1.前言
2022年绝对可以说是AIGC元年,从google搜索的趋势来看,在2022年AI绘画及AI生成艺术的搜索量激增。
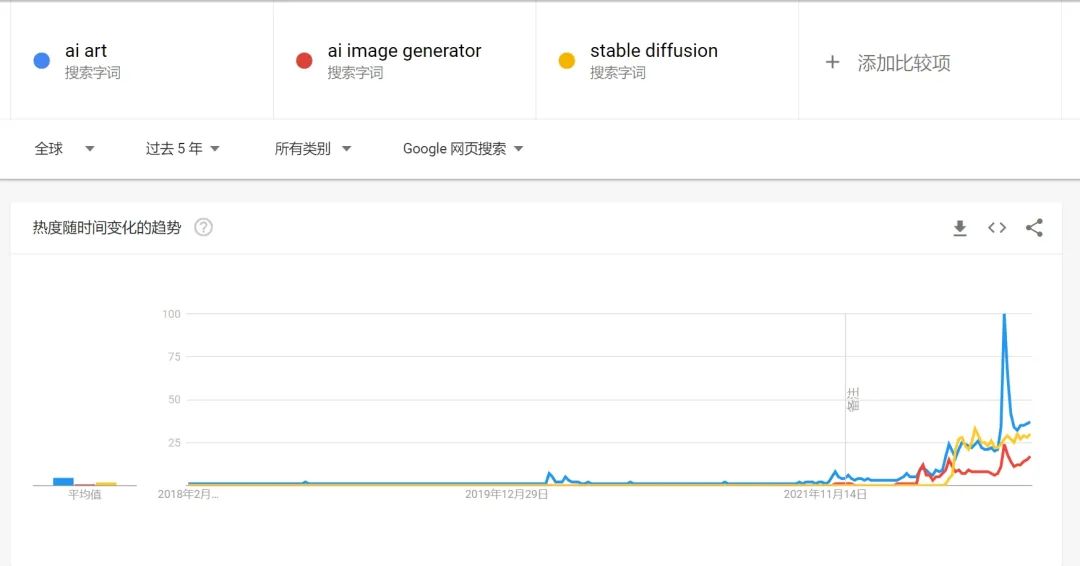
AI绘画在这一年的爆发一个很重要的原因就是 Stable Diffusion 的开源,这也来不开这几年 Diffusion Model 扩散模型在这几年里的迅猛发展,结合了 OPENAI 已经发展得很成熟的文本语言模型 GPT-3,从文本到图片的生成过程变得更加容易。
2.GAN(生成对抗网络)的瓶颈
从14年诞生,到18年的StyleGAN,GAN在图片生成领域获得了长足的发展。就好像自然界的捕食者与被捕食者相互竞争共同进化一样,GAN的原理简单来说就是使用两个神经网络:一个作为生成器、一个作为判别器,生成器生成不同的图像让判别器去判断结果是否合格,二者互相对抗以此训练模型。
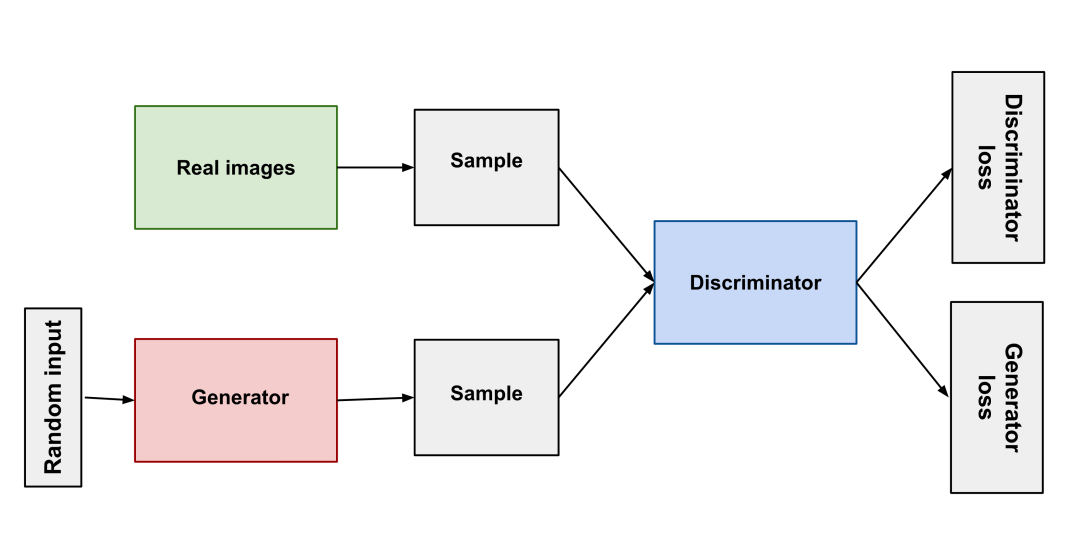
GAN(生成对抗网络)经过不断发展其有了不错的效果,但有些始终难以克服的问题:生成结果多样性缺乏、模式坍缩(生成器在找到最佳模式后就不再进步了)、训练难度高。这些困难导致 AI 生成艺术一直难以做出实用的产品。
2.Diffusion Model(扩散模型)的突破
在 GAN 多年的瓶颈期后,科学家想出了非常神奇的 Diffusion Model(扩散模型)的办法去训练模型:把原图用马尔科夫链将噪点不断地添加到其中,最终成为一个随机噪声图像,然后让训练神经网络把此过程逆转过来,从随机噪声图像逐渐还原成原图,这样神经网络就有了可以说是从无到有生成图片的能力。而文本生成图片就是把描述文本处理后当做噪声不断添加到原图中,这样就可以让神经网络从文本生成图片。

