精读这篇文章你就能知道什么是NER,并且可以学会在开发任务中使用NER
目录
1、chatGPT对NER的解释
2、NER任务
3、NER标注工具Doccano
1、chatGPT对NER的解释
命名实体识别(Named Entity Recognition,NER)是自然语言处理领域的一项关键任务,旨在从文本中识别和分类特定的命名实体,如人名、地名、组织机构名等。NER的目标是标记文本中的实体,并将其归类到预定义的实体类型中。
NER通常使用机器学习和深度学习技术来完成任务。以下是一种常见的NER流程:
-
数据收集和标注:收集包含命名实体的文本数据,并为每个实体标注相应的标签(实体类型)。
-
特征提取:从文本数据中提取有用的特征,如词性、词形、上下文等。这些特征将作为输入提供给模型。
-
模型训练:使用标注好的数据和提取的特征来训练NER模型。常用的模型包括条件随机场(CRF)、循环神经网络(RNN)、长短期记忆网络(LSTM)、卷积神经网络(CNN)和注意力机制(Attention)等。
-
模型评估和调优:使用评估数据集来评估训练得到的模型性能,并进行调优以提高准确性和召回率。
-
实体识别:使用训练好的NER模型对新的文本进行实体识别。模型将识别并标记文本中的命名实体,使其易于提取和理解。
NER在许多应用中起着重要作用,例如信息抽取、问答系统、文本摘要、机器翻译等。它可以帮助自动化处理大量文本数据,并提供有关实体的结构化信息,为后续的分析和应用提供基础。
2、NER任务
对这句话进行一个词的抽取:今天晚上我吃了一只鸭
- 今天 是一个时间
- 我 是一个人
- 鸭 是一个动物
我想对一个文本数据中抽取出一个关键知识
我现在将(时间,人,动物)构建一个三元组行分类,最终定为几类是你在任务中自己定义的,这里的三分类只是举例而已。
分别表示(什么时间,谁,对谁),进行关键信息抽取,那我们解决这个任务的模型就需要知道哪些词是关键信息。那今天这个词是一个时间还是人还是动物就是一个三分类,然后后面的每个词晚上、我、吃了、一只都需要进行三分类。所以虽然是叫NER,但是实际上就是一个对Token的分类任务。
Token可以这么理解,在NLP中,拿到一句话无论做什么预处理的工作,第一件事都需要做分词。
那前面那句话举例:
今天晚上我吃了一只鸭
1今天 2晚上 3我 4吃了 5一只 6鸭
这句话进行分词处理就应该是这个结果。对Token进行分类就是把每个词对应的类别是什么做一个映射。Token分类就是对每一个词都进行类别标注,这个过程就叫做一个命名体识别。
所以文本的分类需要人工进行标注。
3、NER标注工具Doccano
3.1安装
Doccano是一个非常好用的开源工具,用起来很方便,安装也不麻烦。
首先不要着急去查百度,在github就有安装说明。
安装说明:
- pip (Python 3.8+)
- Docker
- Docker Compose
pip (Python 3.8+),要求Python环境是3.8以上,但是如果你深度学习环境一套都是3.8以下的,你新建一个python环境就行了,这个工具就只需要标注文本,标注的时候切换到Doccano环境就行了。
在prompt中先进入你安装的python环境的scripts文件夹(每个conda的python环境都有一个script文件夹)中,在prompt界面进行操作:

安装指令:
pip install doccano先进行初始化操作:
# Initialize database.
doccano init设置用户名和密码:
# Create a super user.
doccano createuser --username admin --password pass接着设置服务器端口:
# Start a web server.
doccano webserver --port 8000这步做完后,再打开一个prompt命令窗口,启动服务:
