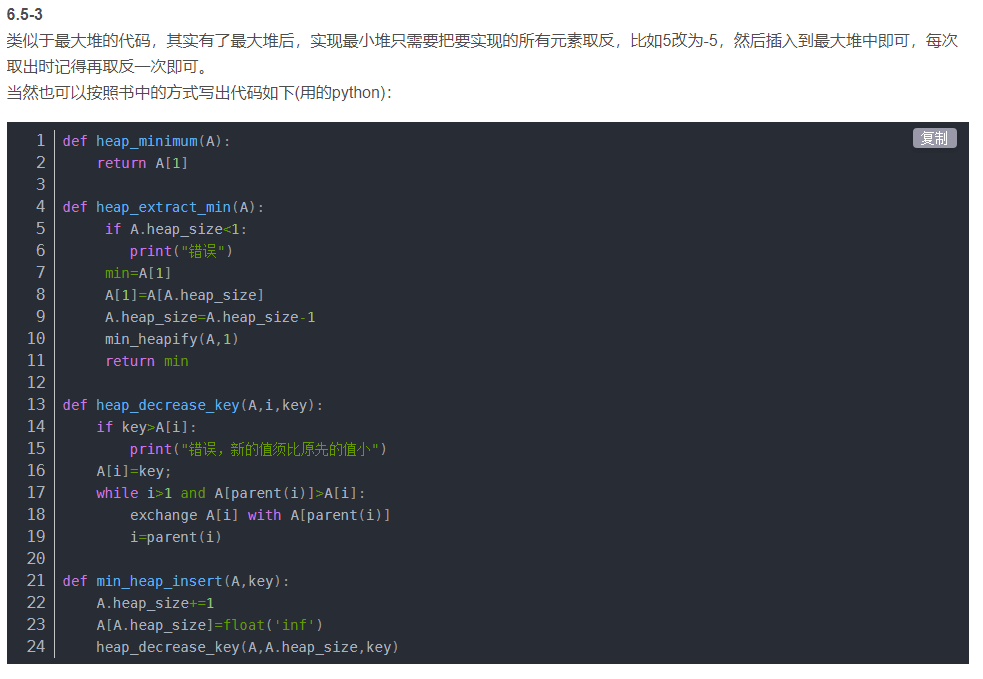
没有什么牛逼的事情是能够速成的,越是底层的、收益周期越长的技能越是这样。
但这并不代表,我们不能用一些有意思的方法,把学习的过程变得高效而有趣。
学习一门技术之前,你应该知道,你想要达成的目标是什么样的,也就是说,你想通过这门技术来解决哪些问题。有了这个目标,你就可以知道要达成这样的目标,它的知识体系是怎么样的。更重要一点的是,每个部分是用来解决哪些问题,只有明确的目标导向,学习最有用的那部分知识,才能避免无效信息降低学习效率。
明确知识框架和学习路径
比如数据分析这件事情,如果你要成为数据分析师,那么你可以去招聘网站看看,对应的职位的需求是什么,一般来说你就会对应该掌握的知识架构有初步的了解。你可以去看看数据分析师职位,企业对技能需求可总结如下:
SQL数据库的基本操作,会基本的数据管理
会用Excel/SQL做基本的数据提取、分析和展示
会用脚本语言进行数据分析,Python or R
有获取外部数据的能力加分,如爬虫或熟悉公开数据集
会基本的数据可视化技能,能撰写数据报告
熟悉常用的数据挖掘算法:回归分析、决策树、分类、聚类方法
其次是数据分析的流程,一般大致可以按“数据获取-数据存储与提取-数据预处理-数据建模与分析-数据可视化”这样的步骤来实施一个数据分析项目。按照这个流程,每个部分需要掌握的细分知识点如下:
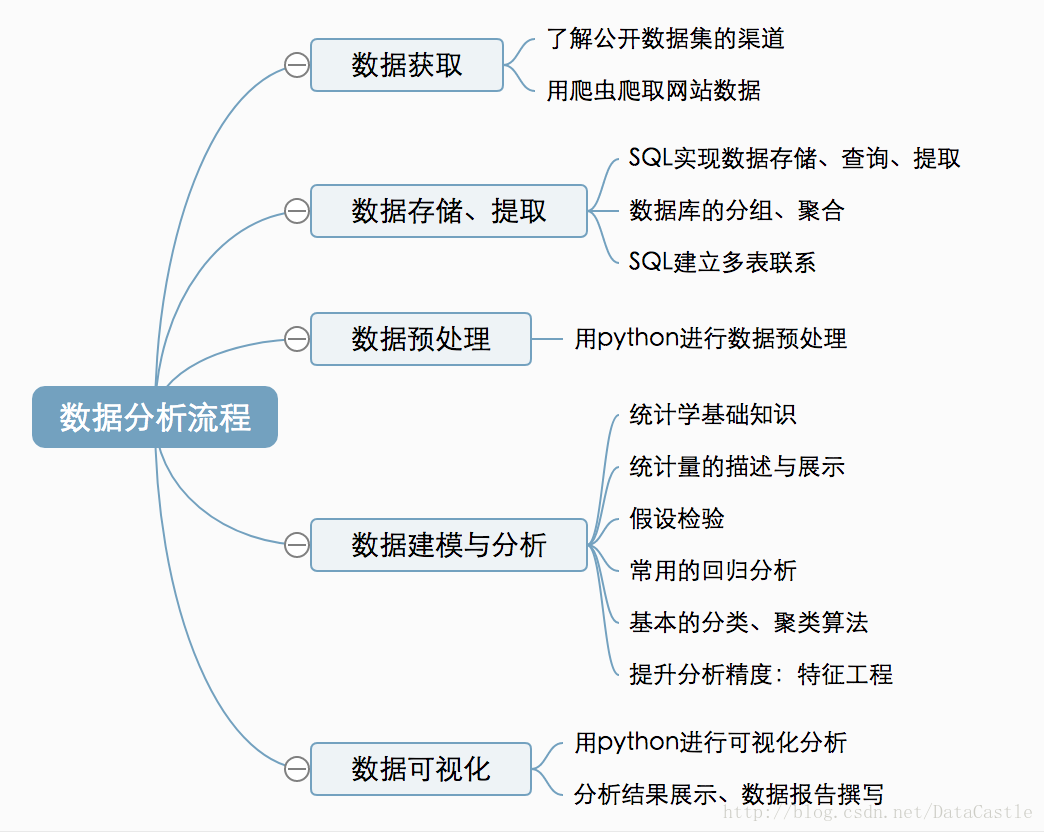
高效的学习路径是什么?就是数据分析的这个流程。按这样的顺序循序渐进,你会知道每个部分需要完成的目标是什么,需要学习哪些知识点,哪些知识是暂时不必要的。然后每学习一个部分,你就能够有一些实际的成果输出,有正向的反馈和成就感,你才会愿意花更多的时间投入进去。以解决问题为目标,效率自然不会低。
按照上面的流程,我们分需要获取外部数据和不需要获取外部数据两类分析师,总结学习路径如下:
1.需要获取外部数据分析师:
python基础知识
python爬虫
SQL语言
python科学计算包:pandas、numpy、scipy、scikit-learn
统计学基础
回归分析方法
数据挖掘基本算法:分类、聚类
模型优化:特征提取
数据可视化:seaborn、matplotlib
2.不需要获取外部数据分析师:
SQL语言
python基础知识
python科学计算包:pandas、numpy、scipy、scikit-learn
统计学基础
回归分析方法
数据挖掘基本算法:分类、聚类
模型优化:特征提取
数据可视化:seaborn、matplotlib
接下来我们分别从每一个部分讲讲具体应该学什么、怎么学。
数据获取:公开数据、Python爬虫
如果接触的只是企业数据库里的数据,不需要要获取外部数据的,这个部分可以忽略。
外部数据的获取方式主要有以下两种。
第一种是获取外部的公开数据集,一些科研机构、企业、政府会开放一些数据,你需要到特定的网站去下载这些数据。这些数据集通常比较完善、质量相对较高。给大家推荐一些常用的可以获取数据集的网站:
UCI:加州大学欧文分校开放的经典数据集,真的很经典,被很多机器学习实验室采用。
国家数据:数据来源于中国国家统计局,包含了我国经济民生等多个方面的数据。
CEIC:超过128个国家的经济数据,能够精确查找GDP, CPI, 进口,出口,外资直接投资,零售,销售,以及国际利率等深度数据。
中国统计信息网:国家统计局的官方网站,汇集了海量的全国各级政府各年度的国民经济和社会发展统计信息。
优易数据:由国家信息中心发起,拥有国家级信息资源的数据平台,国内领先的数据交易平台。
数据堂:同为数据交易平台,包含语音识别、医疗健康、交通地理、电子商务、社交网络、图像识别等方面的数据。
其他可以参考:有哪些一般人不知道的数据获取方式
另一种获取外部数据费的方式就是爬虫。
比如你可以通过爬虫获取招聘网站某一职位的招聘信息,爬取租房网站上某城市的租房信息,爬取豆瓣评分评分最高的电影列表,获取知乎点赞排行、网易云音乐评论排行列表。基于互联网爬取的数据,你可以对某个行业、某种人群进行分析。
在爬虫之前你需要先了解一些 Python 的基础知识:元素(列表、字典、元组等)、变量、循环、函数(链接的菜鸟教程非常好)……以及如何用成熟的 Python 库(urllib、BeautifulSoup、requests、scrapy)实现网页爬虫。如果是初学,建议从 urllib 和 BeautifulSoup 开始。(PS:后续的数据分析也需要 Python 的知识,以后遇到的问题也可以在这个教程查看)
网上的爬虫教程不要太多,爬虫上手推荐豆瓣的网页爬取,一方面是网页结构比较简单,二是豆瓣对爬虫相对比较友好。
掌握基础的爬虫之后,你还需要一些高级技巧,比如正则表达式、模拟用户登录、使用代理、设置爬取频率、使用cookie信息等等,来应对不同网站的反爬虫限制。
除此之外,常用的的电商网站、问答网站、点评网站、二手交易网站、婚恋网站、招聘网站的数据,都是很好的练手方式。这些网站可以获得很有分析意义的数据,最关键的是,有很多成熟的代码,可以参考。
数据存取:SQL语言
你可能有一个疑惑,为什么没有讲到Excel。在应对万以内的数据的时候,Excel对于一般的分析没有问题,一旦数据量大,就会力不从心,数据库就能够很好地解决这个问题。而且大多数的企业,都会以SQL的形式来存储数据,如果你是一个分析师,也需要懂得SQL的操作,能够查询、提取数据。
SQL作为最经典的数据库工具,为海量数据的存储与管理提供可能,并且使数据的提取的效率大大提升。你需要掌握以下技能:
提取特定情况下的数据:企业数据库里的数据一定是大而繁复的,你需要提取你需要的那一部分。比如你可以根据你的需要提取2017年所有的销售数据、提取今年销量最大的50件商品的数据、提取上海、广东地区用户的消费数据……,SQL可以通过简单的命令帮你完成这些工作。
数据库的增、删、查、改:这些是数据库最基本的操作,但只要用简单的命令就能够实现,所以你只需要记住命令就好。
数据的分组聚合、如何建立多个表之间的联系:这个部分是SQL的进阶操作,多个表之间的关联,在你处理多维度、多个数据集的时候非常有用,这也让你可以去处理更复杂的数据。