Diffusion Model(扩散模型)让训练模型变得更加简单,只需大量的图片就行了,其生成图像的质量也能达到很高的水平,并且生成结果能有很大的多样性,这也是新一代 AI 能有难以让人相信的「想象力」的原因。
当然技术也是一直在突破的,英伟达在1月底推出的StyleGAN的升级版StyleGAN-T就有了十分惊艳的进步,在同等算力下相比于Stable Diffusion生成一张图片需要3秒,StyleGAN-T仅需0.1秒。并且在低分辨率图像StyleGAN-T要比Diffusion Model要好,但在高分辨率图像的生成上,还是Diffusion Model的天下。由于StyleGAN-T并没有像Stable Diffusion那样获得广泛的应用,本文还是以介绍Stable DIffusion为主。
3.Stable Diffusion
在今年早些时间,AI作画圈经历了 Disco Diffusion、DALL-E2、Midjouney 群雄混战的时代,直到 Stable Diffusion 开源后,才进入一段时间的尘埃落定,作为最强的 AI 作画模型,Stable Diffusion 引起了 AI 社群的狂欢,基本上每天都有新的模型、新的开源库诞生。尤其是在Auto1111的WebUI版本推出后,无论是部署在云端还是本地,使用Stable Diffusion都变成一个非常简单的事情,并且随着社区的不断开发,很多优秀的项目,比如Dreambooth、deforum都作为 Stable Diffusion WEBUI版的一个插件加入进来,使得像微调模型、生成动画等功能都能一站式完成。
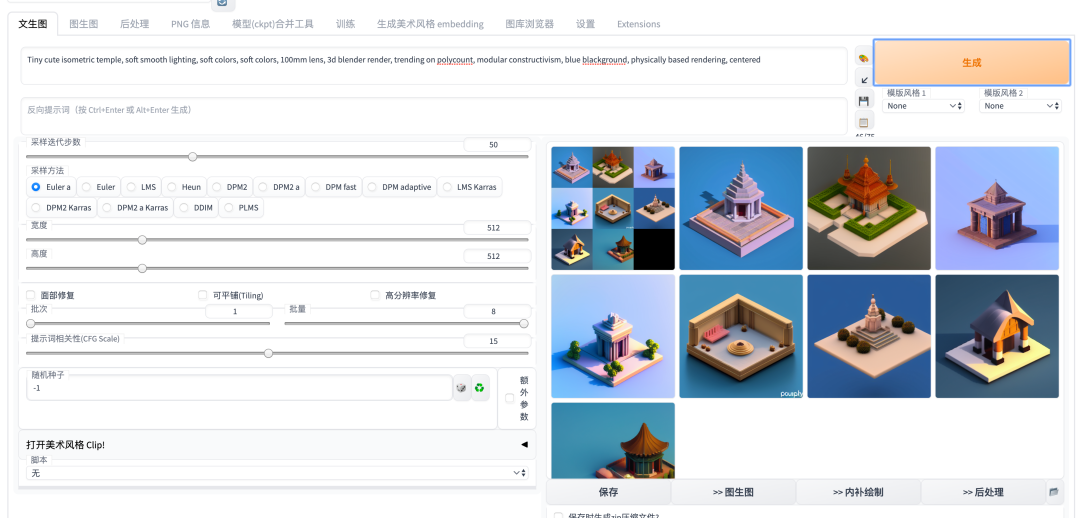
4.AI绘画玩法及能力介绍
下面介绍下目前使用 Stable Diffusion 可以有哪些玩法以及能力




