原文:《基于深度学习的图像语义分割方法综述》2019_田萱,引用量=19
1.简介
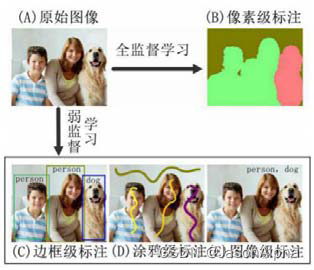
是什么:ISS 为图像中的每一个像素分配一个预先定义好的表示其语义类别的标签。(田萱,2019)
与目标检测区别?——相似点:都标注了物体的具体分类信息。不同点:ISS是像素级颗粒度的,需要把物体的轮廓描绘出来,用轮廓来标记物体。OD标记物体是其外切框。
与实例分割的区别?——如果一张照片中有多个人,对于语义分割来说,只要将所有人的像素都归为一类--人这一类Person。但是实例分割还要将不同人的像素归为不同的类,Person1,Person2,Person3。也就是说实例分割比语义分割更进一步。


学术意义:ISS是计算机视觉领域的几大核心研究之一,其他的还有图像分类、物体识别检测。(田萱,2019)
工程意义:ISS 在虚拟现实(virtual or augmented reality systems)、工业自动化、视频检测、移动机器人(robots)、无人机(drones)、自动驾驶(autonomous driving)以及智慧安防有广泛的应用。(田萱,2019)
2.Existing Methods

1 Regional Cl.
这篇综述,将基于区域分类的方法也划分成了语义分割,我个人觉得是不合适的。语义分割应该是基于像素的,用object边缘来划分,而不是说用方框划分。这是目标检测,而不是语义分割。我猜测应该是这篇综述的作者为了凑字数、凑内容,为了让内容显得充实,把ISSbRC也拿进来作为语义分割的一种。
1.1 候选区域 :
是什么:-S1-先用区域生成算法(如“:selective search算法)得到一系列(如:2000个)候选区域,这个区域生成算法保证了每个候选区域都有可能包含潜在的目标物体。-S2-再用CNN提取各个候选区域的特征,-S3-然后再用分类器(如SVM)分类。
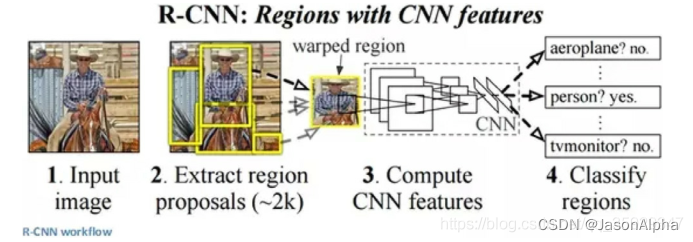
优点:同时完成目标检测与图像语义分割两项任务
缺点:(1)没有充分考虑图像中的全局语义信息(整个图片被分成了一小块一小块了,自然无法捕捉到这一小块和其他小块的关系), (2)分类图像中的小尺度物体和小面积区域时易出错。