# Start the task queue to handle file upload/download.
doccano task服务启动成功后,进入服务器
(这个界面有些内容介绍你也可以自己去看看)点击右上角进行登陆,登陆的账号密码就是刚刚设置的。
可以看到自己的标注项目了:

可以切换语言,创建项目,我们创建序列的项目就好了:
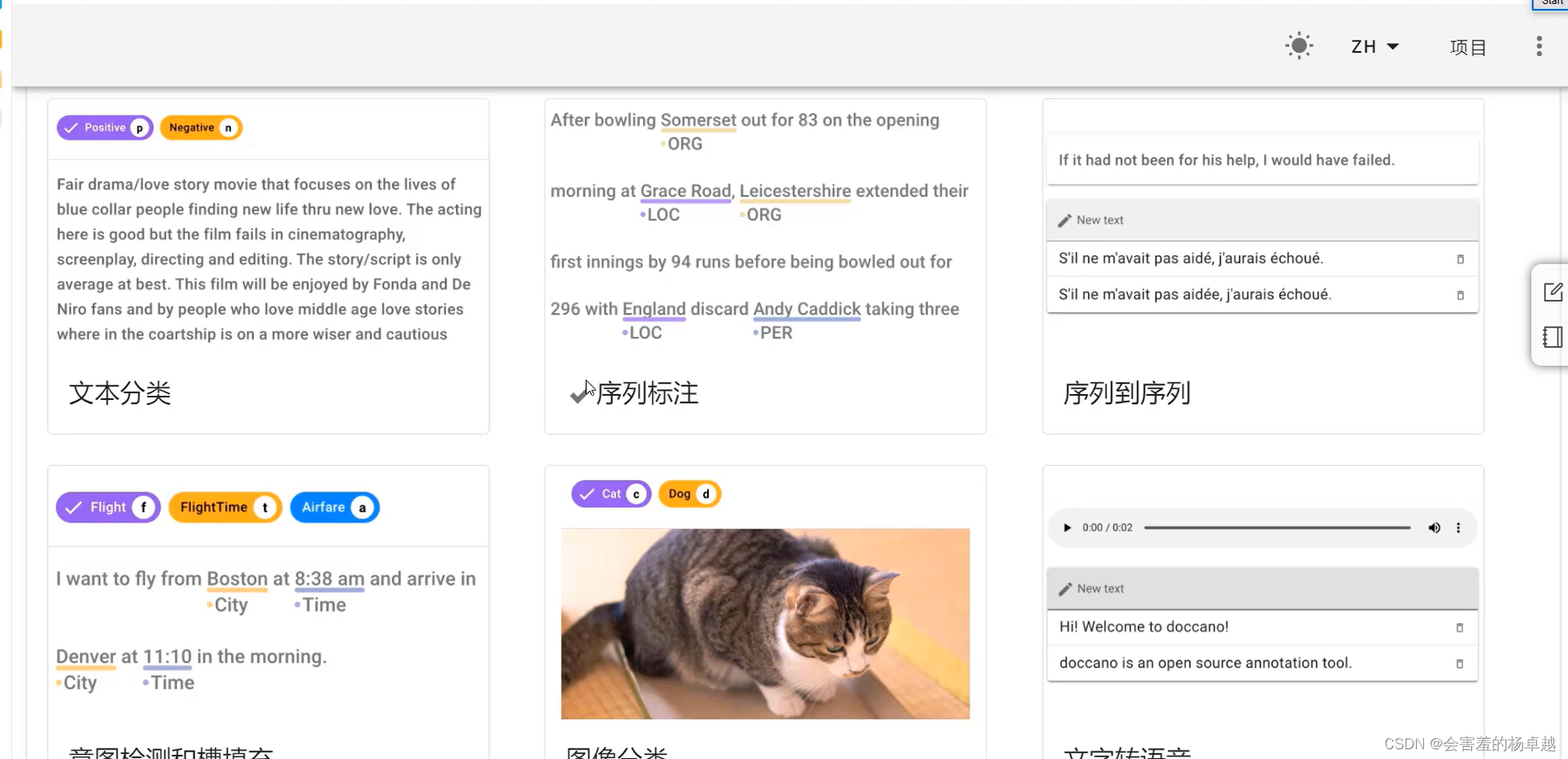
(更新中,可以先收藏)