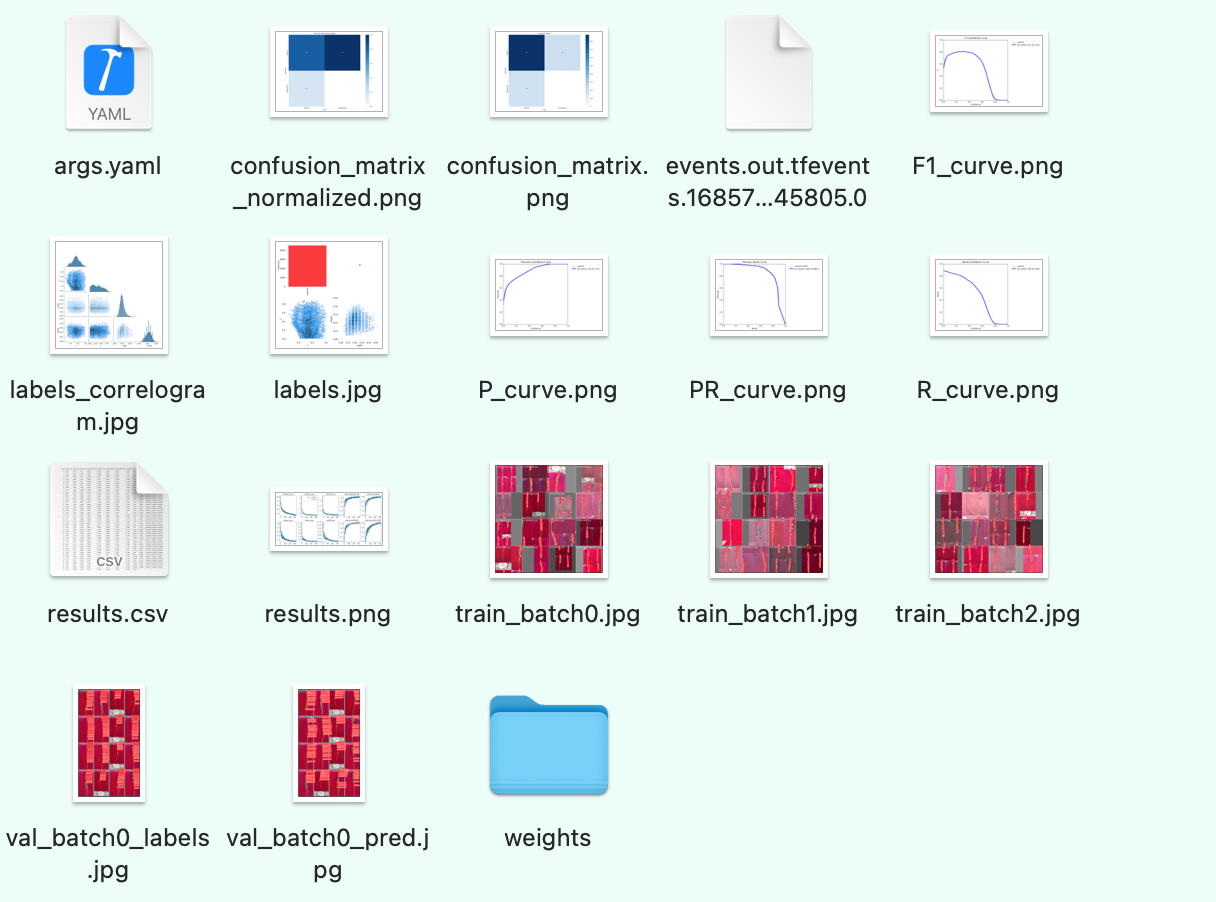
运行结果目录
一、 confusion_matrix_normalized.png和confusion_matrix.png
混淆矩阵是对分类问题预测结果的总结。使用计数值汇总正确和不正确预测的数量,并按每个类进行细分,显示了分类模型进行预测时会对哪一部分产生混淆。通过这个矩阵可以方便地看出机器是否将两个不同的类混淆了(把一个类错认成了另一个)。
混淆矩阵不仅可以让我们直观的了解分类模型所犯的错误,更重要的是可以了解哪些错误类型正在发生,正是这种对结果的分解克服了仅使用分类准确率带来的局限性(总体到细分)。
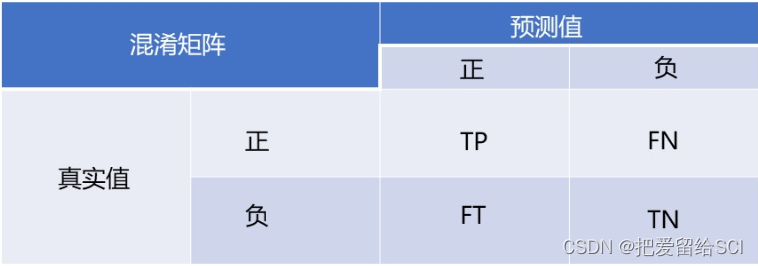
混淆矩阵
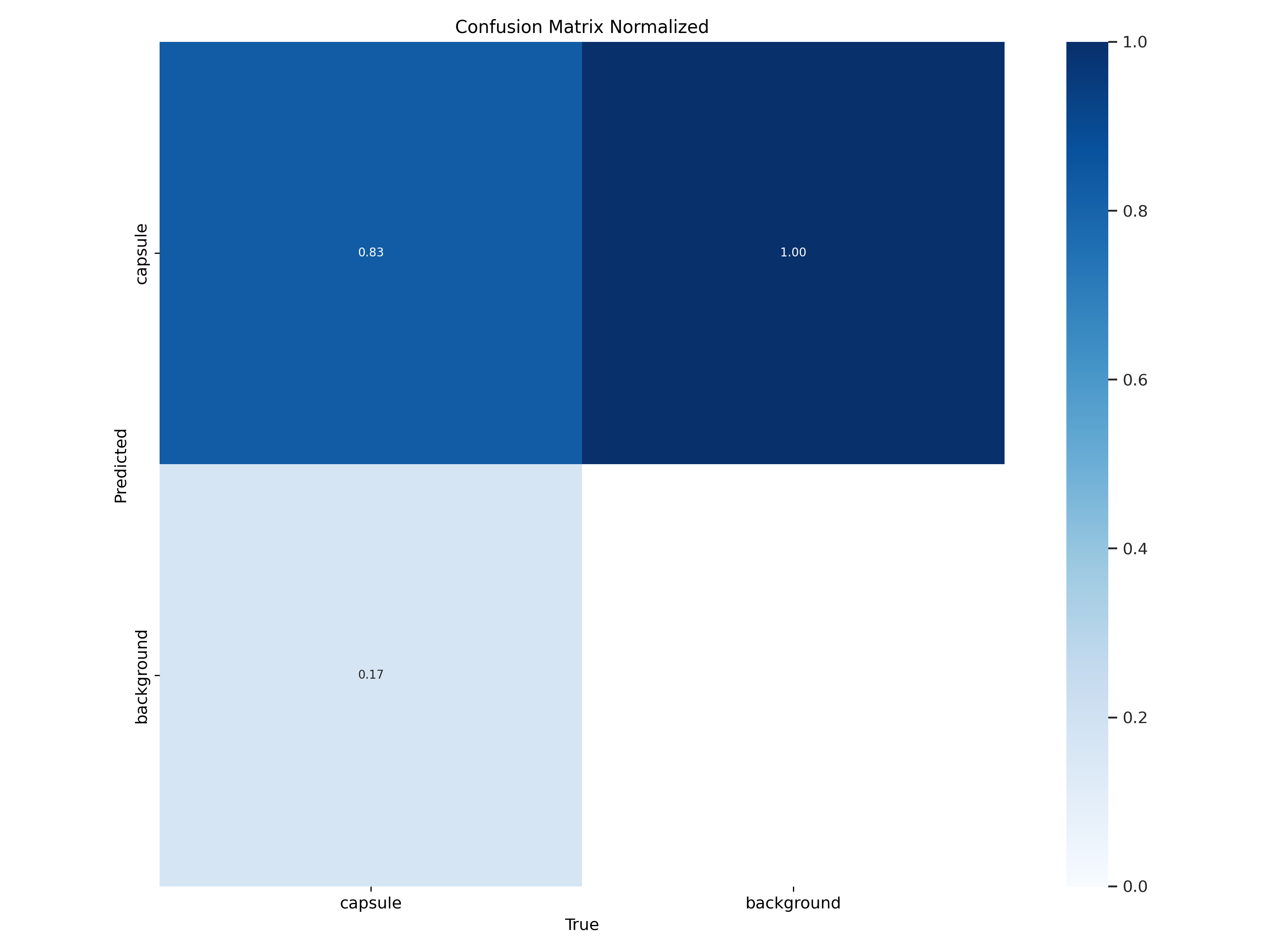
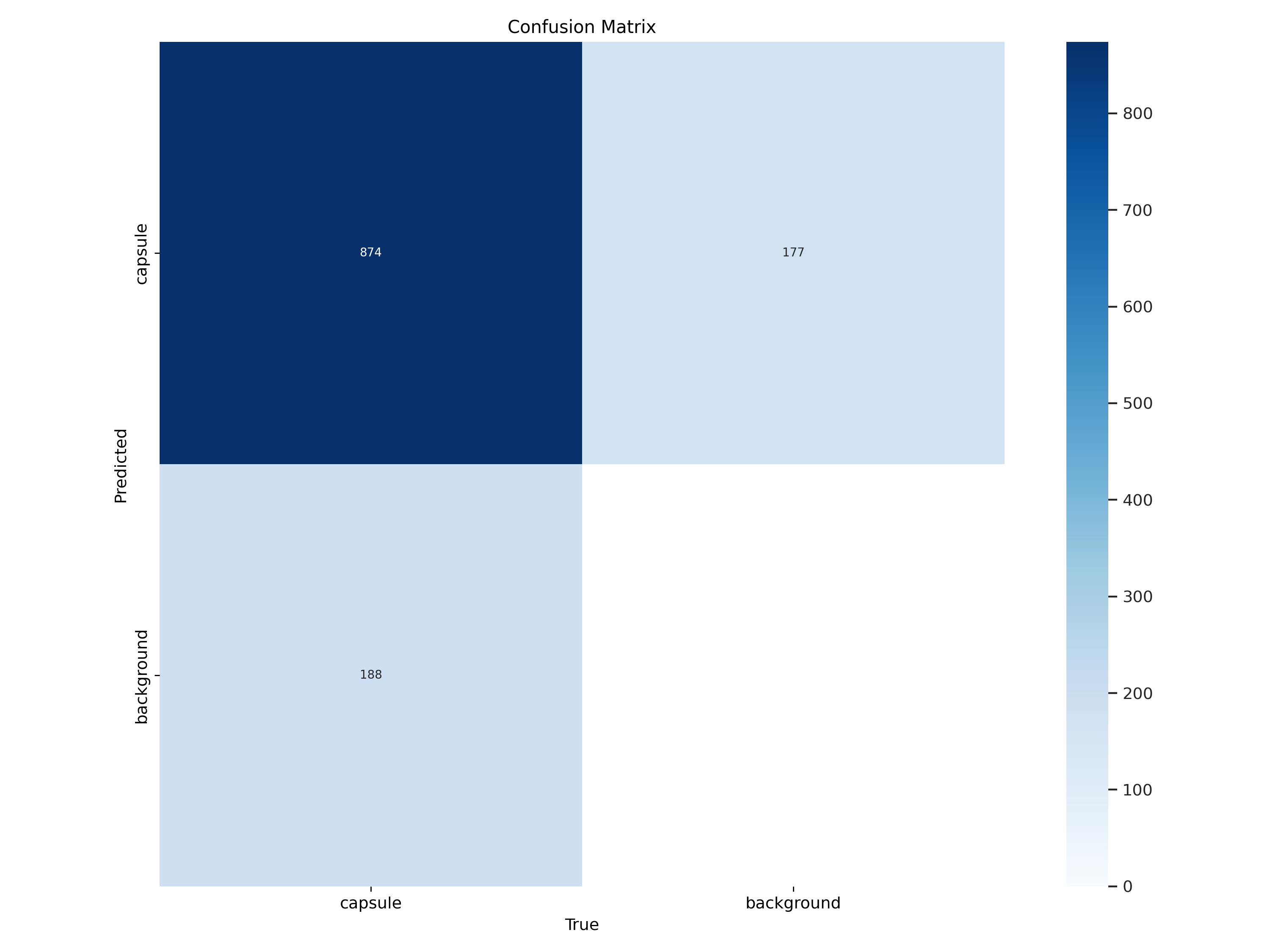
