程序主要采用Python 爬虫+flask框架+html+javascript实现岗位推荐分析可视化系统,实现工作岗位的实时发现,推荐检索,快速更新以及工作类型的区域分布效果,关键词占比分析等。
程序模块实现
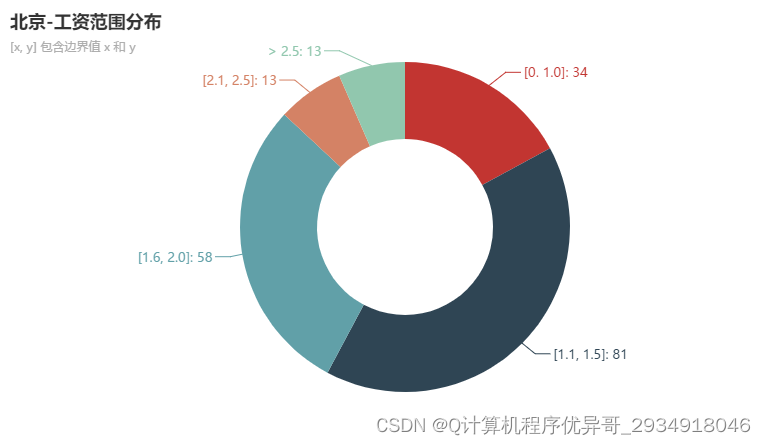
工作范围分布
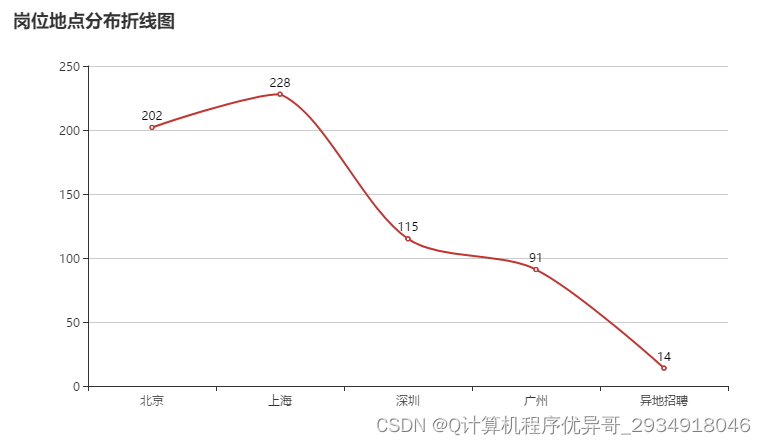
岗位区域分布
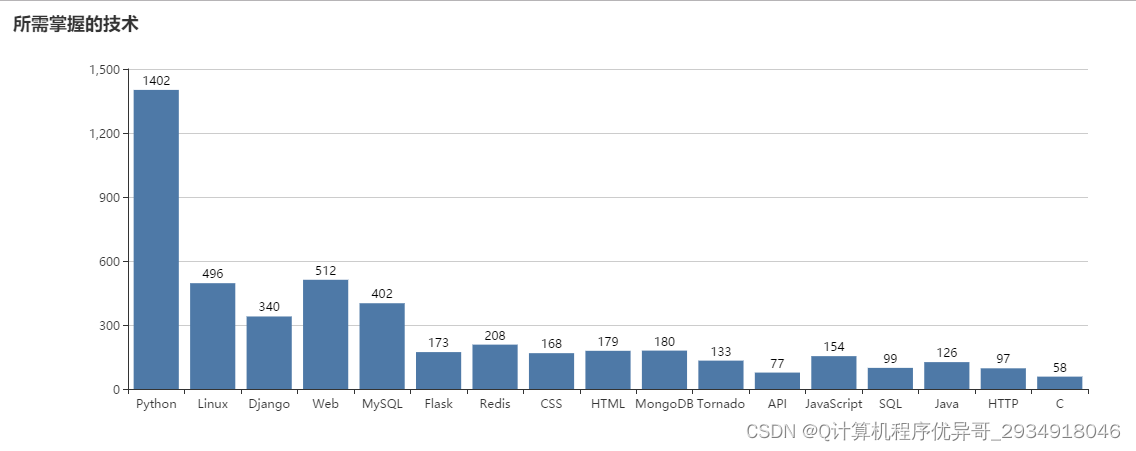
岗位技术情况
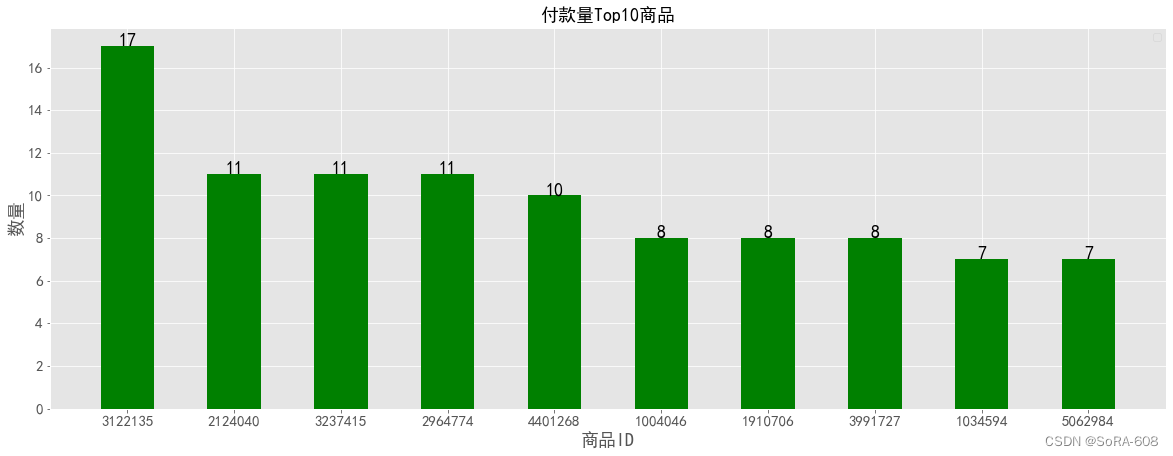
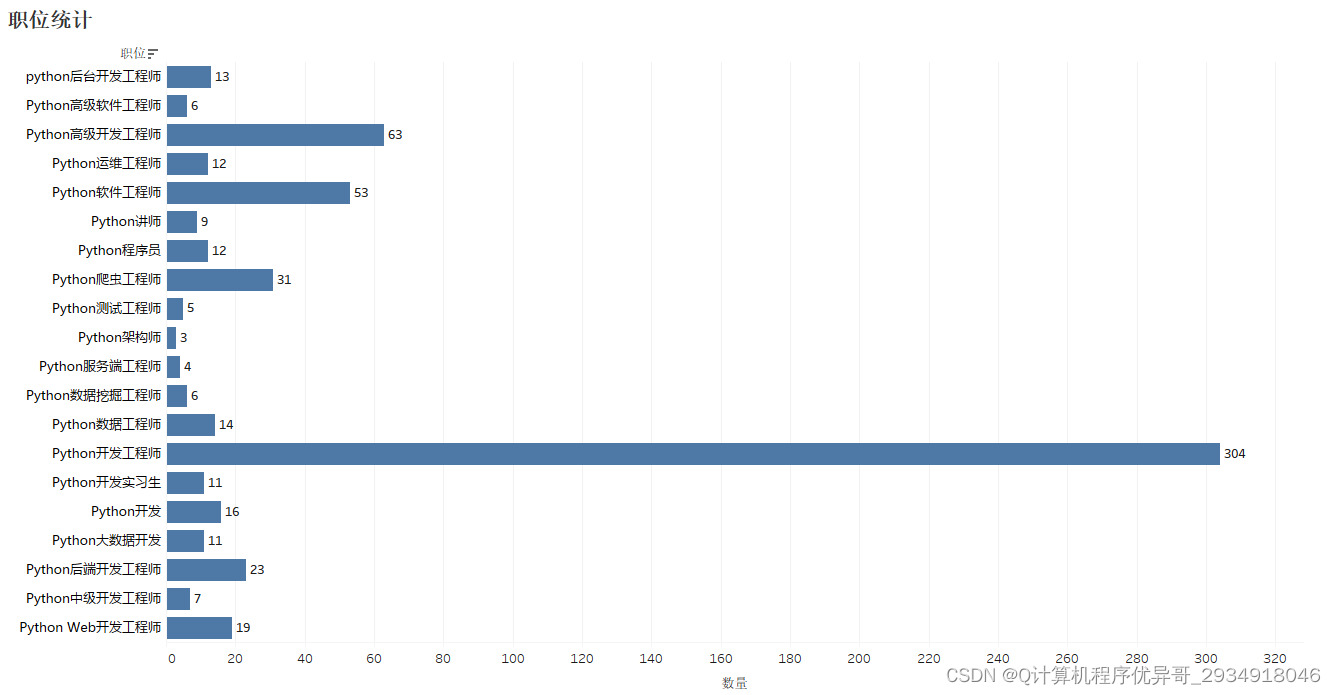
岗位招聘统计
招聘关键词分析

源码地址
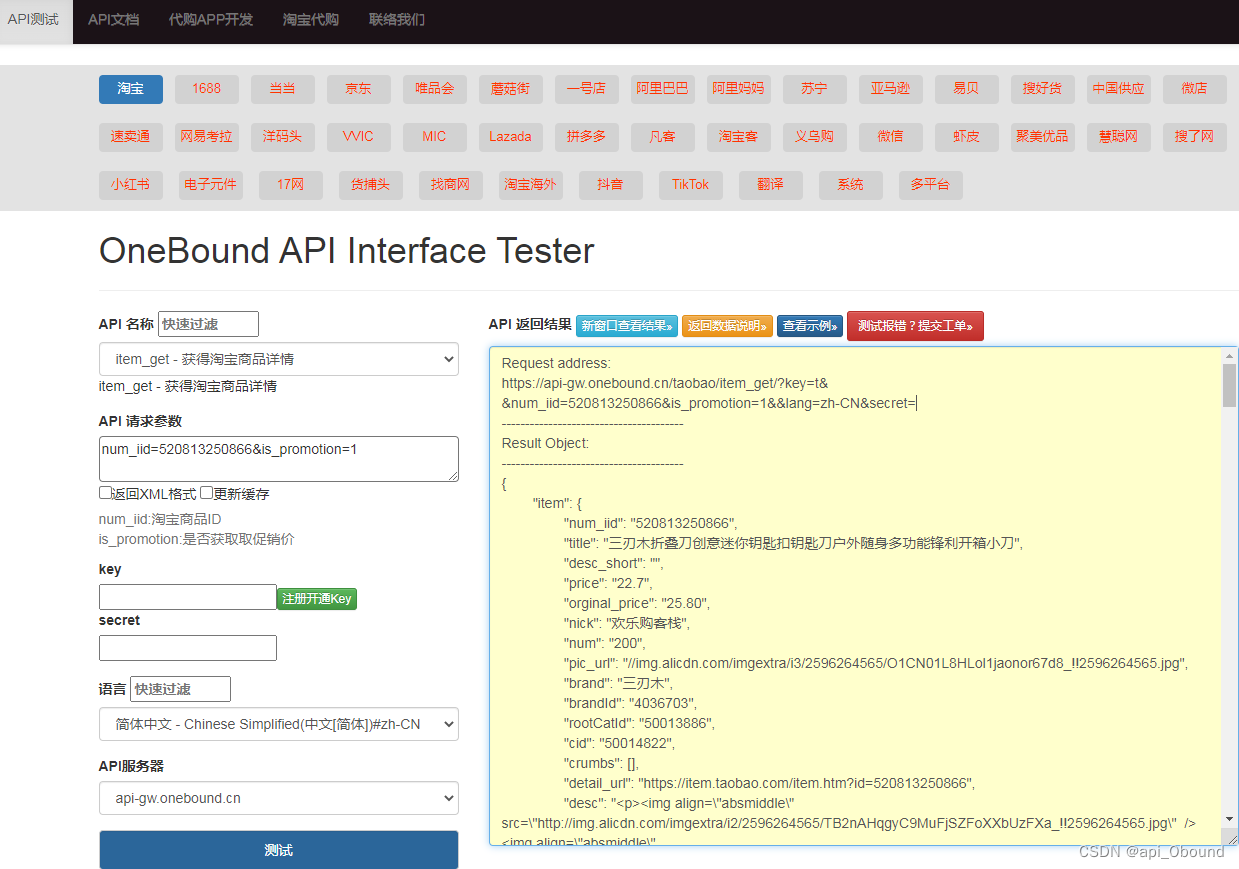
Python爬虫设计
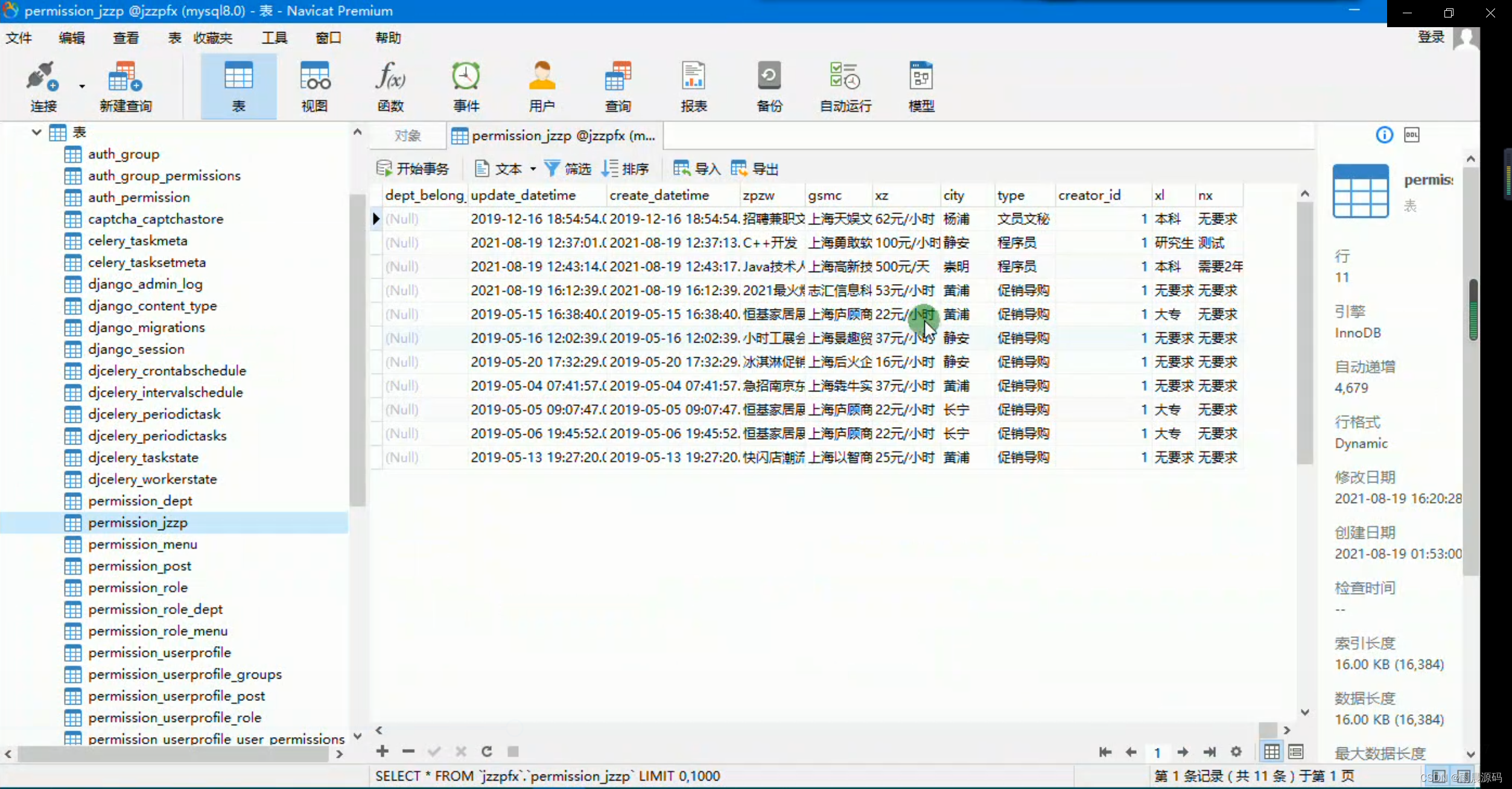
本次毕设系统在Python爬虫模块设计中,主要采用51Job作为数据收集来源,利用Python Request模块实现对站点岗位数据的收集与去重,动态过滤种子URL地址,写入Mysql数据库,完成工作岗位数据的采集与分析。
