。
# 注意:如果元素类型非数值类型,绘制箱线图会失败,需要使用astype对元素类型进行转换。
df['Minimum_years_experience'] = df['Minimum_years_experience'].astype(float)
ax = df['Minimum_years_experience'].plot(kind='box', title ="Google招聘各工作年限需求箱线图",figsize=(10,5),legend=True, fontsize=12)
ax.set_ylabel("工作年限",fontsize=12)
plt.show()
16.Google招聘各工作年限需求箱线图.png
从箱线图结果看,需求的工作年限的中位数是2年
查看分析师岗位相关数据
我们从Title中查找包含'Analyst'关键字的职位需求。
In[18]:
# 从Title中查找包含'Analyst'关键字的职位,存储到df_Analyst中。
df_Analyst = df[df['Title'].str.contains('Analyst')]df_Analyst.head()
17.从Title中查找包含'Analyst'关键字的职位.png
In[19]:
# 查看下分析师需求的位置分布情况
df_Analyst['Location'].value_counts()
18.查看下分析师需求的位置分布情况.png
添加国家信息
在位置信息中,最后一个逗号后面为国家名,我们对Location进一步分组。
在df_Analyst中生成一个新列'Country',从Location中,将最后一个逗号后面的值提取出来,作为该列的值。
In[20]:
# 生成新列df_Analyst['Country'],其中内容为df_Analyst['Location']中截取最后一个逗号之后的内容
df_Analyst['Country'] = df_Analyst['Location'].apply(lambda x: re.split(r',',x)[-1])df_Analyst['Country'].value_counts()
19.从工作地点中统计各个国家出现的次数.png
需求量排在前4的国家是United States, Switzerland, Ireland, United Kingdom
统计数据分析师的语言技能需求
In[21]:
print(all_lang_count(df_Analyst))
20.统计数据分析师的语言技能需求.png
In[22]:
df_Analyst_count = all_lang_count(df_Analyst)# 对df_Analyst_count按照value进行排序并生成到新的列表变量df_Analyst_sorted中
df_Analyst_sorted = sorted(df_Analyst_count.items(),key=lambda d:d[1],reverse=True)# 根据计算出的df_Analyst_sorted生成新的DataFrame,列名为analyst_lang以及Pop
df_Analyst_sorted = pd.DataFrame(df_Analyst_sorted, columns = ['analyst_lang', 'Pop'])# 将analyst_lang设置为df_Analyst_sorted的index以便绘图时作为横坐标标签
df_Analyst_sorted.set_index(['analyst_lang'],inplace=True)# 绘制df_Analyst_sorted柱形图
ax = df_Analyst_sorted.plot(kind='bar', title ="Google招聘数据分析师的语言技能出现的次数分布图",figsize=(10,5),legend=True, fontsize=12)
ax.set_xlabel("语言技能",fontsize=12)
ax.set_ylabel("次数",fontsize=12)
plt.show()
21.Google招聘数据分析师的语言技能出现的次数分布图.png
对于数据分析师,sql语言的要求最高
透视表
构建透视表,探寻不同国家对于数据分析师的工作年限需求。
透视表index为二级索引,第一级是国家('Country'),第二级是职位分类('Category'),values是'Minimum_years_experience'。当生成表时出现元素冲突时,定义mean为aggfunc。
In[23]:
import numpy as np
# 定义透视表category_country,以df_Analyst的Country和Category为二级索引,Minimum_years_experience为value,aggfunc为mean
category_country = df_Analyst.pivot_table(index=['Country','Category'],values=['Minimum_years_experience'],aggfunc=np.mean)category_country
22.不同国家对于数据分析师的工作年限需求.png
中国的职位需求中,其对应的Category是Partnerships,要求的最低工作年限是2年。

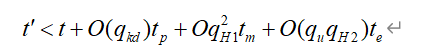

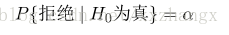


![[Mathpix乱码]关于利用Mathpix粘贴Mathtype数学公式进Word造成乱码和问号问题的解决方案。](https://img-blog.csdnimg.cn/1aa4f46513764cb789ae589e1d6b46ee.png)