行是预测类别(y轴),列是真实类别(x轴)
混淆矩阵以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值。
- TP(True Positive): 将正类预测为正类数 即正确预测,真实为0,预测也为0
- FN (False Negative):将正类预测为负类 即错误预测,真实为0,预测为1
- FP(False Positive):将负类预测为正类数 即错误预测, 真实为1,预测为0
- TN (True Negative):将负类预测为负类数,即正确预测,真实为1,预测也为1
精确率和召回率的计算方法
- 精确率Precision=TP / (TP+FP), 在预测是Positive所有结果中,预测正确的比重
- 召回率recall=TP / (TP+FN), 在真实值为Positive的所有结果中,预测正确的比重
二、F1_curve.png
F1曲线,被定义为查准率和召回率的调和平均数
一些多分类问题的竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,其中1是最好,0是最差。
一般来说,置信度阈值(该样本被判定为某一类的概率阈值)较低的时候,很多置信度低的样本被认为是真,召回率高,精确率低;置信度阈值较高的时候,置信度高的样本才能被认为是真,类别检测的越准确,即精准率较大(只有confidence很大,才被判断是某一类别),所以前后两头的F1分数比较少。
可以看到F1曲线很“宽敞”且顶部接近1,说明在训练数据集上表现得很好(既能很好地查全,也能很好地查准)的置信度阈值区间很大。
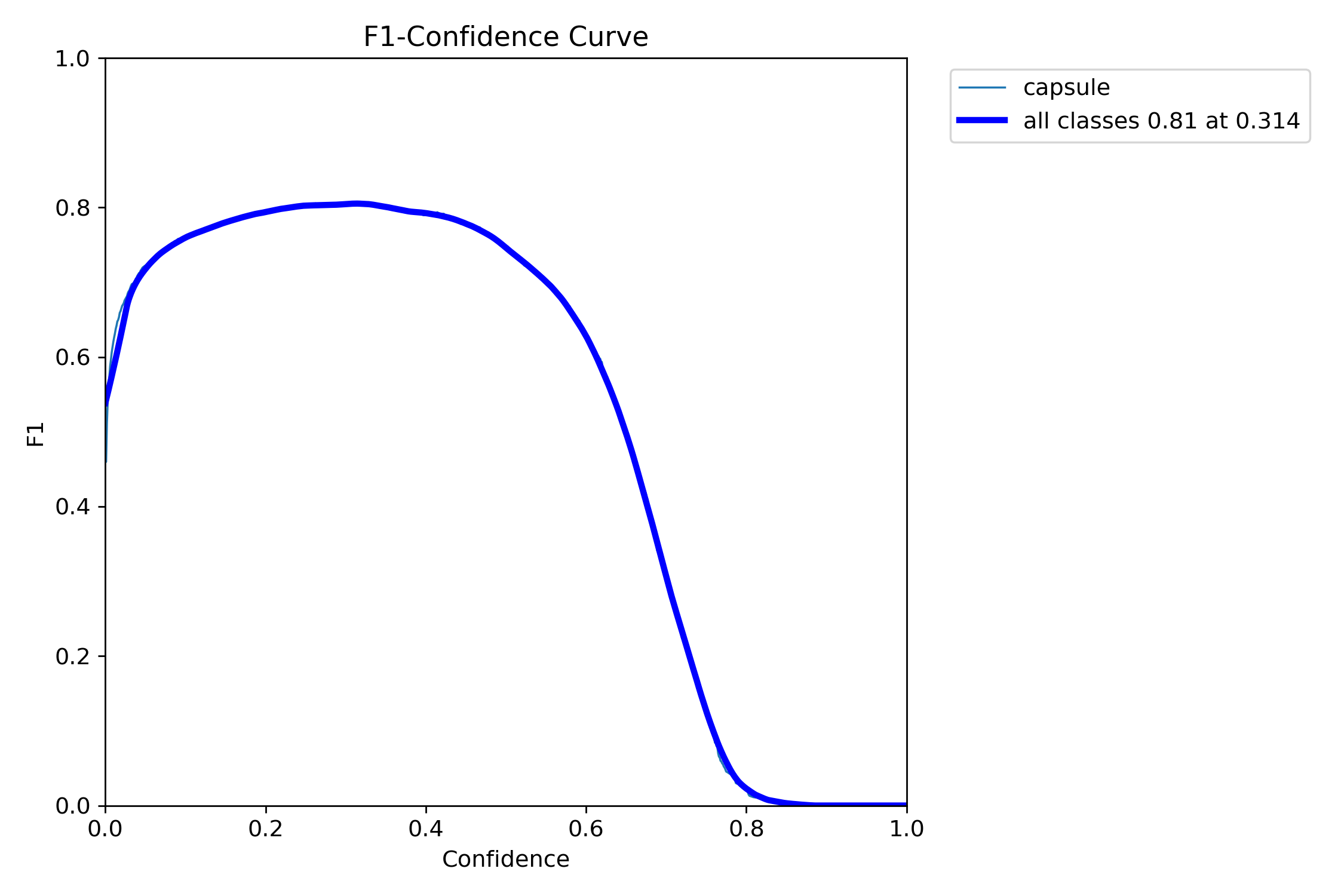

这是300epoch得到的F1_curve,说明在置信度为0.4-0.6区间内得到比较好的F1分数