爬虫程序实现
部分核心代码
class HubTaskWorkSpider:"""51 job 网站爬虫类"""def __init__(self):self.count = 1 # 记录当前爬第几条数据self.company = []self.desc_url_queue = Queue() # 线程池队列self.pool = Pool(POOL_MAXSIZE) # 线程池管理线程,最大协程数def work_spider(self):"""爬虫入口"""urls = [START_URL.format(p) for p in range(1, 16)]for url in urls:logger.info("爬取第 {} 页".format(urls.index(url) + 1))html = requests.get(url, headers=HEADERS).content.decode("gbk")bs = BeautifulSoup(html, "lxml").find("div", class_="dw_table").find_all("div", class_="el")for b in bs:try:href, post = b.find("a")["href"], b.find("a")["title"]locate = b.find("span", class_="t3").textsalary = b.find("span", class_="t4").textitem = {"href": href, "post": post, "locate": locate, "salary": salary}self.desc_url_queue.put(href) # 岗位详情链接加入队列self.company.append(item)except Exception:pass# 打印队列长度,即多少条岗位详情 urllogger.info("队列长度为 {} ".format(self.desc_url_queue.qsize()))@staticmethoddef insert_into_db():"""插入数据到数据库create table jobpost(j_salary float(3, 1),j_locate text,j_post