全国地图json数据下载地址
目录
html加载全部代码
方式一:使用html方式加载geojson
1. 初始化地图
2. 加载geojson数据
设置geojson图层样式,设置type加载数据类型
设置线条
鼠标移入改变颜色,设置图层属性,此处是fill-extrusion类型
使用mapbox地图加载geojson数据
html加载全部代码
<!DOCTYPE html>
<html>
<head><meta charset="utf-8"><title>Create a hover effect</title><meta name="viewport" content="initial-scale=1,maximum-scale=1,user-scalable=no"><link href="https://api.mapbox.com/mapbox-gl-js/v3.1.2/mapbox-gl.css" rel="stylesheet"><script src="https://api.mapbox.com/mapbox-gl-js/v3.1.2/mapbox-gl.js"></script><style>body { margin: 0; padding: 0; }#map { position: absolute; top: 0; bottom: 0; width: 100%; }</style>
</head>
<body>
<div id="map"></div>
<script>let dataJson = {}mapboxgl.accessToken = '你的密钥';fetch(url).then((response)=>{ return response.json();}).then((data)=>{dataJson = datadataJson.features.map((item, index) => {item['id'] = indexitem.properties['color'] = '#9b46e1'item.properties['height'] = Math.floor(Math.random() * (10000 - 9500 + 1)) + 9500})}).catch((error)=>{})const map = new mapboxgl.Map({container: 'map',style: 'mapbox://styles/mapbox/streets-v12',center: [107.164659,33.95191],zoom: 7.5,pitch:45});let hoveredPolygonId = null;map.on('load', () => {map.addSource('states', {'type': 'geojson','data': dataJson});map.addLayer({'id': 'state-fills','type': 'fill-extrusion', 'source': 'states','layout': {},'paint': {'fill-extrusion-color': ['case',['boolean', ['feature-state', 'hover'], false],'rgba(255,228,96,0.80)',// 鼠标移入颜色'rgba(25,172,230,0.75)' // 默认颜色],"fill-extrusion-opacity":0.85,// 从source 'height'属性获取填充-挤出-高度。'