作者:水德
在过去两年时间里,阿里达摩院对话智能团队(Conversational AI)围绕 TableQA 做了一系列探索,先后在四大国际权威榜单上取得第一名,并且开源了首个中文预训练表格模型。同时,把 TableQA 技术落地为产品,在阿里云智能客服中开始规模化推广,成为具备差异化竞争力的新产品。本文将对达摩院在 TableQA 技术方向的系列探索创新和业务落地做系统的梳理介绍。

图 1:达摩院 TableQA 先后取得四大榜单第一
在日常工作中,Excel 表格随处可见;在 APP 或网页中,表格是清晰友好的信息传递方式;在企业中,关系型数据库无所不在。由于表格数据结构清晰、易于维护,并且对人类理解和机器理解都比较友好,表格 / 关系型数据库是各行各业应用最普遍的结构化知识存储形式。
但在表格知识的查询交互中,门槛却不低:对话系统或搜索引擎,并不能很好地将表格知识作为答案查询出来,而关系型数据库的查询更需要专业技术人员撰写查询语句(如 SQL 语句)来完成,对大多数用户来讲门槛更高。表格问答技术(TableQA)通过将自然语言转换为 SQL 查询语言,允许用户使用自然语言与表格知识直接交互,为表格知识的大规模交互使用铺平了道路。
一、什么是 TableQA
什么是表格问答(TableQA)呢,我们通过一个例子来引入。如下图班级学生信息的 Table,用户可能会问:“告诉我 3 班最高的男生有多高?”。要想解决这个问题,需要先把自然语言转换成一个 SQL 语句,然后利用该 SQL 查询表格,最终得到答案。整个 TableQA 的基础问题就是如何解析自然语言:把自然语言文本转变为一个 SQL 语句。
如果进一步考虑到多轮的情况,用户可能会接着上文问:“那最矮的呢?”,这个时候就需要利用上下文进行对话管理。除此之外,表格中的内容一般比较简练,经常是以实体词的方法呈现,比如身高值可能就是 “186”,如果只把这个数字返回给用户,可读性非常不友好。优雅的方式是结合上下文回复 “三班最高的男生有 1 米 86”,这就需要一个忠实且流畅的自然语言生成能力。

图 2:TableQA 技术框架图
由于表格内容复杂多样,涉及各行各业的专业知识,SQL 的标注难度大且成本高昂,模型迁移能力差,TableQA 一直是自然语言处理领域的难题。
二、TableQA 的发展及难点
TableQA 最早于 1972 年[1] 在数据库领域被提出,但在很长的时间里发展缓慢。但从 2017 年开始 [2],随着深度学习的蓬勃发展,该方向重新获得研究人员的关注,在过去几年里成为发展最快的一种问答方式。
根据任务设定的复杂程度,TableQA 技术发展可以分为四个重要阶段:单表单轮、从单表到多表、从单轮到多轮、从理解到生成。

图 3. TableQA 发展简史
2.1. 单表单轮
单表单轮是指用户只围绕一张表格进行单轮问答,该任务涉及的 SQL 类型较为简单,但在任务提出初期仍然极具挑战。比如在 2017 年单表单轮的数据集 WikiSQL [2] 推出时,仅有 36% 左右的准确率。该任务主要存在如下难点:
-
针对简单的 SQL 语句,如何建模 SQL 生成过程;
-
如何建立自然语言和数据库模式(schema)之间的联系,也称之为模式链接(schema linking)问题。
一个直接的想法是将自然语言到 SQL 的转换过程看做序列到序列生成问题,但在领域初期,受限于无法保证序列生成的结果准确性,表现一直不佳。而相比直接利用 Seq2Seq 建模,后续大部分的工作将 SQL 的生成过程转换为等价的分类问题 (Seq2Set) [3]。如下图 4 所示,通过将 SQL 拆解为不同的子模块,比如 SELECT、WHERE 等,然后利用多任务的方式进行子模块的预测,最后进行 SQL 的组合。这样不仅可以保证 SQL 语法正确,速度上也有明显优势。

图 4:基于 Seq2Set [3] 的 Text-to-SQL 示意图
在这套框架下,研究人员展开了一系列的改进,比如子模块的模型设计 [4]、引入表格的类型信息[5]、将执行结果作为弱监督的训练标签等[6]。除此之外,一些工作专注于模式链接的改进,比如引入规则的方式执行链接,或利用 attention 的方式[7],又或者通过将模式链接转换为等价任务[8,9] 进行辅助学习。
2.2. 从单表到多表
单表单轮问题的设置较为简单,在真实世界的场景中,表格更多是以多张表的形式(特别是关系型数据库)出现的,这将涉及到多个表的联合查询。而且 SQL 语句的复杂程度也变得非常复杂,涉及到了 JOIN、UNION 等高级关键字。