三、hyp.yaml和opt.yaml
训练时的超参数以及train.py中间的参数
四、P_curve.png(单一类准确率)
准确率precision和置信度confidence的关系图
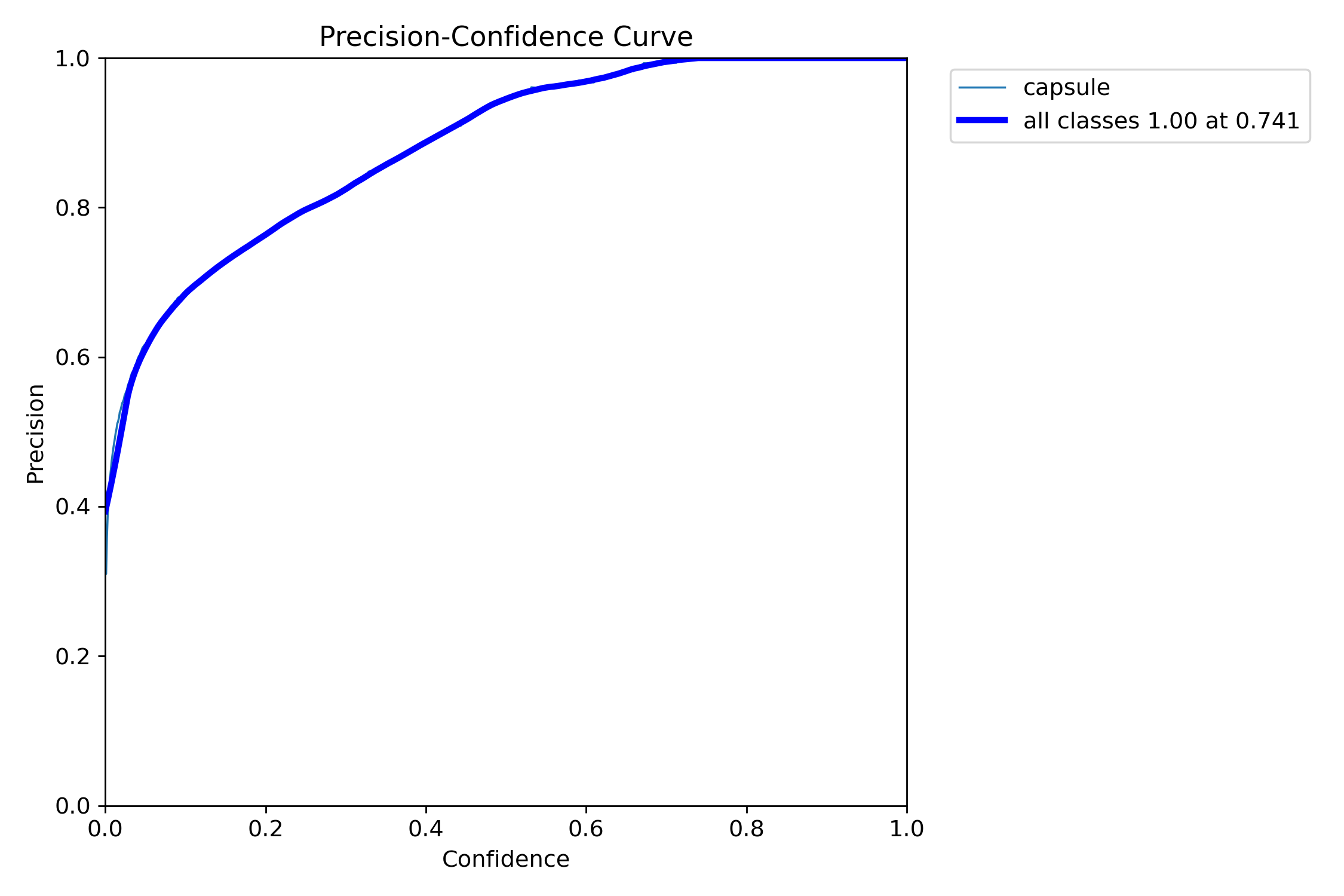
即置信度阈值 - 准确率曲线图
当判定概率超过置信度阈值时,各个类别识别的准确率。当置信度越大时,类别检测越准确,但是这样就有可能漏掉一些判定概率较低的真实样本。
五、PR_curve.png(精确率和召回率的关系图)
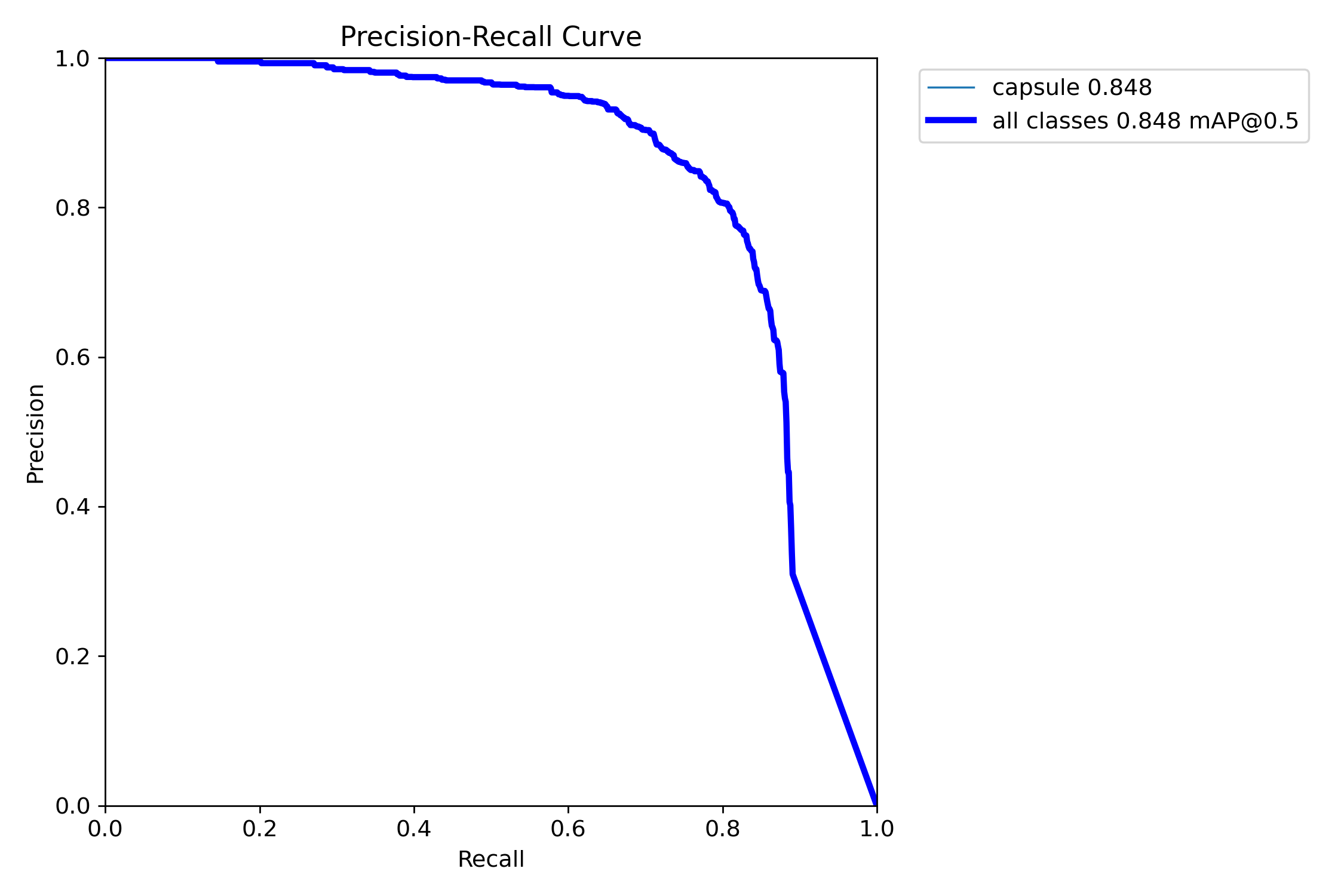
PR曲线体现精确率和召回率的关系。mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看到:精度越高,召回率越低。
