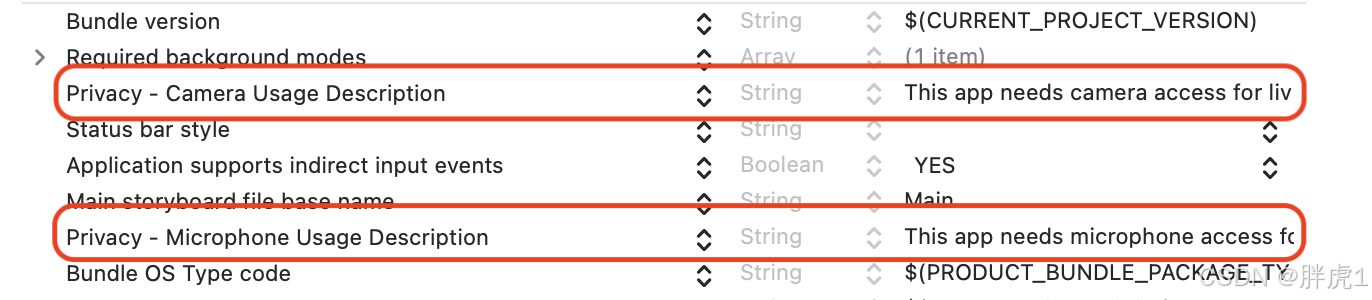
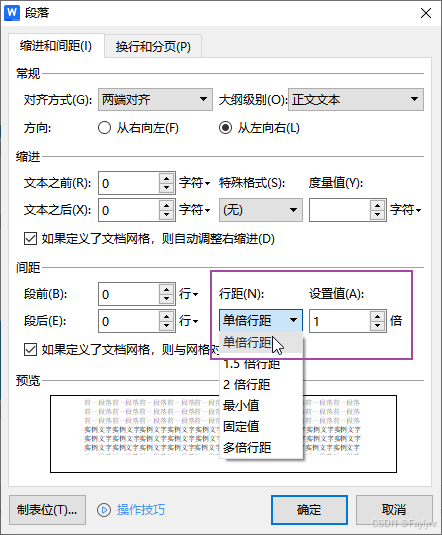
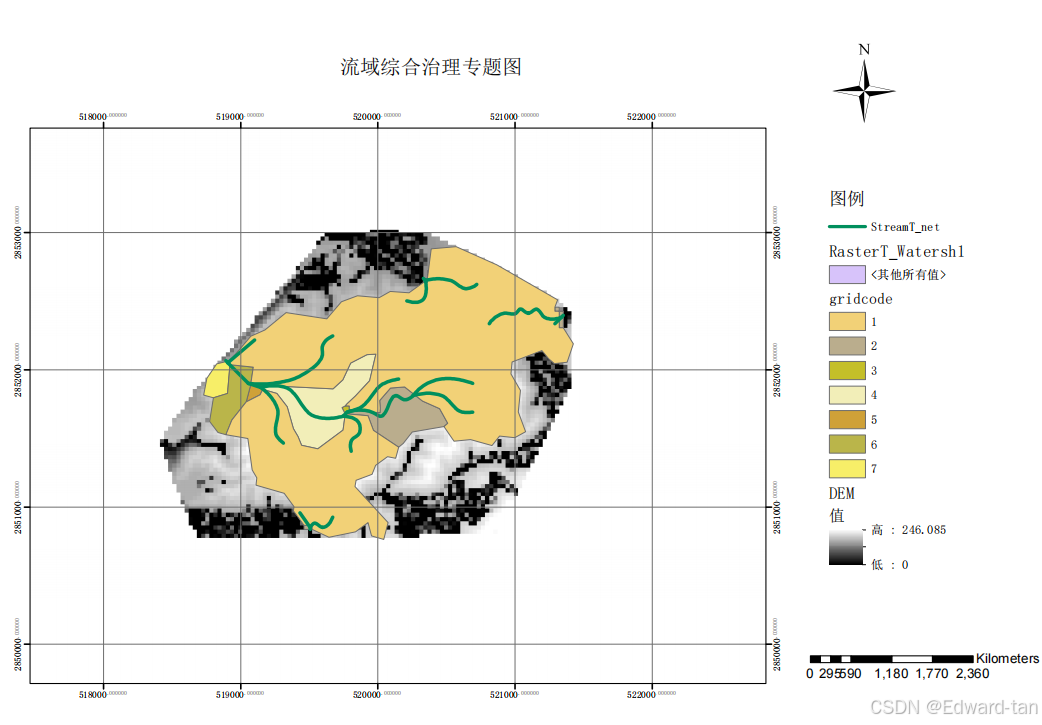
mkdir - p config/{ cert, conf. d} html logs
user nginx;
worker_processes auto; error_log / var / log/nginx/error. log notice;
pid / var / run/nginx. pid; events { worker_connections 1024;
} http { include / etc/nginx/mime. types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"' ; access_log / var / log/nginx/access. log main; sendfile on; keepalive_timeout 65; include / etc/nginx/conf. d/* . conf; server { listen 80; server_name _; root / usr/share/nginx/html; index index. html index. htm; location / { try_files $uri $uri / =404; } }
}
version: '3.8' services:nginx:image: nginx:1. 23. 3restart: unless-stoppedcontainer_name: nginx1. 23. 3ports:- "80:80" environment:TZ: Asia/Shanghaivolumes:- . / config/nginx. conf:/ etc/nginx/nginx. conf- . / config/conf. d/:/ etc/nginx/conf. d/- . / config/cert/:/ etc/nginx/cert/- . / html/:/ usr/share/nginx/html/- . / logs/:/ var / log/nginx/healthcheck:test: [ "CMD" , "curl" , "-f" , "http://localhost" ] interval: 30stimeout: 10sretries: 3
vim / etc/docker/daemon. json
{ "registry-mirrors" : [ "https://2a6bf1988cb6428c877f723ec7530dbc.mirror.swr.myhuaweicloud.com" , "https://docker.m.daocloud.io" , "https://hub-mirror.c.163.com" , "https://mirror.baidubce.com" , "https://your_preferred_mirror" , "https://dockerhub.icu" , "https://docker.registry.cyou" , "https://docker-cf.registry.cyou" , "https://dockercf.jsdelivr.fyi" , "https://docker.jsdelivr.fyi" , "https://dockertest.jsdelivr.fyi" , "https://mirror.aliyuncs.com" , "https://dockerproxy.com" , "https://mirror.baidubce.com" , "https://docker.m.daocloud.io" , "https://docker.nju.edu.cn" , "https://docker.mirrors.sjtug.sjtu.edu.cn" , "https://docker.mirrors.ustc.edu.cn" , "https://mirror.iscas.ac.cn" , "https://docker.rainbond.cc" ]
}
<! DOCTYPE html > < html> < head> < metacharset = " utf-8" > < title> </ title> </ head> < body> < h1> </ h1> </ body> </ html>