1.2 Segmentation Mask:
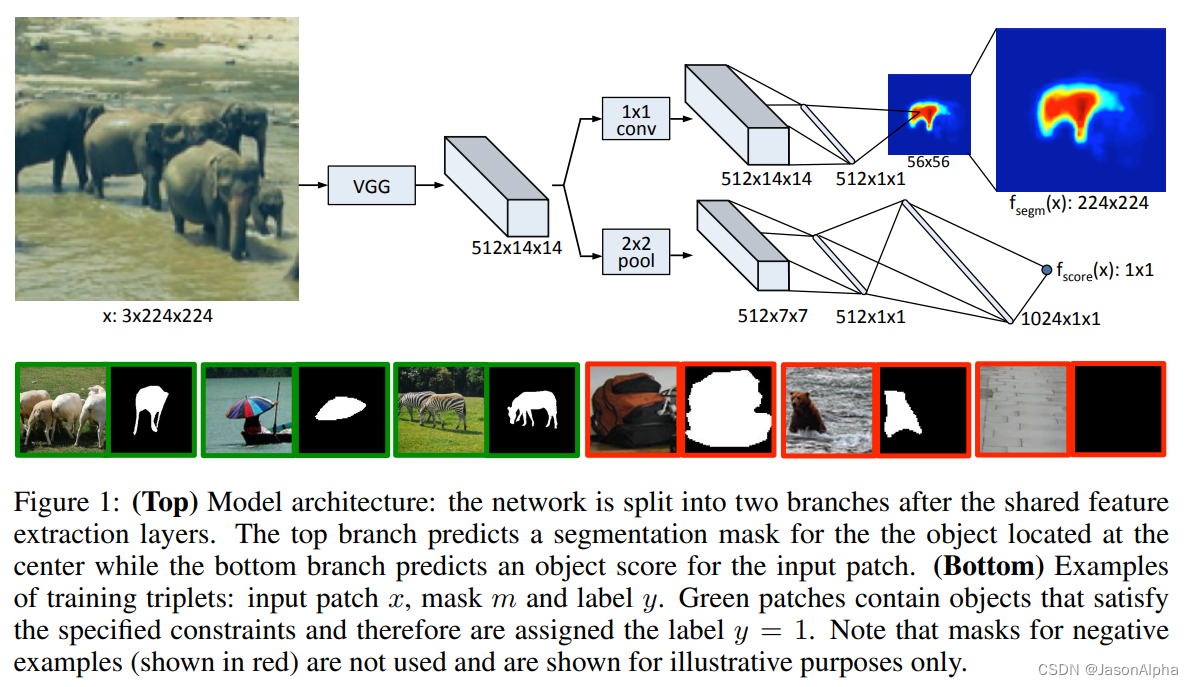
是什么:-S1-先通过目标检测方法(RCNN、DeepMask、MultiPath)识别出图像中潜在的目标候选对象,并且把他们从原有的大图片中把他们切成带有目标候选对象的小图片patch;-S2-利用RCNN等目标检测技术,通过对目标候选区域中的像素进行二分类,得到分割掩码-S3-使用精炼模块,对多张分割掩码进行优化处理,得到分割结果。
——segmentation mask的意思是,将对象object的区域像素值变成1,也就是白色;是背景的区域把像素值变成-1,也就是黑色;
——training set的每一条数据都是一个三元组triplet,包含三项数据。[1]x,每一个patch图片的每个像素的RGB值[2]m,每个像素点的segmentation mask值,-1或1,[3]y,每张图是否包含object,并且遵循下面两条要求,不包含取-1,包含取1。
——[1]object大致在图片的中央,在边缘位置不行[2]object的所有部分都要在这张图片里,如果图片中的object露一半,object的另一半在图片外,也不行
——模型训练过程.....,分为两个并行的任务。上面的任务通过 segmentation mask进行分割,把object从背景里面切出来。下面的任务负责打分score。score表示 the likelihood of 这个图片按照要求包含一个object。segmentation mask预测和score的预测,二者同时进行优化learn jointly。
优点:可以挖掘多种尺寸、背景图片中的隐含信息
缺点:下列情况准确率较低[1]小尺寸物体、[2]被遮挡物体、[3]背景复杂的图片
2 Pixel Cl.
——与ISSbRC的区别是:ISSbRC先将原始图像划分成不同的目标候选区域,得到一系列图像块(image patch),再对图像块或图像块中的每个像素进行语义分类。ISSbPC是直接在像素级别上进行图像语义分割,省去了“产生目标候选区域”这一步骤。ISSbPC的出现是源于ISSbRC出现的下列问题,图像分割精度不高和分割速度不够快。
2.1 Fully Supervised Learning
——全监督和弱监督学习的区别是什么?
