Alertmanager 是一个用于处理和管理 Prometheus 警报的开源工具。它负责接收来自 Prometheus 服务器的警报,进行去重、分组、静默、抑制等操作,并通过电子邮件、PagerDuty、Slack 等多种渠道发送通知。
主要功能
- 去重:合并相同或相似的警报,避免重复通知。
- 分组:将相关警报合并为一个通知,减少信息过载。
- 静默:临时屏蔽特定警报,避免干扰。
- 抑制:在特定条件下阻止某些警报的发送。
- 路由:根据标签将警报分发到不同的接收者或渠道。
- 通知:支持通过多种方式发送警报通知。
核心概念
- Alert:由 Prometheus 生成的警报,包含标签、注解和状态。
- Receiver:警报的接收者,如电子邮件或 Slack 频道。
- Route:定义警报如何路由到接收者。
- Silence:临时屏蔽特定警报的机制。
下载安装包:
地址: https://prometheus.io/download/#alertmanager
将安装包alertmanager-0.24.0.linux-amd64.tar.gz上传服务器


接下来再安装一个插件prometheus-webhook-dingtalk
由于 Alertmanager 没有内置钉钉的支持,因此需要通过 Webhook 的方式将告警信息发送到钉钉。prometheus-webhook-dingtalk 就是这样一个工具,它充当了 Alertmanager 和钉钉之间的桥梁:
- Alertmanager 将告警信息通过 Webhook 发送到
prometheus-webhook-dingtalk。 prometheus-webhook-dingtalk将告警信息格式化为钉钉支持的格式(如 Markdown),并通过钉钉的 Webhook API 推送到指定的群聊。
下载安装包:
地址: https://github.com/timonwong/prometheus-webhook-dingtalk/releases/
上传到服务器进行解压安装

创建钉钉机器人:
【电脑端钉钉 】-【群聊】-【群设置】-【智能群助手】-【添加更多】-【添加机器人】-【自定义】-【添加】,编辑机器人名称和选择添加的群组,勾选加签,将生成的秘钥复制出来。


修改prometheus-webhook-dingtalk配置,将以上信息填到文件中:
新建/usr/local/prometheus-webhook-dingtalk/config.yml,添加以下配置

启动prometheus-webhook-dingtalk服务
查看插件提供的webhook地址:这个记好待会有用

编辑alertmanager.yml配置文件,添加路由和接受者配置,注意url填写钉钉插件提供的webhook地址,就是上图圈起来那个,根据自己的情况来,而不是钉钉直接提供的那个webhook。
接下来编辑prometheus配置文件:
增加和修改prometheus.yml的alertmanager部分,让alertmanger能与Prometheus通信。

在/usr/local/prometheus/路径建立rules文件夹

在rules文件夹中创建node_rules.yml用来配置主机节点的告警
在/usr/local/prometheus/node_exporter_targets.json文件中添加测试节点

重启prometheus
启动Alertmanager
启动钉钉插件prometheus-webhook-dingtalk
查看grafana、alertmanager、prometheus端口都已经启动

接下来关闭刚才添加的测试机器

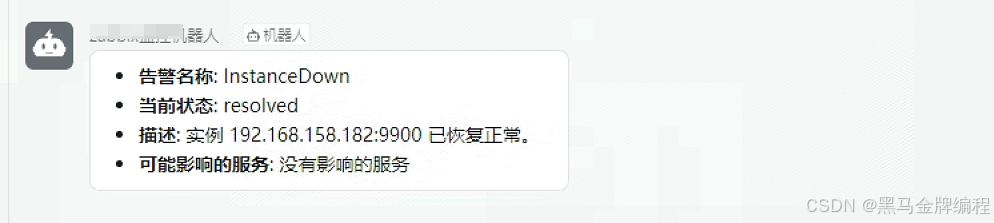
等了一会查看钉钉出现了告警

接下来优化告警消息:
1、使用中文发送告警信息
修改prometheus-webhook-dingtalk/config.yml文件添加以下字段

2、告知故障的影响范围
修改/usr/local/prometheus/rules/node_rules.yml配置文件,添加以下信息

重启/prometheus-webhook-dingtalk服务:
重启prometheus服务:
查看端口都已经启动

查看钉钉最新消息已经修改为中文提示和告知影响范围

启动故障机器再次查看消息
后续继续更新监控其他服务



