fill-extrusion-height': ['get', 'height'],}});map.addLayer({'id': 'state-borders','type': 'line','source': 'states','layout': {},'paint': {'line-color': '#627BC1','line-width': 0.8}});map.on('mousemove', 'state-fills', (e) => {if (e.features.length > 0) {if (hoveredPolygonId !== null) {map.setFeatureState({ source: 'states', id: hoveredPolygonId },{ hover: false });}hoveredPolygonId = e.features[0].id;map.setFeatureState({ source: 'states', id: hoveredPolygonId },{ hover: true });}});map.on('mouseleave', 'state-fills', () => {if (hoveredPolygonId !== null) {map.setFeatureState({ source: 'states', id: hoveredPolygonId },{ hover: false });}hoveredPolygonId = null;});});
</script></body>
</html>方式一:使用html方式加载geojson
1. 初始化地图
<div id="map"></div><style>body { margin: 0; padding: 0; }#map { position: absolute; top: 0; bottom: 0; width: 100%; }
</style>mapboxgl.accessToken = '你的密钥';
const map = new mapboxgl.Map({container: 'map',style: 'mapbox://styles/mapbox/streets-v12',center: [107.164659,33.95191],zoom: 7.5,pitch:45});2. 加载geojson数据
当地图初始化成功好后,在对地图做操作处理map.on('load',()=>{}),将geojson数据加载至地图上
fetch(url).then((response)=>{ return response.json();}).then((data)=>{dataJson = datadataJson.features.map((item, index) => {// 添加id、color、height下面做渐变展示效果item['id'] = indexitem.properties['color'] = '#9b46e1'item.properties['height'] = Math.floor(Math.random() * (10000 - 9500 + 1)) + 9500})}).catch((error)=>{})map.addSource('states', {'type': 'geojson','data': dataJson
});设置geojson图层样式,设置type加载数据类型
type类型:(根据官网使用百度翻译,如有不准确,请多指教)
- fill 填充多边形
- line 线
- symbol 图标或文本标签
- circle 圆
- heatmap 热力图
- fill-extrusion 3d立体多边形
- raster 贴图纹理,如:卫星图像
- raster-particle 贴图纹理的驱动的粒子动画
- hillshade 基于DEM数据的客户端山坡可视化。目前,该实现仅支持Mapbox Terrain RGB和 Mapzen Terrarium图块
- model 3D模型
- background 地图的背景颜色或图案