图 5:多表查询的复杂 SQL 示例
相比单表单轮,多表单轮的任务主要存在以下难点:
-
针对复杂的 SQL 语句,如何设计有语法约束的解码器;
-
如何利用数据库内多个表格之间的结构信息;
-
模式链接问题仍然是巨大的挑战,多表情况下更依赖链接的信息进行表格选择。
对于复杂的 SQL 语句,很难将其拆解为分类问题进行预测,所以学术界又回归到 Seq2Seq 过程,考虑如何设计有约束的生成过程,保证语法正确性。主流的工作在解码的过程中引入 AST 结构,利用树解码的方式建模语法规则[10]。

图 6:Text-to-SQL 任务中的树状解码约束示意图[11]
对于多表之间的结构,主要体现在外键、主键等,这些信息对于模型预测多表联合至关重要。一些研究人员将这种结构抽象为图的形式,并利用图神经网络进行学习[12]。

图 7:Text-to-SQL 中将 Schema 建模为 Graph 示意图[12]
对于模式链接,一些工作开始结合 Transformer 设计更好的模式链接模块,比如 RAT-SQL[18]、LGESQL[19] 等,这些方法更充分地考虑了自然语言中的单词到数据库模式的表、列、值的多粒度链接,极大地提升了模型的性能。近期,人们又开始关注面向表格的预训练模型,模式链接任务也成为重要的预训练目标,利用预训练强大的泛化能力,从而缓解跨领域问题。
2.3. 从单轮到多轮
很多情况下,用户需要与表格进行多轮的交互才能完成信息获取,所以 TableQA 进入了第三个阶段,从单轮问答升级为多轮问答,并可以和对话系统进行结合。对于多表多轮,难点主要围绕多轮建模:
-
如何建模多轮用户问题,进行上下文理解;
-
如何利用历史轮次生成的 SQL,作为重要的信息补充;
-
如何建模多轮情况下的模式链接问题,涉及到用户话题偏移,非局部依赖等。
多轮理解一直是对话领域重要的方向,对于多轮问题的建模,通常有直接拼接、轮次 attention 和 gate attention 等方式:

图 8:多轮建模中的直接拼接、turn attention 和 gate attention 示例 [11]
与普通的多轮问答相比,TableQA 在历史轮次中生成的 SQL 也表达了丰富的上下文信息,且相比自然语言更加结构化,所以一些工作将历史的 SQL 作为当前轮的输入,增强上文信息。随着单轮的表格预训练模型的蓬勃发展,针对多轮的表格预训练模型也应运而生,进一步提升了多表多轮 TableQA 的理解性能。
2.4. 从理解到生成
模型生成 SQL 后执行查询,得到的结果仍然是表格,不利于用户阅读,所以 TableQA 需要构建回复生成能力。近年来预训练生成模型如 GPT、T5 等在文本生成相关任务中取得了显著提升,在 Table-to-Text 方向、KGPT 和 TableGPT 等模型也在关注基于结构化表格数据生成对应的文字描述。而 TableQA 的回复生成任务则给文本生成的方向带来了新的挑战:
-
回复需要完全忠实于给定的 SQL 和 Table;
-
对于垂直领域的特殊话术需要有一定的泛化能力,因此对生成模型的效果提出了更高的要求;
-
在实际落地的过程中,生成模型的解码速度一般相对较慢,推理效率需要大幅度优化。
目前该方向的研究工作还处于比较空白的状态,具有较高的研究和应用价值。
三、达摩院取得四大国际榜单第一
近些年来,TableQA 任务得到了学术界及工业届的共同关注,并取得了飞速的发展。而 Text-to-SQL 作为 TableQA 的核心技术 ,学术界推出了包括单表单轮 WikiSQL[2]、多表单轮 Spider[13]、多表多轮 SparC[14]、对话式 CoSQL[15] 等四个权威的国际公开数据集及榜单。根据每个数据库包含的表数量,可以分为单表和多表 (WikiSQL, Spider)问题,其中多表要求 SQL 有表格选择(join)的能力,生成的 SQL 较为复杂;根据问句的交互轮次,可以分为单轮和多轮 (SParC),多轮问题涉及到多轮理解,对模型的指代消歧及上下文建模能力提出了要求。进一步的,Text-to-SQL 可以融入到对话系统 (CoSQL),对理解、策略和生成能力提出了更高的要求,进一步提升任务的难度。