因此我们希望:在准确率很高的前提下,尽可能的检测到全部的类别。因此希望我们的曲线接近(1,1),即希望mAP曲线的面积尽可能接近1。
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map.
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
Precision和Recall往往是一对矛盾的性能度量指标;及一个的值越高另一个就低一点;
提高Precision < == > 提高二分类器预测正例门槛 < == > 使得二分类器预测的正例尽可能是真实正例;
提高Recall < == > 降低二分类器预测正例门槛 < == >使得二分类器尽可能将真实的正例挑选
六、R_curve.png(单一类找回率)
召回率recall和置信度confidence之间的关系
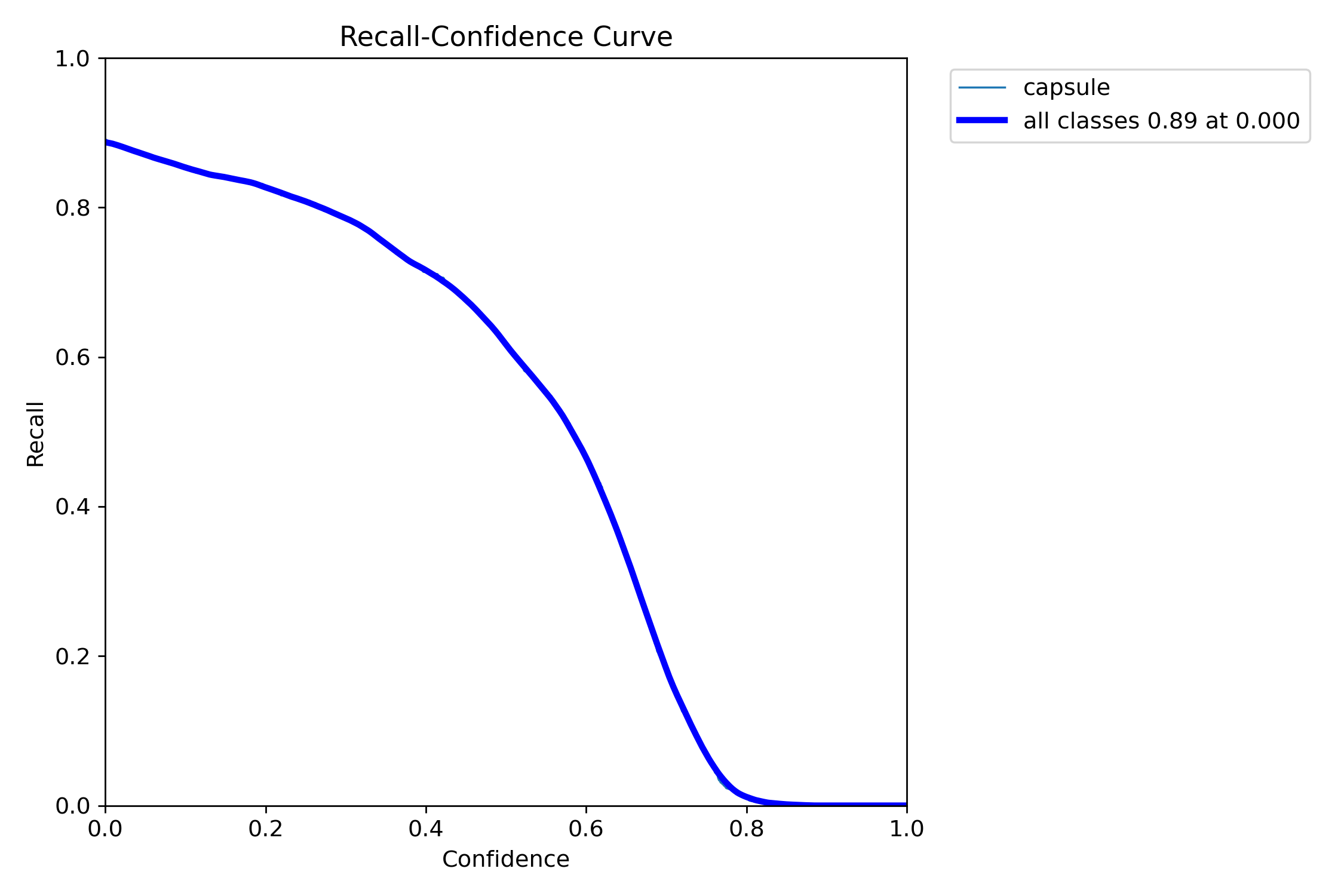