——ISSbFSL使用的训练数据是经过人工精确加工的像素级标注;ISSbWSL使用的训练数据是弱标注的数据。
1 FCN
( Fully Convolutional Networks )
2 优化卷积
3 Encoder-Decoder
4 概率图
5 特征融合
6 RNN
7 GAN
2.2 Weakly Supervised Learning

——优势:经过粗略标记的弱标注图像进行训练,减少了标注时间和标注成本
1 边框bounding-box级标注
2 涂鸦scribble级标注
3 图像级标注tag-level
是什么:
图像级标注只提供了物体种类信息,缺少位置、形状等信息。(应该给一张图,把图里面的 ,目标的标签名写出来only provide object categories,不标注这些类别的东西在哪里)
4 多种弱标注数据混合
是什么:
将多种弱标注图像与像素级标注图像相互混合,通过混合训练的方式进行半监督学习.
3.数据集和评价指标
11个数据集,3个性能评价指标(2019,田萱)
2D数据集,2.5D数据集,3D数据集(2017,Garcia)
Accuracy
Pixel Accuracy (PA),Mean Pixel Accuracy (MPA),Mean Intersection over Union (MIoU),Intersection over Union (IoU),(前面这几个所有文献综述都有),Frequency-Weighted Intersection over Union (FWIoU).(2019,Hao独有)
Execution Time
Memory Footprint
4.有前景的研究方向
——[1]痛点[2]解决方案[3]目前方法有待改进的地方
(1)应用于场景解析任务的图像语义分割
痛点:场景解析任务处理的图像背景复杂、环境多变。现有 ISSbDL 方法无法有效地捕获图像的上下文信息和深度语义信息,在识别和分割图像中目标物体时仍存在较大的困难.
目前方法有待改进的地方:难以选择标注基元量化级别、未充分利用场景几何深度等问题,
(2)实例级图像语义分割
是什么:实例级图像语义分割,也称为实例分割(instance segmentation,简称 IS),融合了分割与检测两个功能,可以分割出图像中同类物体的不同实例.
(3) 实时图像语义分割
是什么:实时图像语义分割以极高的分割速率处理图像或视频数据,并分析利用各图像(帧)之间的时空关系,是一 种以高分割速率运行的 ISS 机制.
有什么用途:常被应用于视频跟踪和多目标定位等任务,有巨大的商业价值,
痛点:提高实时图像语义分割的速度与精度,
(4) 应用于三维数据的语义分割
痛点:[1]做这个方向的论文少。. [2]数据预处理困难:由于三维数据的无序性和非结构化本质,如何合理离散化和结构化这些数据并有效地保留其空间位置信息,.[3]大规模数据集难以获取
(5) 应用于视频数据的语义分割
痛点:[1]充分利用视频丰富的 时空序列特征,从视频高效抽取高层语义信息[2]做这个方向的论文少。.