SQL这个部分相对来说比较简单,可以去这个教程:MySQL-菜鸟教程
简单到怀疑人生,学完这个教程的内容就够了。当然,还是建议你找一个数据集来实际操作一下,哪怕是最基础的查询、提取等操作。你可以去调用一些公司的数据来进行实际的演练,如果没有合适的,这里推荐UCI经典的鸢尾花数据集。
数据预处理:Python(pandas)
很多时候我们拿到的数据是不干净的,数据的重复、缺失、异常值等等,这时候就需要进行数据的清洗,把这些影响分析的数据处理好,才能获得更加精确地分析结果。
比如空气质量的数据,其中有很多天的数据由于设备的原因是没有监测到的,有一些数据是记录重复的,还有一些数据是设备故障时监测无效的。比如用户行为数据,有很多无效的操作对分析没有意义,就需要进行删除。
那么我们需要用相应的方法去处理,比如残缺数据,我们是直接去掉这条数据,还是用临近的值去补全,这些都是需要考虑的问题。
对于数据预处理,学会 pandas 的用法,应对一般的数据清洗就完全没问题了。需要掌握的知识点如下:
选择:数据访问(标签、特定值、布尔索引等)
缺失值处理:对缺失数据行进行删除或填充
重复值处理:重复值的判断与删除
空格和异常值处理:清楚不必要的空格和极端、异常数据
相关操作:描述性统计、Apply、直方图等
合并:符合各种逻辑关系的合并操作
分组:数据划分、分别执行函数、数据重组
Reshaping:快速生成数据透视表
网上有很多pandas的教程,主要是一些函数的应用,也都非常简单,如果遇到问题,可以参看pandas操作的官方文档。
推荐书:利用Python进行数据分析 (豆瓣)
概率论及统计学知识
数据整体分布是怎样的?什么是总体和样本?中位数、众数、均值、方差等基本的统计量如何应用?如果有时间维度的话随着时间的变化是怎样的?如何在不同的场景中做假设检验?数据分析方法大多源于统计学的概念,所以统计学的知识也是必不可少的。需要掌握的知识点如下:
基本统计量:均值、中位数、众数、百分位数、极值等
其他描述性统计量:偏度、方差、标准差、显著性等
其他统计知识:总体和样本、参数和统计量、ErrorBar
概率分布与假设检验:各种分布、假设检验流程
其他概率论知识:条件概率、贝叶斯等
有了统计学的基本知识,你就可以用这些统计量做基本的分析了。通过可视化的方式来描述数据的指标,其实可以得出很多结论了,比如排名前100的是哪些,平均水平是怎样的,近几年的变化趋势如何……
你可以使用python的包 Seaborn(python包)在做这些可视化的分析,你会轻松地画出各种可视化图形,并得出具有指导意义的结果。了解假设检验之后,可以对样本指标与假设的总体指标之间是否存在差别作出判断,已验证结果是否在可接受的范围。
推荐书:深入浅出统计学 (豆瓣)
python数据分析
如果你有一些了解的话,就知道目前市面上其实有很多 Python 数据分析的书籍,但每一本都很厚,学习阻力非常大。但其实真正最有用的那部分信息,只是这些书里很少的一部分。比如用 Python 实现不同案例的假设检验,其实你就可以对数据进行很好的验证。