- sky 地图周围的球形圆顶,始终在所有其他层后面渲染
- slot 标记插槽的位置
- clip Layer that removes 3D content from map
map.addLayer({'id': 'state-fills','type': 'fill-extrusion','source': 'states','layout': {},'paint': {'fill-extrusion-color': {//根据数值中加载相对应颜色property: "height", stops: [[9500, "#29D2F1"],[9600, "#27C2EC"],[9700, "#18AFE7"],[9800, "#0E83DA"],[9900, "#0D80D9"],[10000, "#0B64D1"]]},"fill-extrusion-opacity":0.85,// 从source 'height'属性获取填充-挤出-高度。'fill-extrusion-height': ['get', 'height'],}});设置线条
map.addLayer({'id': 'state-borders','type': 'line','source': 'states','layout': {},'paint': {'line-color': '#627BC1','line-width': 0.8}});鼠标移入改变颜色,设置图层属性,此处是fill-extrusion类型
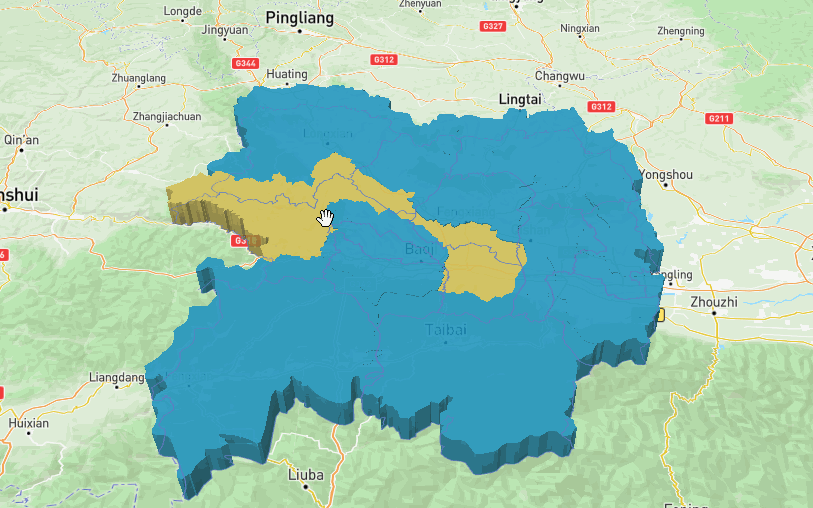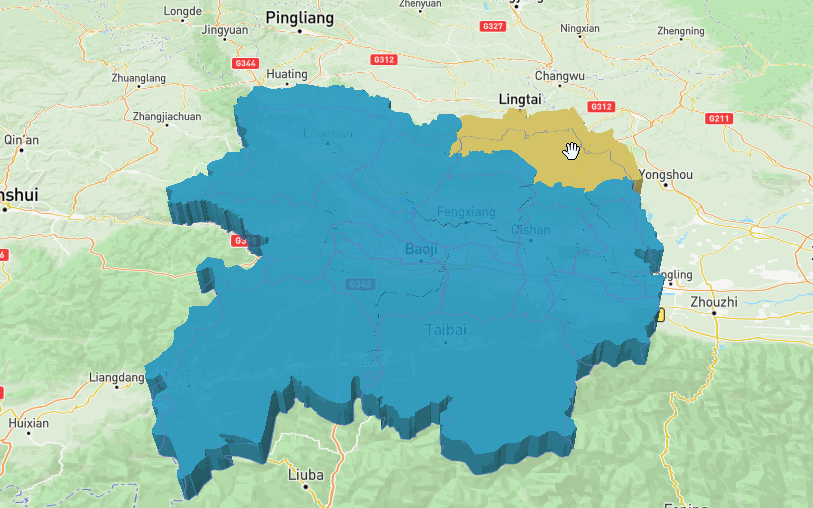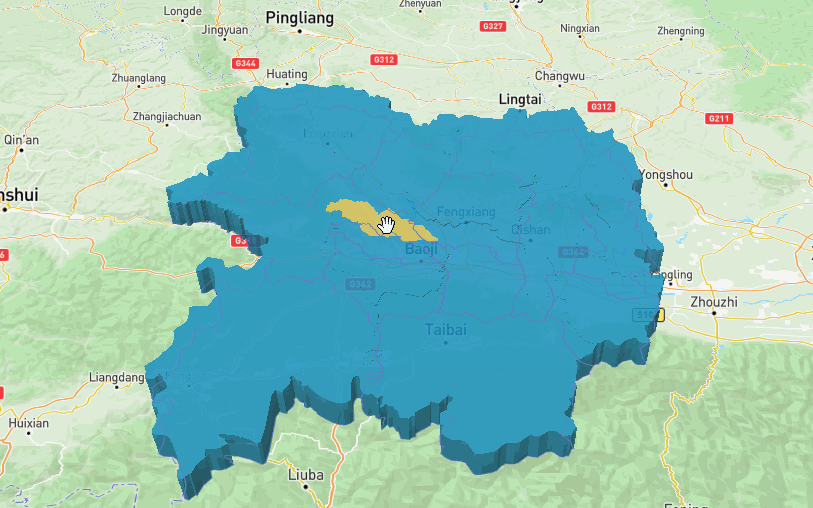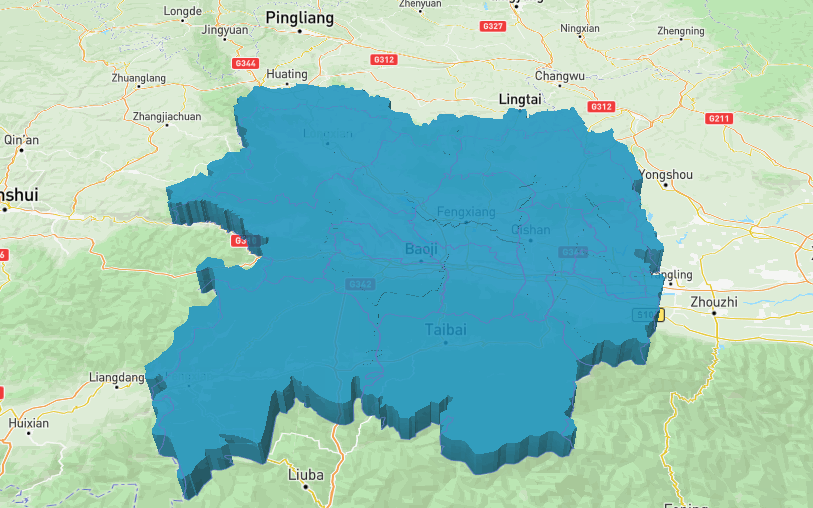
map.addLayer({'id': 'state-fills','type': 'fill-extrusion','source': 'states','layout': {},'paint': {// 设置颜色表达式'fill-extrusion-color': ['case',['boolean', ['feature-state', 'hover'], false],'rgba(255,228,96,0.80)',// 鼠标移入颜色'rgba(25,172,230,0.75)' // 默认颜色],"fill-extrusion-opacity":0.85,// 从source 'height'属性获取填充-挤出-高度。'fill-extrusion-height': ['get', 'height'],}});效果图:
方式二:使用vue加载geojson
<template><div class="mapContainer"><div id='map' style='width: 100%; height: 800px;'></div></div>
</template><script>
import 'mapbox-gl/dist/mapbox-gl.css';
import mapboxgl from 'mapbox-gl'; // or "const mapboxgl = require('mapbox-gl');"
mapboxgl.accessToken = '你的密钥';
import { nextTick, onMounted } from 'vue'export default {setup(){onMounted(()=>{const map = new mapboxgl.Map({container: 'map', style: 'mapbox://styles/mapbox/streets-v12', center: [-74.5, 40], zoom: 9,});})}}
</script>