论文链接:Graph Neural Networks: A Review of Methods and Applications
Abstract:图(Graph)数据包含着十分丰富的关系型信息。从文本、图像这些非结构化数据中进行推理学习,例如句子的依赖树、图像的场景图等,都需要图推理模型。图网络(Graph neural networks)是一种链接主义模型,它靠图中节点之间的信息传递来捕捉图中的依赖关系。近年来,图卷积网络(Graph Convolutional network)和门控图网络(Gated graph neural network)在众多领域取得了重大的成功。
Introduction
图是一种结构化数据,它由一系列的对象(nodes)和关系类型(edges)组成。作为一种非欧几里得形数据,图分析被应用到节点分类、链路预测和聚类等方向。图网络是一种基于图域分析的深度学习方法,对其构建的基本动机论文中进行了分析阐述。
卷积神经网络(CNN)是GNN起源的首要动机。CNN有能力去抽取多尺度局部空间信息,并将其融合起来构建特征表示。CNN只能应用于常规的欧几里得数据上(例如2-D的图片、1-D的文本),这些形式的数据可以被看成是图的实例化。随着对GNN和CNN的深入分析,发现其有三个共同的特点:(1)局部连接(2)权值共享(3)多层网络。这对于GNN来说同样有重要的意义。(1)局部连接是图的最基本的表现形式。(2)权值共享可以减少网络的计算量。(3)多层结构可以让网络捕获不同的特征。然而,从CNN到GNN的转变还面临这另一个问题,难以定义局部卷积核和池化操作。如下图所示:

