1、前言
新浪微博中,一个话题下各个媒体或用户发表在平台发表的信息是舆情研究的一个很重要的数据来源,这里记录一下一个话题下数据的爬取方式,以“#美国疫情#”话题为例。
2、话题下数据爬取
首先参考这篇文章,分析话题下数据爬取的结构,然后仿照示例得到如下代码:
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
import time
import xlwt#设置代理等(新浪微博的数据是用ajax异步下拉加载的,network->xhr)
host = 'm.weibo.cn'
base_url = 'https://%s/api/container/getIndex?' % host
user_agent = 'Mozilla/5.0 (Linux; Android 5.0; SM-G900P Build/LRX21T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Mobile Safari/537.36'#设置请求头
headers = {'Host': host,'Referer': 'https://m.weibo.cn/search?containerid=231522type%3D1%26q%3D%23%E7%BE%8E%E5%9B%BD%E7%96%AB%E6%83%85%23','User-Agent': user_agent
}# 按页数抓取数据
def get_single_page(page):#请求参数params = {'containerid': '231522type=1&q=#美国疫情#','page_type': 'searchall','page': page}url = base_url + urlencode(params)try:response = requests.get(url, headers=headers)if response.status_code == 200:return response.json()except requests.ConnectionError as e:print('抓取错误', e.args)# 解析页面返回的json数据
global count
count = 0
def parse_page(json):global countitems = json.get('data').get('cards')for item in items:item = item.get('mblog')if item:data = {'id': item.get('id'),'created': item.get('created_at'),'text': pq(item.get("text")).text(), # 仅提取内容中的文本}yield datacount +=1if __name__ == '__main__':workbook = xlwt.Workbook(encoding='utf-8')# 创建一个表格worksheet = workbook.add_sheet('美国疫情')for page in range(1, 200): # 瀑布流下拉式,加载200次json = get_single_page(page)results = parse_page(json)tmp_list = []print(count)for result in results: #需要存入的字段worksheet.write(count, 0, label=result.get('created').strip('\n'))worksheet.write(count, 1, label=result.get('text').strip('\n'))time.sleep(1) #爬取时间间隔workbook.save('conv.xls')3、展开全文解决方法
仅用以上方法爬取存在一个弊端:如果文章过长,界面上就会出现“展开全文”字样,用此方法无法爬取到长文本。
观察字段,存在isLongText布尔型字段:
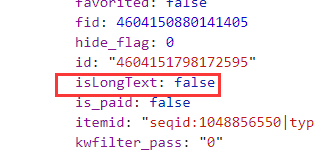
“展开原文”部分实际上是一个链接,组成方式为“https://m.weibo.cn/status/”+id,这个id是被爬取的文章对应的id,因此需要在爬取之前判断是否为长文本,如果是,则需要根据响应的id跳转到对应的页面再次爬取,完善部分代码片段:
#长文本爬取代码段
def getLongText(lid): #lid为长文本对应的id# 长文本请求头headers_longtext = {'Host': host,'Referer': 'https://m.weibo.cn/status/' +lid,'User-Agent': user_agent}params = {'id' : lid}url = 'https://m.weibo.cn/statuses/extend?' +urlencode(params)try:response = requests.get(url, headers=headers_longtext)if response.status_code == 200: #数据返回成功jsondata = response.json()tmp = jsondata.get('data')return pq(tmp.get("longTextContent")).text() #解析返回结构,获取长文本对应内容except requests.ConnectionError as e:print('抓取错误', e.args)# 解析页面返回的json数据
global count
count = 0'''
修改后的页面爬取解析函数
'''
def parse_page(json):global countitems = json.get('data').get('cards')for item in items:item = item.get('mblog')if item:if item.get('isLongText') is False: #不是长文本data = {'id': item.get('id'),'name': item.get('user').get('screen_name'),'created': item.get('created_at'),'text': pq(item.get("text")).text(), # 仅提取内容中的文本'attitudes': item.get('attitudes_count'),'comments': item.get('comments_count'),'reposts': item.get('reposts_count')}else: #长文本涉及文本的展开tmp = getLongText(item.get('id')) #调用函数data = {'id': item.get('id'),'name': item.get('user').get('screen_name'),'created': item.get('created_at'),'text': tmp, # 仅提取内容中的文本'attitudes': item.get('attitudes_count'),'comments': item.get('comments_count'),'reposts': item.get('reposts_count')}yield datacount +=14、总结
话题下数据爬取相对简单,且不涉及用户登录,但数据爬取间隔过快,或者爬取次数过多,ip会被封掉,另外数据爬取工具也有很多,比如爬山虎不一定非要自己编程实现。