语音相似度评价是用于测量语音之间的相似程度,常使用的算法是动态时间规整(Dynamic time warping,DTW),其原理是通过对齐时间序列来评估它们之间相似性。DTW是一种基于对齐的度量(alignment-based metric)与常见的欧式距离不同,DTW考虑到了时间维度上的信息,因此常用在信号处理领域,比如说话人识别,语音识别等。

下面举个例子解释为什么要用DTW而不是欧式距离,这里我们有一个时间序列的数据集,包含了一些不同的样式。如果我们要对其进行分类,简单的方法就是使用聚类算法,首先采用欧式距离作为度量,我们可以得到如下的结果:

容易发现在第二类中存在一些格格不入的样式;我们看下采用DTW聚类后的结果:

可以明显的发现,DTW聚类后的结果,每个类别的差别(类间聚类)比较小。
Dynamic Time Wrap
DTW是基于距离最近原则衡量两个长度不同的时间序列的相似度的方法,是一种非线性规整技术,需要满足以下几个条件:
-
单向对应,不能回头,从前往后对齐
-
两个序列首元素必须对应(但它不一定是唯一的匹配项)
-
序列中的元素一一对应,中间不能有空元素
-
对应之后,距离最近
DTW问题可以形式化的表示为
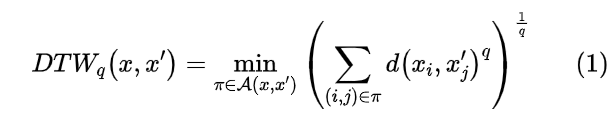
其中π表示对齐路径。如果我们直接使用穷举法,其时间复杂度是

为了减少计算量,我们采用动态规划的方式求解,其解法可以表示为:

具体流程为:

如果读者刷过Leetcode的话,应该会发现上面的描述有点像一道Hard的题目——最小编辑距离,这是比较经典的动态规划问题,因此这里就不再详细介绍了。
Experiment
下面我们做个简单的实验,首先我们有两个音频,如下所示


然后我们对第二个音频进行一些处理,首先利用超级变变变之变声器的原理对其进行慢放,然后加入一些白噪声,最后在开始增加一些延迟得到如下的音频。

如果直接在时域进行计算那么计算量太大了,我们提取音频的128维的melspectrum进行简化计算。最后看下结果,dtw_hospital和dtw_number如下所示,可以看到,其最终的距离非常大,并且对其的结果和对角线相差较大。

我们再看看下dtw_number和dtw_number_noise规整后的结果,可以看到,对齐路径基本接近对角线且最终的距离比上面要小很多。

上面介绍了基本的DTW算法,除此之外还有一些改进算法,比如对规整路径进行一些限制或者增加权重等从而得到更优的结果,更详细的内容可以查阅参考文献[4]。
本文相关代码公众号语音算法组菜单栏点击Code获取
参考文献:
[1]. https://rtavenar.github.io/blog/dtw.html
[2]. https://www.kdnuggets.com/2022/05/dynamic-time-warping-algorithm-time-series-explained.html
[3]. https://blog.csdn.net/qq_36002089/article/details/115520550
[4]. Dynamic Time Warping Algorithm Review