这也阻碍了CNN由传统欧几里得空间向非欧几里得空间的扩展。
这另一个动机就是图表示(graph embedding),即如何将图中的节点、边和子图以低维向量的形式表现出来。受启发于表示学习(representation learning)和词嵌入(word embedding),图嵌入技术得到了长足的发展。DeepWalk基于表示学习,被认为是第一种图嵌入技术模型。还有基于SkipGram模型的random walk。以及node2vec,LINE和TADW等。然而以上的这些模型存在两个缺点:(1)图中节点之间不存在任何的参数共享,导致计算量与节点数量呈线性增长。(2)图嵌入技术缺乏泛化能力,导致不能处理动态图或推广至新的图。
GNN相对于传统的神经网络来说也是存在优势的。标准的CNN和RNN网络不能处理图输入这种非顺序排序的特征表示。换句话说,图中节点的排序是没有规律可言的。如果非要用传统的CNN和RNN来处理图数据的话,只能遍历图中节点所有可能的出现顺序作为模型的输入,这对模型的计算能力来说是难以承受的。为了解决这个问题,GNN分别在每个节点上传播,忽略了节点之间输入的顺序。换而言之,GNN的输出是不随节点的输入顺序为转移的。另外,图中的边表示两个节点之间的依赖关系。在传统的神经网络中,这种依赖关系只能通过节点的特征表示来体现。GNN可以依赖周围的状态来更新节点的状态。最后是推理能力,与人类从日常经验中获取推理能力相似,GNN能够从非结构化数据(例如:场景图片、故事片段等)中生成图。与之对比的是,传统CNN和RNN能够从大量经验数据中生成完整的图片和文档,但并不能学习出这种推理图(reasoning graph)。
论文的主要贡献有:
- 提出一种统一的表现形式来展示不同模型中的不同传播步骤。
- 详细介绍了几种主流方法在不同场景中的应用。
- 对GNN面临的over-smoothing、scaling problems、dynamic graph和 non –structural data问题做出分析和展望。
Model
Graph Neural Networks
在图中,每个节点的定义是由该节点的特征和相关节点来共同表示的。GNN的目标是训练出一个state embedding函数hv,该函数包含了每个节点的领域信息。
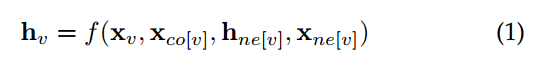
hv是节点v的向量化表示,它可以被用来去预测该节点的输出ov(例如节点的标签)。f(*)被称为local transition function,它被所有的节点共享,并根据输入的领域信息来更新节点的状态。xv是节点v的特征表示,xco[v]是v节点上边的特征表示,hne[v]是该节点的状态,xne[v] 是节点v周围节点的特征表示。
![]()
g(*)被称为local output function,它是用来产生节点的输出的。
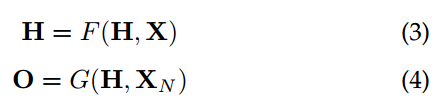
H、O、X、XN为其推广形式,代表图中的所有对象的堆叠形式。
Banach的fixed point提出以后,GNN中state的迭代计算过程可以表示如下:
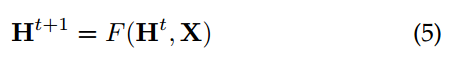
Ht代表H的第t-th的状态,H(0)代表其动态方程的初始状态。
对于一个GNN网络来说,其训练过程就是学习出函数f(*)和g(*)tv代表其一个有监督的节点,GNN的优化过程为:
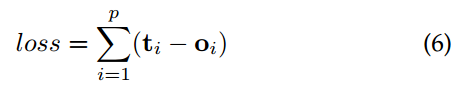
P代表图中所有有监督节点的数量。优化是基于梯度下降算法的,并且被表示如下:
- h被公式1迭代更新,直到T时间步。H(T)=H。
- 权重W的梯度通过loss计算得出。
- 进行梯度更新。
Limitations:实验结果表明GNN对于结构化数据的建模十分有效,但仍然存在着诸多的不足。
- 对于不动点隐藏状态的更新是十分低效的。如果放松对不动点的假设,论文中提出一种多层GNN可以得到节点及其邻域的稳定表示。
- GNN在迭代的过程中用相同的参数,然而大多标准网络在不同的网络层数使用不同的参数,
- 在原始的GNN中存在着一些无法有效建模的边缘信息特征。例如,在知识图谱中边代表这关系类型,不同边缘的消息传递应该根据他们的类型有所不同。怎么样去学习边缘的隐藏状态也是一个重要的问题。
- 如果把重点放在节点的表示而不是图上,就不适合使用不动点,因为不动点上表示的分布会变得非常平滑,且每个节点的信息量也会减少。
Graph Types
在原始的GNN中,模型的输入信息包含有监督的节点信息和无向的边。近年来,诸多类型的变种也层出不穷。
Directed Graphs
这第一种类型的变种就是,有向图(directed graphs)。传统的无向边可以看作是两个有向边组成的,表明两个节点之间存在着关系。然而,有向边相对与无向边来说能够表达更为丰富的信息。例如,在知识图谱中两个实体被一条边链接,但是第一个实体是第二个实体的父类,这就要求模型以不同的形式来对待父类和子类的信息传播过程。ADGPM模型用两种权重举证WP和WC来表达更加精确的结构信息。
![]()
DA分别代表规范化的父类和子类的邻接矩阵。
Heterogeneous Graphs
在异构图中,包含有不同类型的几种节点。表现不同类型节点最简单的形式是,将类型用one-hot向量表示,然后与原始节点的特征向量进行拼接。GraphInception模型将metapath(是一种路径游走方式,与之对应的是完全随机选择游走)的概念引入到了异构图的传播中。我们可以对邻近节点进行分类,根据其节点的类型和其距离。对于每个邻近节点群,GraphInception将它作为一个同构图中的子图,并将来自于不同同构图的传播结果连接起来视为一个集合节点来表示。
Graphs with Edge Information
在图中,边也蕴含着丰富的信息,例如权重和边的类型等。有两种表示图的方式:(1)两个节点之间的边切割开成两条边,然后将边也转化成节点。(2)在传播过程中,不同的边上有不同的权值矩阵。

Propagation Types
在模型中,信息的传播步骤和输出步骤是获得节点或者边隐含状态的关键步骤。不同变种的GNN的聚合函数(用来聚合图中所有点的邻域信息,产生一个全局性的输出)和节点状态更新函数如下图所示:

Convolution:GCN将卷积操作应用到图结构的数据上,主要分为Spectral method 和 Spatial Method 两种方法。其目的都是对节点以及节点的邻近节点进行信息收集。
Gate:使用GRU或者是LSTM这种带有门控机制的网络,来增强信息在图结构中的长期的传播。
Attention:GAT是一种图注意网络,它将注意力机制融入到了图传播的步骤中。GAT计算每个节点的隐藏状态,通过将 “attention” 机制应用到邻近节点上。
Skip connection:研究发现更深的网络层数可以帮助网络在节点的邻域节点上获取到更多的信息。但通过实验也发现深层网络也会在网络传播中带来噪声信息,随着网络层数的加深,网络还会出现退化。基于图像领域的启发,residual network和highway network 这些skip 模型能够有效的处理这一问题。