_______________
怎么读论文
阅读论文的顺序:
标题、abstract、结论、小标题+图表-浏览跳读([1]看的过程中标注什么要看、什么没必要看;[2]看的过程中你有什么必须要回答的问题)、回答这些问题、把标注的重点部分看了-提取有效信息
寻找哪些信息:
(1)什么是语义分割;(2)有哪些分割的场景,你不可能做的场景进行标注-少在上面花时间(3)每种场景在历史上哪些主流的、里程碑意义的方法[一句话一个技术带过,不可深究](4)目前最前沿、最新的方法,列列技术名字和时间--最多加一个核心思想(5)目前需要改进的地方有哪些?(6)常用数据集、性能评价指标
不看什么
(1)你一定不可能做的方向的技术实现和解释细节,不要看(2)过于古早的技术的技术细节不要看(3)已经懂的东西不要看,比如深度学习的发展历程,什么是CNN RNN(4)不要扣细节,抓住每个模块的精髓和主干---先列一个模块的所有标题,然后每个标题分配不同的关注度权重(5)过于偏门和古怪的方法不要看细节(6)一切细节除非特别重要,需要报告我审批,否则一律不许看,可以标注下来,以后需要的时候过来查字典一样查---掌握最最主要、最最重要的东西即可,等你要用哪个细分的方法的时候--你记得这篇文章讲过这个东西--你再回来看-回来查——如果一直都用不到--说明这个东西就没有看的必要
还没读完的论文-6
2022_Mo_Cite=18_Review the state-of-the-art technologies of semantic segmentation based on deep learning.pdf
3. Weakly-supervised semantic segmentation
3.1. Segmentation algorithm based on image-level labels
3.2. Segmentation algorithm based on bounding-box
3.3. Segmentation algorithm based on scribble
3.4. Segmentation algorithm based on point
4. Domain adaptation in semantic segmentation
4.1. Input-level domain adaptation
4.2. Feature-level domain adaptation
4.3. Output-level domain adaptation
5. Semantic segmentation based on multi-modal data fusion
5.1. Fuse RGB and thermal/depth images
5.2. Fuse RGB images and LiDAR point clouds
6. Real-time semantic segmentation
6.1 Lightweight classification model-based method
6.2 Specialized backbone based method
6.3 Two-branch architecture based method
2019_Atif_Cite=13_A_Review_on_Semantic_Segmentation_from_a_Modern_Perspective
A. Accuracy oriented Methods
CNN,FCN
3) DeepLab series
4) EncNet for Context encoding:
5) CRFasRNN:
6) RefineNet for refining finer details
7) PSPNet for global scene-level descriptor:
B. Efficiency oriented Methods
1) ENet:
2) ICNet:
2018_Yu_Cite=136_Methods and datasets on semantic segmentation A review
3.Hand-engineered features based scene labeling methods
3.1. Methods using pixel(superpixel)-wise classification
3.2 Methods using CRF(Plain、Higher order、Dense)
3.3 Non-parametric methods
3.4 3D scene labeling methods
4 FCN
5 Weakly and semi- supervised scene labeling methods
5.1 Methods using image-level labels
5.2 Methods using bounding box annotations
5.3 Semi-supervised methods
2019_Hao_Cite=138_A Brief Survey on Semantic Segmentation with Deep Learning
3.1. Supervised methods
3.1.1. Context-based methods
3.1.2. Feature-enhancement-based methods
3.1.3. Deconvolution-based methods
3.1.4. RNN-based methods
3.1.5. GAN-based methods
3.1.6. RGBD-based methods
3.1.7. Real-time methods
3.2. Weakly-supervised methods
3.2.1. Methods based on tag-level supervision
3.2.2. Methods based on scribble-level涂鸦 supervision
3.2.3. Methods based on bounding-box-level supervision
(新颖)3.3. Semi-supervised methods
3.3.1. Methods based on domain adaptation
3.3.2. Methods based on few-shot learning
2018_Guo_Cite=402_A review of semantic segmentation using deep neural networks
2 Region-based semantic segmentation
3 FCN-based semantic segmentation
4 Weakly supervised semantic segmentation
2017_Garcia_Cite=1227_A review on deep learning techniques applied to semantic segmentation
2018_Garcia_Cite=539_A survey on deep learning techniques for image and video semantic segmentation
4.1 Decoder Variants
4.2 Integrating Context Knowledge
4.2.1 Conditional Random Fields
4.2.2 Dilated膨胀 Convolutions
4.2.3 Multi-scale Prediction
4.2.4 Feature Fusion
4.2.5 Recurrent Neural Networks
4.3 Instance Segmentation
4.4 RGB-D Data
包含两幅图像。第一幅是RGB三原色图像。第二幅是Depth Map图像,类似于灰度图,每个像素值是传感器距离物体的实际位置
4.5 3D Data
4.6 Video Sequences
有可能还有用的东西
图像语义分割综述 - stone的文章 - 知乎https://zhuanlan.zhihu.com/p/37801090
史上最全语义分割综述https://blog.csdn.net/qq_41997920/article/details/96479243