text);"""conn = pymysql.connect(host="****",port=****,user="root",paswd="****",db="AAAA",charset="utf8",)cur = conn.cursor()with open(os.path.join("data", "post_salary.csv"), "r", encoding="utf-8") as f:f_csv = csv.reader(f)sql = "insert into jobpost(j_salary, j_locate, j_post) values(%s, %s, %s)"for row in f_csv:value = (row[0], row[1], row[2])try:cur.execute(sql, value)conn.commit()except Exception as e:logger.error(e)cur.close()def run(self):"""多线程爬取数据"""self.job_spider()self.execute_more_tasks(self.post_require)self.desc_url_queue.join() # 主线程阻塞,等待队列清空def execute_more_tasks(self, target):"""协程池接收请求任务,可以扩展把解析,存储耗时操作加入各自队列,效率最大化:param target: 任务函数:param count: 启动线程数量"""for i in range(POOL_MAXSIZE):self.pool.apply_async(target)if __name__ == "__main__":spider = JobSpider()start = time.time()spider.run()logger.info("总耗时 {} 秒".format(time.time() - start))
本系统整体难度较低,主要包括三个步骤:收集招聘岗位数据,整理数据分析统计维度,结合echarts图表实现动态展示及推荐等。本系统采用Python语言开发,所用开发工具有pycharm 2022、visual studio code、在线uml制作工具process on、Mysql5.7、 插件包含Resharper、SQL Prompt等。
源码地址