即置信度阈值 - 召回率曲线图
当置信度越小的时候,类别检测的越全面(不容易被漏掉,但容易误判)。
七、results.png
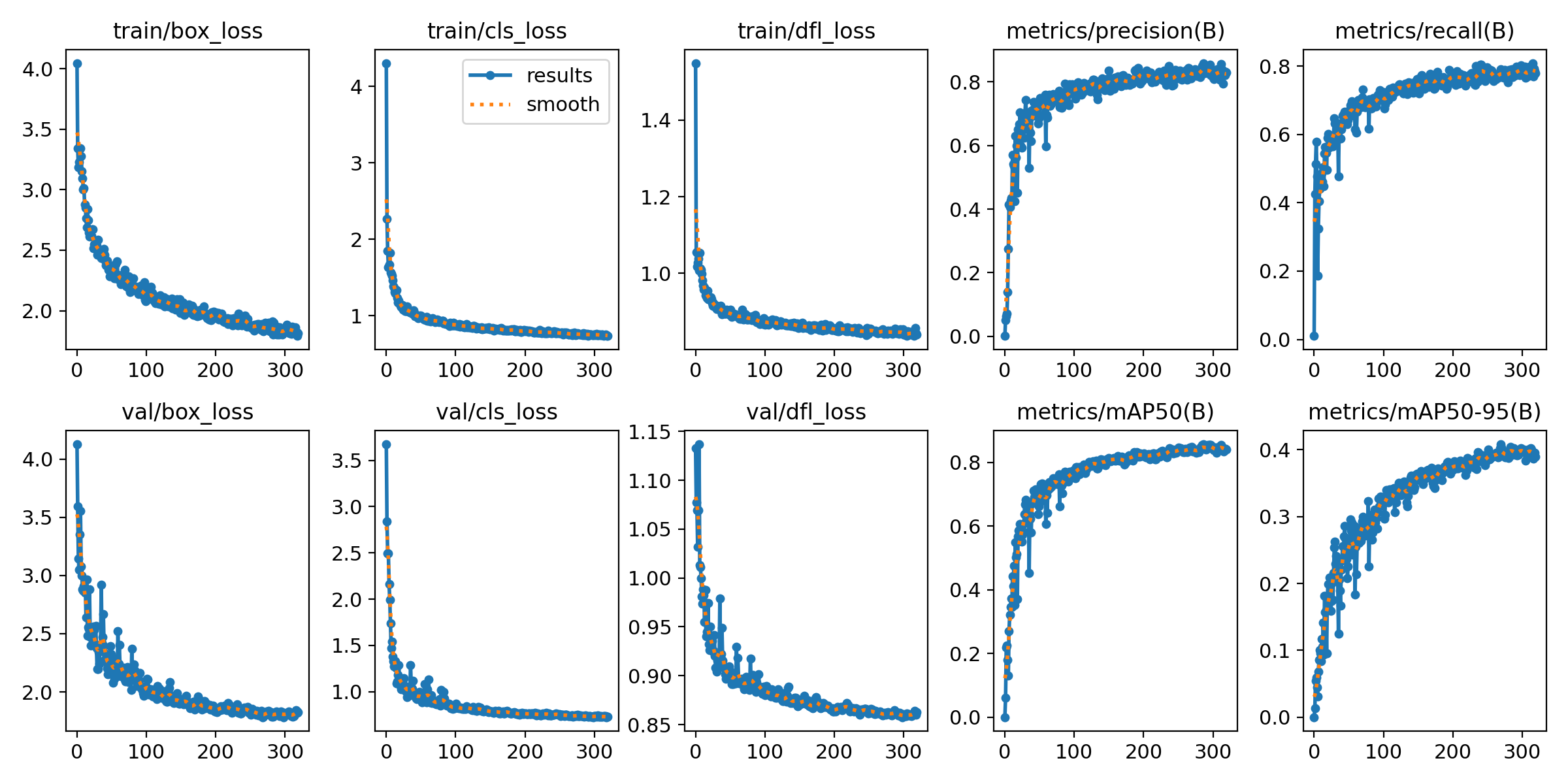
定位损失box_loss:
预测框与标定框之间的误差(CIoU),越小定位得越准;
置信度损失dfl_loss(Distribution Focal Loss):
计算网络的置信度,越小判定为目标的能力越准;
分类损失cls_loss:
计算锚框与对应的标定分类是否正确,越小分类得越准;
Precision:精度(找对的正类/所有找到的正类);
Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少)。
Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值。
mAP@.5:.95(mAP@[.5:.95])