Training Methods
论文中还介绍了几种GNN的训练方法。比如GraphSAGE从节点的邻域聚合信息。FastGCN采用样本采样方法替代节点的所有邻域信息。这些训练方法,都使得模型的训练效率更加的高效。

General Frameworks
除了几种不同的GNN变种模型在论文中被介绍,几种图框架也被提出用来整合不同模型方法至单一框架中。MPNN(message passing neural network):统一了几种图神经网络和图卷积网络。NLNN(non-local neural network):统一了几种self-attention方法的图模型。GN(graph network):统一了包括MPNN、NLNN、和其他几种图网络模型。
Message Passing Neural Networks
MPNN网络包含两个阶段,message passing阶段和readout阶段。Message passing阶段在时间T步内发生,它被定义为message函数Mt和节点更新函数Ut。在时间T步内的节点隐状态通过Mt和Ut来产生t+1时刻节点的隐状态。
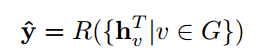
evw代表节点v到节点w上边的特征。Readout阶段可以被定义为对整个图计算特征向量。
T代表所有的时间步骤。具体的函数设置和方法选择可以进行调整,例如GGNN。
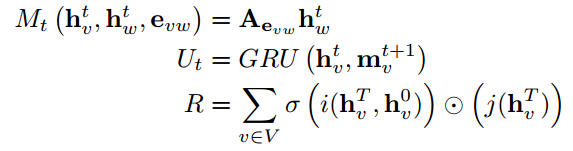
Non-local Neural Networks
NLNN网络被提出用来去捕获深度神经网络中存在的长期依赖问题。Non-local可以被推广成:

i是输出位置的索引,j代表图中所有可能出现的位置的索引。函数f(*)被用来计算i和j节点之间的距离。g(*)代表输入节点隐状态的一个变化。最后计算出来的值被正则化。
Graph Networks
图网络的定义:一个图被定义成一个三元组的形式G=(U,H,E)。U代表一个全局属性,H代表图中所有节点的属性,E代表图中所有发射节点、接收节点和它们之间边的属性。
图的设计有三个基本原则:
- Flexible representation :图中节点和边的属性可以被任何形式的数据来表示,不过比较常用的还是以向量或者是张量的形式来表达的。
- Gonfigurable with-block structure:GN中每个块都是可配置的,可以是不同的设置组合。
- Composable multi-block architectures:GN可以被组合成复杂的体系结构,这些架构如下图所示:

APPLICATIONS
图网络被广泛的应用于包括监督学习、半监督学习、无监督学习和强化学习等方向。论文中从三个不同的场景来分别阐述图网络的应用。(1)结构化场景:数据包含有很明确的关系结构,如物理系统、分子结构和知识图谱。(2)非结构化场景:数据不包含明确的关系结构,例如文本和图像等领域。(3)其他应用场景:例如生成式模型和组合优化模型。各个领域图网络的应用细节如下图所示:

Structural Scenarios
GNN被广泛的应用到包括应用物理、分子化学和知识图谱等领域。

Non-structural Scenarios
Image:在图像分类中,每个类别被视为图中的一个节点。
Text:在文本分类中,可以将文档或者句子看作成图中的一个节点(异构图)。然后使用文本GCN学习文档或者句子的向量化表示,作为节点的原始输入。如果将句子中的每个单词看成是图中的节点的话,那么GNN可以被用来解决序列标注问题,例如词性标注或者是命名实体识别。图网络还被拓展至许多NLP任务上,例如关系抽取和时间抽取等。

GNN还可以被应用到许多其他情景中去。
OPEN PROBLEMS
- 浅层结构:目前GNN还只能在较浅层的网络上发挥优势,随着层数的加深,网络会出现退化。
- 动态图:目前大多方法只能应用在静态图上,对于动态图还没有特别好的解决方案。
- 非结构化场景:还没有一个通用的方法来合理的处理非结构化数据。
- 扩展性:将图网络应用于大规模数据上仍然面临着不小的困难。