3.1. 单表单轮 WikiSQL
(1)WikiSQL 数据集介绍
WikiSQL[2] 数据集是 Salesforce 在 2017 年提出的 Text-to-SQL 数据集,它包含了 26,521 个表格,80,645 条自然语言问句及其对应的 SQL 语句。WikiSQL 数据集存在单轮问句、围绕单表、SQL 类型简单等特点,如下图所示,WikiSQL 仅围绕一张表格进行简单问题的问答,所以设计到的 SQL 也只包含 SELECT、AGG、WHERE、CONDITION、OP 等关键字。

图 9:WikiSQL 数据示例[2]
尽管 WikiSQL 的数据构造较为简单,但在真实工业场景中,简单问题也是最常见的查询,先解决简单数据是后续的基础,所以达摩院团队先针对 WikiSQL 展开了研究。Text-to-SQL 的目标是将自然语言问题,依据数据库信息(schema) 得到可执行的 SQL。上面提到的模式链接(schema linking),即找到自然语言问题和模式之间的关联是转换过程中的核心步骤。当前,对于模式链接的识别与建模已经成了 Text-to-SQL 任务中的重要瓶颈。
(2)SDSQL 模型取得第一
为了更好地解决模式链接问题,达摩院创新性地提出了 Schema Dependency [16] 的建模方式:借助已有的 SQL 解析出细粒度的链接关系,作为自然语言问题和 Schema 之间的桥梁。

图 10:SDSQL 模型中的的 Schema Dependency 示意图[16]
基于这种建模方式,达摩院提出一种新的解析模型 SDSQL。如下图 11 所示,将自然语言问题与 Schema 作为输入,然后利用多任务的方式优化模型:一个任务是利用双仿射的网络结构来预测解析好的 Schema Dependency,强化模型的模式链接能力;另一个任务是通过分类的方式来预测 SQL 中的每一个组件,从而完成 SQL 的预测。

图 11:SDSQL 模型结构图[16]
就效果而言,2021 年 3 月, SDSQL 在 WikiSQL 上取得了 SOTA 的成绩:

图 12:达摩院提出的 SDSQL 模型在 WikiSQL 取得第一
3.2. 多表单轮 Spider
(1)Spider 榜单介绍
Spider [13] 是耶鲁大学 & Salesforce 在 EMNLP 2018 上提出的单轮、围绕多表、复杂 SQL 的语义解析和 Text-to-SQL 数据集。Spider 是目前 Text-to-SQL 领域最受关注的数据集,吸引了阿里达摩院、微软、Meta、亚马逊、百度等大厂的持续投入。
该数据集包含了 10,181 个问题和 5,693 个不同的复杂 SQL 查询语句,涉及 200 个多表数据库,涵盖 138 个不同的领域。相比 WikiSQL 的简单 SQL 形式,Spider 包含了大量复杂的 SQL (如 GROUP BY、ORDER BY 或嵌套查询)以及具备多个表和外键的数据库。

图 13:Spider 数据示例[13]
(2)SSSQL 模型取得第一
大家对于 Spider 的建模主要围绕结构层面展开,之前提到的模式链接其实是自然语言问题和 Schema 之间的结构建模。另外一些工作主要关注于 Schema 内部的建模,将 Schema 中的表、列、外键信息转换为图的形式,融入网络进行学习。而达摩院首先关注到了自然语言问题内部结构对 Text-to-SQL 任务的重要性。
如下图 14 所示,在模式连接正确的情况下,仍然无法预测到正确的 SQL。在这个例子中,因为按照词粒度的距离 id 和 date 的距离很远,导致在 SELECT 部分丢失了 transcript_id 这一列。

图 14:因未考虑问题内部结构产生的错误示例
为了解决上述问题,达摩院利用句法关系建模了自然语言问题内部的关系,在句法距离的度量下,id 和 date 的关系将被拉近,从而生成正确的 SQL。基于这个动机,达摩院提出了 SSSQL,将自然语言内部的结构、Schema 内部的结构以及自然语言与 Schema 之间的结构同时建模,并结合一种关系解耦的优化方法,实现了更强的表征能力。
就效果而言,2021 年 9 月, SSSQL 在 Spider 上取得了 SOTA 的成绩:

图 15:达摩院提出的 S²SQL 模型在 Spider 榜单取得第一
3.3. 多表多轮 SParC
(1)SParC 榜单介绍
WikiSQL 和 Spider 都是单轮的 Text-to-SQL 数据,耶鲁大学 & Salesforce 于 ACL 2019 提出有上下文依赖的多轮数据集 SParC[14],作者基于 Spider 进行多轮扩展。不同于 Spider 一句话对应一个最终 SQL,SParC 通常需要通过多轮对话来实现用户的查询意图,并且在交互过程中,用户会省略很多之前提到的信息,或者新增、修改之前提到过一些内容,使得该任务更具挑战性。