5.目前主要应用情况介绍


6.自己搭一个Stable Diffusion WEBUI服务
6.1 云端版本
这里使用AutoDL提供的云端算力来搭建,也可以使用其他平台比如 Google Colab或者百度飞桨等。
1.首先在AutoDL上注册账号并且租一台 A5000/RTX3090 显卡的云主机。https://www.autodl.com/market/list
2.以此主机创建镜像,镜像可在 www.codewithgpu.com 上选择已经打包好的算法镜像。这里以 https://www.codewithgpu.com/i/AUTOMATIC1111/stable-diffusion-webui/Stable-Diffusion-for-NovelAI 这个镜像为例,选择后创建。
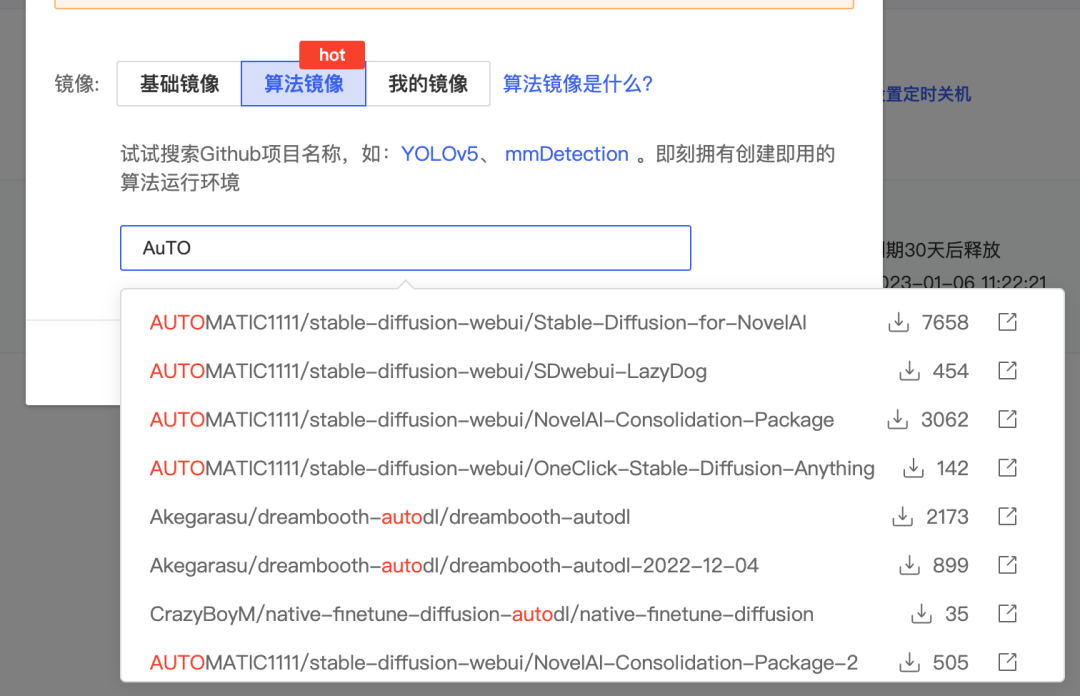
3.创建后开机并启动JupterLab,

运行下面指令启动服务即可。如果遇到系统盘空间不足的情况,也可以将stable-diffusion-webui/文件夹移入数据盘 autodl-tmp再启动。如果遇到启动失败,可以根据你机器的位置配置一下学术资源加速。
cd stable-diffusion-webui/
rm -rf outputs && ln -s /root/autodl-tmp outputs
python launch.py --disable-safe-unpickle --port=6006 --deepdanbooru
6.2 本地版本
如果你有一块显卡还不错的电脑,那可以部署在本地,这里介绍下Windows版本的搭建:
1.首先需要安装Python 3.10.6,并且添加环境变量到Path中
2.安装git
3.Clone Stable Diffusion WEBUI 的工程代码到本地
4.将模型文件放置于 models/Stable-Diffusion目录下,相关模型可以去https://huggingface.co/ 下载
5.运行 webui-user.bat,通过本机电脑ip及7860端口访问服务。
7.总结
本文介绍了AI绘画的一些相关的信息,感兴趣的朋友也可以自己把服务部署起来,自己试着学习用DreamBooth或者最新的Lora微调一下大模型。相信在2023年,随着 AIGC 热度的不断提高,我们的工作和生活都会因为 AI 带来巨大的改变。前段时间 ChatGPT的推出给我们带来了巨大的震撼,就好像刚进入互联网时期搜索信息的能力一样,今后学会使用 AI 来辅助我们的工作也将是一个非常重要的能力。
8.参考资料
-
从起因到争议,在 AI 生成艺术元年聊聊 AI
https://sspai.com/post/76277 -
神经网络学习笔记6——生成式AI绘画背后的的GAN与Diffusion初解
https://blog.csdn.net/qq_45848817/article/details/127808815 -
How diffusion models work: the math from scratch
https://theaisummer.com/diffusion-models/ -
GAN 结构概览
https://developers.google.com/machine-learning/gan/gan_structure -
The absolute beginners guide to Midjourney – a magical introduction to AI art
https://www.entrogames.com/2022/08/absolute-beginners-guide-to-midjourney- magical-introduction-to-ai-art/ -
The viral AI avatar app Lensa undressed me—without my consent
https://www.technologyreview.com/2022/12/12/1064751/the-viral-ai-avatar-app- lensa-undressed-me-without-my-consent/ -
instruct-pix2pix
https://huggingface.co/timbrooks/instruct-pix2pix
文/misotofu










![全网多种方式解决The requested resource [/] is not available的错误](https://img-blog.csdnimg.cn/32f638ced4f74da29fb5177a304cd320.png)