表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
mAP@.5:表示阈值大于0.5的平均mAP
一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。
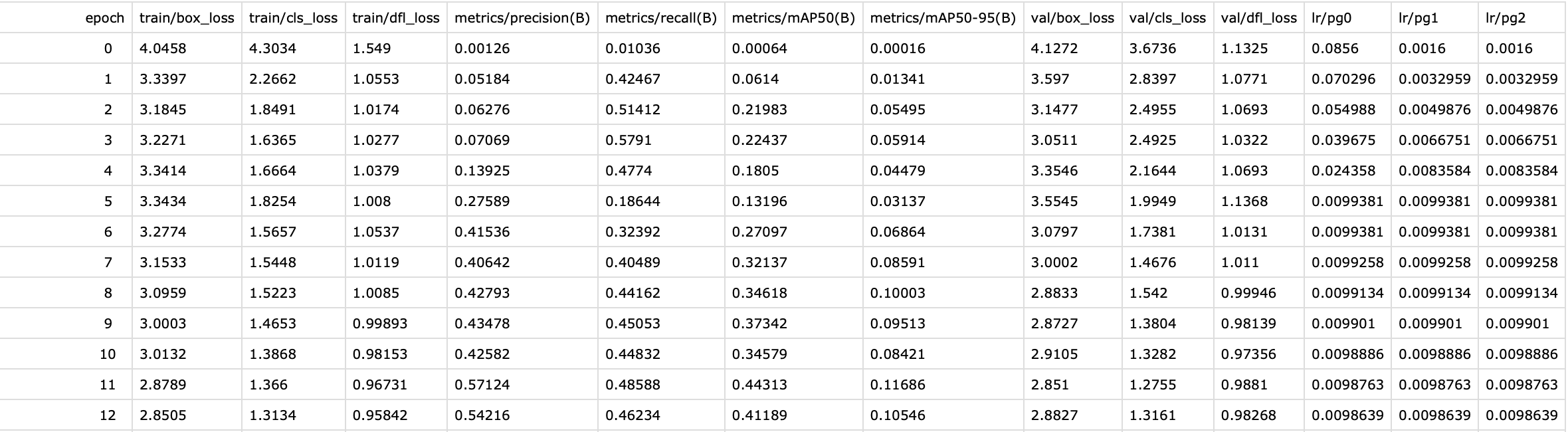
八、results.txt
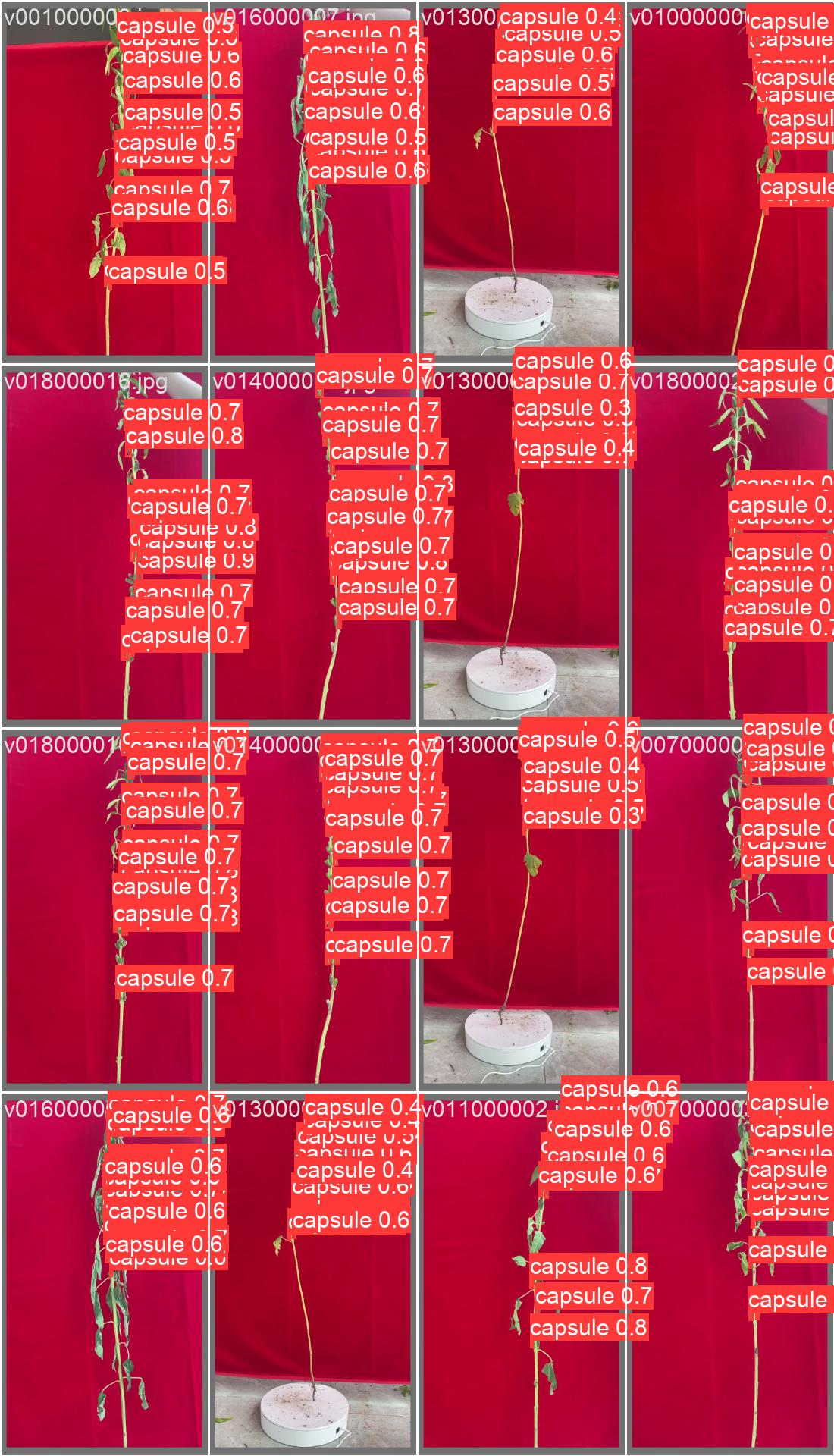
九、train_batchx
我设置的batch_size为16所以一次读取16张图片

十、val_batchx_labels
验证集第一轮的实际标签
十一、labels.jpg —— 标签
| 第一个图是训练集的数据量,每个类别有多少个 | 第二个图是框的尺寸和数量 |
| 第三个图是中心点相对于整幅图的位置 | 第四个图是图中目标相对于整幅图的高宽比例 |