图 16:SParC 数据示例[17]
(2)R²SQL 模型取得第一
R²SQL[17] 模型的内容详见下一部分。2020 年 7 月,R²SQL 模型在 SParC 榜单取得第一。

图 17:达摩院提出的 R²SQL 模型在 SParC 榜单取得第一
3.4. 对话式 CoSQL
(1)CoSQL 榜单介绍
EMNLP 2019 提出的 CoSQL[15] 将 Text-to-SQL 融入到对话场景,仅存在 3,007 条问题 - SQL 对,但在交互过程中增加了拒识、澄清等轮次,并且需要验证返回的结果后,生成类人的自然语言回复。同时,数据集中 SQL 各关键字的分布差异较大,是目前 Text-to-SQL 领域最难、最复杂的数据集。
(2)R²SQL 模型取得第一
总体来说,SParC 和 CoSQL 遇到的共同挑战在于上下文建模,如何在上下文环境下共同建模自然语言问题、Schema,以及模式链接是亟需解决的问题。达摩院在 AAAI 2021 提出了一种基于动态上下文模式图的框架 R²SQL[17],可以联合地学习自然语言问题、数据库模式(schema)和其之间模式链接的表征,捕捉复杂的上下文依赖。

图 18:R²SQL 模型中的动态模式图
除此之外,在用户不断询问的过程中,存在用户聚焦的意图发生变化的现象,而这种话题偏移将导致模型的性能下降。为了解决这个问题,达摩院使用类人的想法,使用衰减机制来降低之前模式链接的权重,从而更关注当前轮次的模式链接。2020 年 8 月,R²SQL 模型在取得 CoSQL 榜单第一名。

图 19:达摩院提出的 R²SQL 模型在 CoSQL 榜单取得第一
四、开源中文首个预训练表格模型
达摩院对话智能团队提出了基于 “模式依存” 的表格预训练模型,普遍提升各场景表格的问答准确率。如下图 20 所示,模式依存就是在自然语言问句和表格结构模式之间建立依存关系,比如先让模型学习到 “男生” 和“性别”之间存在依存关系,进一步还可以定义这种依存关系的具体名称为 “WHERE-value”。同时,达摩院团队还使用了模仿人类的“课程学习” 方法来克服多样化难度数据带来的影响。

图 20:Schema Dependency 示例
在耶鲁大学发布的业界最大规模的英文文本 - 表格数据集 WikiSQL,以及微软构建的英文文本 - 表格高难度预测任务 SQuALL 数据集上,SDCUP 模型均取得业界最优效果。详细内容参见《从序列到结构—中文首个预训练表格模型发布》。相关模型和训练代码已经开源于阿里巴巴预训练模型体系 AliceMind。