比如掌握回归分析的方法,通过线性回归和逻辑回归,其实你就可以对大多数的数据进行回归分析,并得出相对精确地结论。比如DataCastle的训练竞赛“房价预测”和“职位预测”,都可以通过回归分析实现。这部分需要掌握的知识点如下:
回归分析:线性回归、逻辑回归
基本的分类算法:决策树、随机森林……
基本的聚类算法:k-means……
特征工程基础:如何用特征选择优化模型
调参方法:如何调节参数优化模型
Python 数据分析包:scipy、numpy、scikit-learn等
在数据分析的这个阶段,重点了解回归分析的方法,大多数的问题可以得以解决,利用描述性的统计分析和回归分析,你完全可以得到一个不错的分析结论。
当然,随着你实践量的增多,可能会遇到一些复杂的问题,你就可能需要去了解一些更高级的算法:分类、聚类,然后你会知道面对不同类型的问题的时候更适合用哪种算法模型,对于模型的优化,你需要去学习如何通过特征提取、参数调节来提升预测的精度。这就有点数据挖掘和机器学习的味道了,其实一个好的数据分析师,应该算是一个初级的数据挖掘工程师了。
推荐:scikit-learn官方文档
系统实战
这个时候,你就已经具备了数据分析的基本能力了。但是还要根据不同的案例、不同的业务场景进行实战。能够独立完成分析任务,那么你就已经打败市面上大部分的数据分析师了。
如何进行实战呢?
上面提到的公开数据集,可以找一些自己感兴趣的方向的数据,尝试从不同的角度来分析,看看能够得到哪些有价值的结论。
另一个角度是,你可以从生活、工作中去发现一些可用于分析的问题,比如上面说到的电商、招聘、社交等平台等方向都有着很多可以挖掘的问题。
开始的时候,你可能考虑的问题不是很周全,但随着你经验的积累,慢慢就会找到分析的方向,有哪些一般分析的维度,比如top榜单、平均水平、区域分布、年龄分布、相关性分析、未来趋势预测等等。随着经验的增加,你会有一些自己对于数据的感觉,这就是我们通常说的数据思维了。
你也可以看看行业的分析报告,推荐:艾瑞咨询
看看优秀的分析师看待问题的角度和分析问题的维度,其实这并不是一件困难的事情。
在掌握了初级的分析方法之后,也可以尝试做一些数据分析的竞赛,比如 DataCastle 为数据分析师专门定制的三个竞赛,提交答案即可获取评分和排名:
员工离职预测训练赛
美国King County房价预测训练赛
北京PM2.5浓度分析训练赛
你也可以关注一些知乎大V,他们的经验可能让你少走弯路。
@邹昕
@卡牌大师
@Han Hsiao
@何明科
@chenqin
@桑文锋
知乎上还有一些非常好的数据分析专栏,经常会有一些有意思的文章。
数据冰山
数据分析侠
董老师在硅谷
一个数据分析师的自我修养
你看,其实梳理一遍之后是不是清晰了很多。把每一个部分的内容找来学习就可以了,但一定要在学习过程中找不同的问题来实践,在实践中发现问题去寻找答案,补足知识。种一棵树最好的时间是十年前,其次是现在。现在就去,找一个数据集开始吧!!
DC学院总结了无数的优秀分析师爬坑经验,和无数的数据分析书籍,开了一门系统数据分析课,就是按照以上的学习路径。如果你有兴趣,可以看看:数据分析师(入门)-DC学院
关注公众号(datacastle2016),获取更多数据分析干货。