十二、labels_correlogram.jpg —— 体现中心点横纵坐标以及框的高宽间的关系
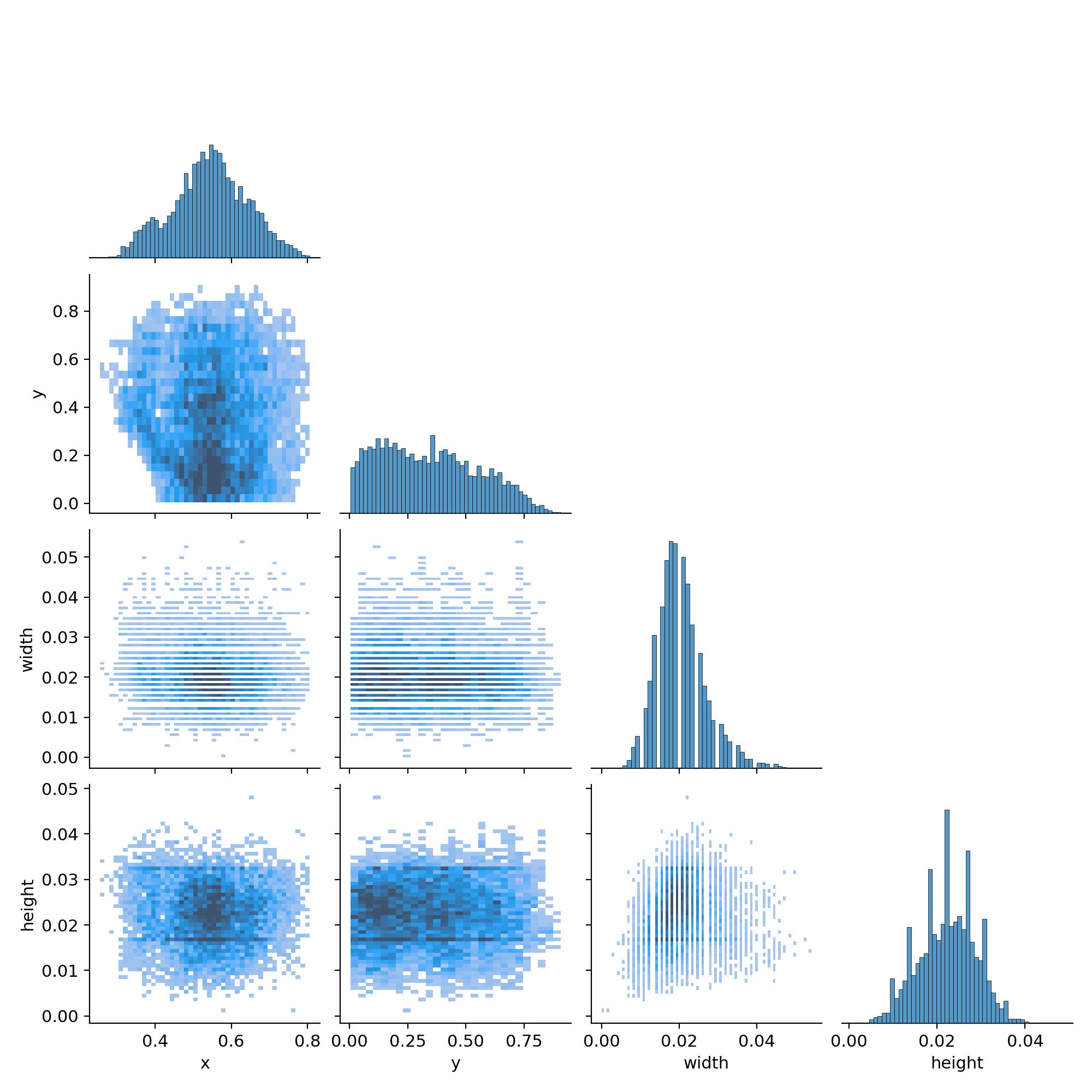
表示中心点坐标x和y,以及框的高宽间的关系。
每一行的最后一幅图代表的是x,y,宽和高的分布情况:
最上面的图(0,0)表明中心点横坐标x的分布情况,可以看到大部分集中在整幅图的中心位置;
- (1,1)图表明中心点纵坐标y的分布情况,可以看到大部分集中在整幅图的中心位置
- (2,2)图表明框的宽的分布情况,可以看到大部分框的宽的大小大概是整幅图的宽的一半
- (3,3)图表明框的宽的分布情况,可以看到大部分框的高的大小超过整幅图的高的一半
而其他的图即是寻找这4个变量间的关系
十三、运行tensorboard
activate py39_yolov8
tensorboard --logdir=训练结果所在的文件夹