AliceMind项目地址:https://github.com/alibaba/AliceMind
五、TableQA 规模化业务落地
达摩院 Conversational AI 团队已经将本文介绍的预训练表格模型和相关 Text-to-SQL 技术应用于阿里云智能客服 (云小蜜) 的 TableQA 产品中。为满足不同场景下的训练和交付需求,表格管理、数据配置、模型训练、效果干预等功能已全部完成产品化,基本做到知识梳理低成本,问答构建高速度,模型训练好效果,满足各个场景的交付运维需求。目前已在多个项目中开始规模化交付。
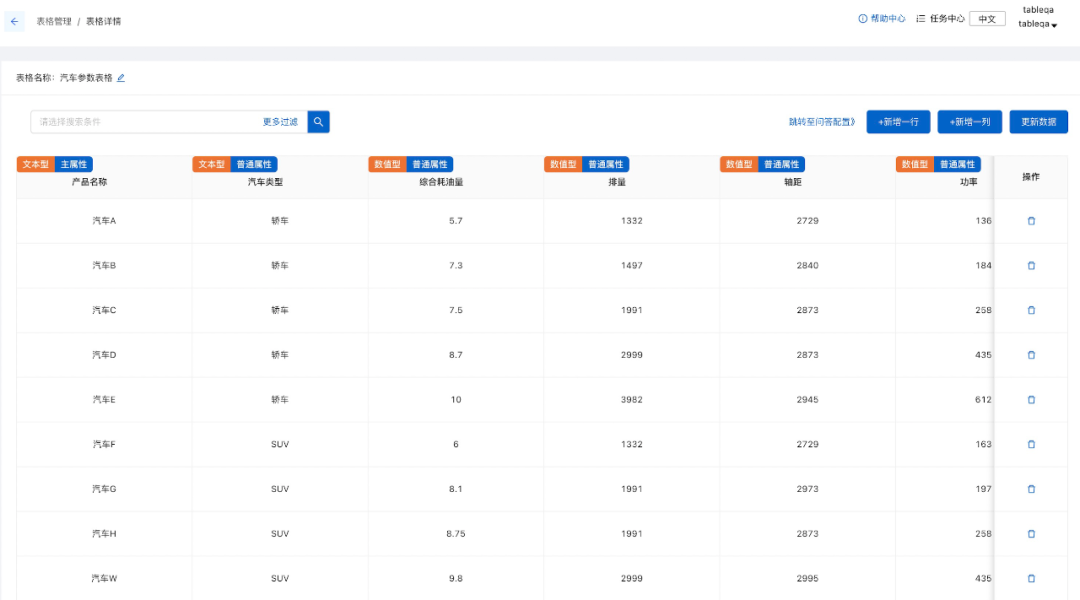
图 21:TableQA 在阿里云智能客服中的产品
六、未来的技术展望
经过过去两年的探索,达摩院在 TableQA 方向,从单轮到多轮,从单表到多表,从下游模型到上游预训练表格模型,初步形成了比较体系的创新。但总体上,TableQA 还是一个新方向,面向未来,还有很多难题需要研究:
-
大规模预训练表格理解模型;
-
大规模预训练表格生成模型;
-
更强大的 Text-to-SQL 模型;
-
忠实流畅类人的 TableNLG;
-
端到端开箱即用的 TableQA 系统;
-
推广到更多的应用场景。
欢迎感兴趣的同学一起学习交流。
参考资料:
[1] Woods, W. A., Kaplan, R., and Webber, N. B. The LUNAR sciences natural language information system: Final report. Technical Report BBN Report No. 2378, Bolt Beranek and Newman, Cambridge, Massachusetts. (1972)
[2] Zhong, Victor, Caiming Xiong, and Richard Socher. "Seq2sql: Generating structured queries from natural language using reinforcement learning." arXiv preprint arXiv:1709.00103 (2017).
[3] Xu, Xiaojun, Chang Liu, and Dawn Song. "Sqlnet: Generating structured queries from natural language without reinforcement learning." ICLR (2018)
[4] Lyu, Qin, et al. "Hybrid ranking network for text-to-sql." arXiv preprint arXiv:2008.04759 (2020).
[5] Yu, Tao, et al. "Typesql: Knowledge-based type-aware neural text-to-sql generation." NAACL (2018).
[6] Wang, Chenglong, et al. "Robust text-to-sql generation with execution-guided decoding." arXiv preprint arXiv:1807.03100 (2018)
[7] Hwang, Wonseok, et al. "A comprehensive exploration on wikisql with table-aware word contextualization." arXiv preprint arXiv:1902.01069 (2019).
[8] Ma, Jianqiang, et al. "Mention extraction and linking for sql query generation." EMNLP(2020).
[9] Xuan, Kuan, et al. "SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising." arXiv preprint arXiv:2105.07911 (2021).
[10] Yin, Pengcheng, and Graham Neubig. "A syntactic neural model for general-purpose code generation." ACL (2017).
[11] Liu, Qian, et al. "How far are we from effective context modeling? an exploratory study on semantic parsing in context." IJCAI (2020).
[12] Bogin, Ben, Matt Gardner, and Jonathan Berant. "Representing schema structure with graph neural networks for text-to-sql parsing." arXiv preprint arXiv:1905.06241 (2019).
[13] Yu, Tao, et al. "Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task." EMNLP (2018).
[14] Yu, Tao, et al. "Sparc: Cross-domain semantic parsing in context." ACL (2019).
[15] Yu, Tao, et al. "CoSQL: A conversational text-to-SQL challenge towards cross-domain natural language interfaces to databases." EMNLP (2019).
[16] Hui, Binyuan, et al. "Improving Text-to-SQL with Schema Dependency Learning." arXiv preprint arXiv:2103.04399 (2021).
[17] Hui, Binyuan, et al. "Dynamic Hybrid Relation Exploration Network for Cross-Domain Context-Dependent Semantic Parsing." AAAI (2021).
[18] Wang, Bailin, et al. "Rat-sql: Relation-aware schema encoding and linking for text-to-sql parsers." ACL (2019).
[19] Cao, Ruisheng, et al. "LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations." ACL (2021).