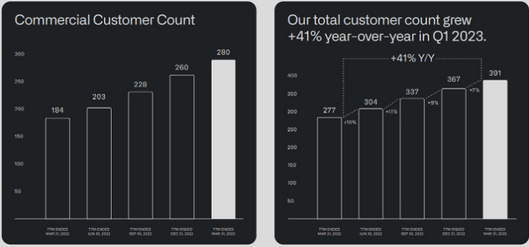
在数据加工好以后,我们用TensorFlow做简单的预测。
按之前的做法去读取并加载数据
data,date= dp.readData()train,test,trainLables,testLabels= dp.normalization(data)然后添加变量和参数
x = tf.placeholder("float",[None,109])w = tf.Variable(tf.random_normal([109,21]))b = tf.Variable(tf.random_normal([21]))y = tf.nn.softmax(tf.matmul(x,w)+b)y_ = tf.placeholder("float",[None,21])#损失函数cross_entropy = -tf.reduce_sum(y_*tf.log(y+1e-9)) #设定学习率随时间递减global_step = tf.Variable(0, trainable=False)initial_learning_rate = 0.0001 #初始学习率learning_rate = tf.train.exponential_decay(initial_learning_rate,global_step=global_step,decay_steps=10,decay_rate=0.9)训练过程采用梯度下降法进行反向传播:
#训练过程梯度下降法最小化损失函数train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)# Create a saver for writing training checkpoints.saver = tf.train.Saver()#初始化sessioninit = tf.initialize_all_variables()sess = tf.Session()sess.run(init)for i in range(5000):#取随机100个训练样本batch_xs,batch_ys = dp.random_batch(train,trainLables,100)sess.run(train_step,feed_dict = {x:batch_xs,y_:batch_ys})#每10步进行测试if i%100==0 or i == 4999:checkpoint_file = os.path.join(LOG_DIR, 'model.ckpt')saver.save(sess, checkpoint_file, global_step=i)correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))batch_test_xs,batch_test_ys = dp.random_batch(test,testLabels,100)accuracy = tf.reduce_mean(tf.cast(correct_prediction,"float"))accuracy,argmaxN =sess.run([accuracy,tf.argmax(y,1)],feed_dict = {x:batch_test_xs,y_:batch_test_ys})print ("正确率为:",accuracy,"测试结果为:",argmaxN)测试的正确率按计算结果与真实结果四舍五入后的整数相等做判断,因此存在一定误差。
采用此方法最后计算得到的准确率在30%-40%之间,因为模型和数据的简陋性,此结果算是可以接受的准确率。
然而事后进行分析,预测结果大部分分布在tf.argmax(y,1)=10处,意为涨跌幅预测为0,而实际中上证指数涨跌幅四舍五入后为零的情况非常常见,因此此模型准确率的意义不大,后续考虑涨跌幅较大的个股做以模拟,以继续探索股票预测的可用模型。
本文所涉及代码如下,引用本文及代码请注明出处。
https://github.com/renmu2017/predictStock.git