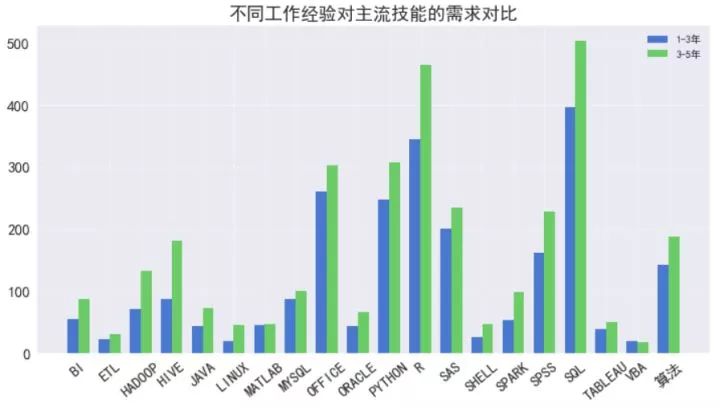
摘要:GLM-130B是一个中英双语预训练基座模型,拥有1300亿参数,模型架构采用通用语言模型GLM,其22年8月开源版本已完成4000亿token预训练。斯坦福基础模型中心22年11月对全球30个大模型进行的评测报告显示 GLM-130B在准确性和恶意性指标上与GPT-3 175B (davinci) 接近或持平,鲁棒性和校准误差在所有千亿规模的基座大模型(无指令微调)中表现优异。自8月起,GLM团队进一步向模型注入了文本和代码预训练,通过有监督微调等技术实现人类意图对齐,于23年2月开始内测 ChatGLM千亿对话模型,于3月开源ChatGLM-6B模型。此外,GLM-130B(和ChatGLM)的INT4量化版本支持在一台八卡 2080Ti 或四卡3090服务器上对1300亿全参数模型进行基本无精度损失的推理。报告将分享 GLM团队在千亿训练和ChatGLM研发过程的一点思考和尝试。
曾奥涵: 清华大学知识工程实验室一年级博士生,为开源双语预训练模型 GLM-130B 模型和 ChatGLM 系统的主要开发者之一,研究方向为自然语言处理与大规模预训练模型,指导老师为唐杰教授。