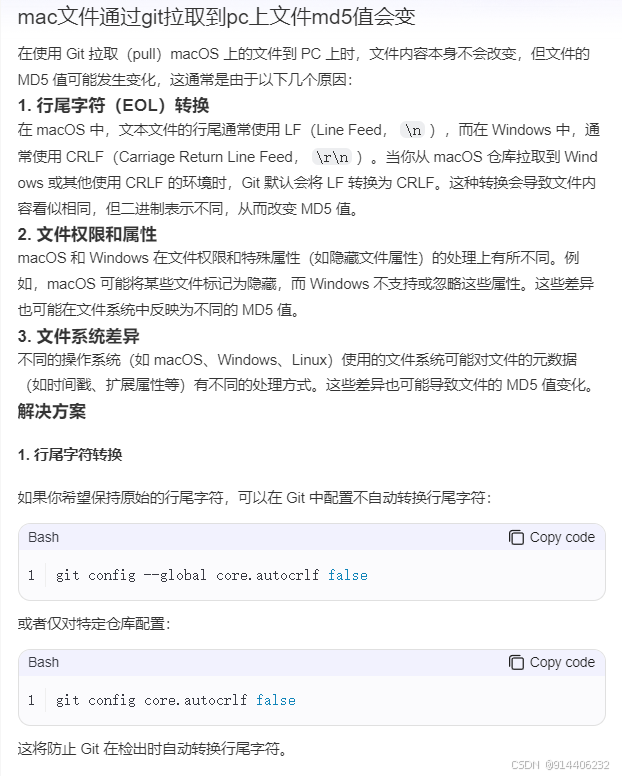
Java学习资料
Java学习资料
Java学习资料
在 Java 编程世界里,多态与接口是两个极为重要的概念,它们为开发者构建灵活、可扩展且易于维护的程序提供了强大的支持。深入理解这两个概念及其相互关系,对于提升 Java 编程能力至关重要。
一、多态的概念与实现
1.1 多态的定义
多态,简单来说,就是同一个行为具有多个不同表现形式或形态的能力。在 Java 中,多态意味着可以通过父类的引用调用子类的方法,程序在运行时才确定具体调用的是哪个子类的方法。例如,定义一个动物类Animal,以及它的子类Dog和Cat,它们都有makeSound方法,但发出的声音不同。通过Animal类的引用,可以调用不同子类的makeSound方法,产生不同的行为。
1.2 多态存在的条件
继承关系:多态必须基于继承,子类继承父类,从而获得父类的属性和方法。
方法重写:子类重写父类的方法,以提供自己特有的实现。
父类引用指向子类对象:使用父类的引用变量来指向子类的实例,这样就可以通过这个引用调用子类重写后的方法。
1.3 多态的优点
可替换性:可以用子类对象替换父类对象,而不会影响程序的其他部分。
可扩充性:新增子类时,不会影响已存在的类的多态性和其他特性。
接口性:父类通过方法签名为子类提供共同接口,由子类完善或覆盖。
灵活性:在应用中体现灵活多样的操作,提高使用效率。
简化性:简化了代码编写和修改过程,尤其是处理大量对象时。
二、接口的概念与特性
2.1 接口的定义
接口是一种特殊的抽象类型,它只包含方法的签名,而没有方法的实现。接口使用interface关键字定义,接口中的方法默认是public abstract,成员变量默认是public static final。例如,定义一个Shape接口,其中包含draw方法,任何实现该接口的类都必须实现draw方法来绘制具体的图形。
2.2 接口的特点
不能实例化:接口不能直接创建对象,必须由实现接口的类来创建对象。
没有构造方法:接口中不存在构造方法。
方法必须是抽象的(JDK 1.7 及以前):接口中的方法必须由实现类来实现。在 JDK 1.8 及以后,接口可以包含默认方法和静态方法。
支持多实现:一个类可以实现多个接口,打破了 Java 单继承的限制。
2.3 接口的作用
定义规范:接口可以定义一组方法的规范,实现接口的类必须遵循这些规范,从而保证代码的一致性和可靠性。
实现多继承:通过实现多个接口,一个类可以拥有多个不同类型的行为,实现了类似多继承的效果。
提高代码的可维护性和扩展性:接口使得代码的依赖关系更加清晰,当需求发生变化时,只需要修改实现接口的类,而不会影响到其他使用接口的代码。
三、多态与接口的关系
3.1 接口实现多态
接口是实现多态的重要方式之一。通过接口,不同的类可以实现相同的方法,从而表现出不同的行为。例如,定义一个Payment接口,包含pay方法,然后有AlipayPayment和WeChatPayment类实现该接口,它们的pay方法实现不同的支付逻辑。在使用时,可以通过Payment接口的引用调用不同实现类的pay方法,实现多态。
3.2 多态与接口结合的优势
提高代码的灵活性和可扩展性:当需要添加新的支付方式时,只需要创建一个新的类实现Payment接口,而不需要修改现有的代码。
降低代码的耦合度:接口作为一种抽象层,使得不同的实现类之间相互独立,减少了代码之间的依赖关系。
四、多态与接口的使用场景
4.1 多态的使用场景
方法参数的通用性:在定义方法时,可以使用父类作为参数类型,这样该方法可以接受任何子类的对象,提高方法的通用性。
对象的动态绑定:根据不同的运行时条件,选择调用不同子类的方法,实现动态行为。
4.2 接口的使用场景
定义 API:接口常用于定义 API,提供一组方法的签名,让其他开发者根据这些签名来实现具体的功能。
实现插件化架构:通过接口,可以将系统的不同功能模块分离,实现插件化的开发,方便扩展和维护。
五、总结
多态和接口是 Java 中强大的特性,它们相互配合,为开发者提供了极大的便利。多态使得代码更加灵活和可扩展,接口则定义了规范和契约,实现了多继承的效果。在实际编程中,合理运用多态和接口,可以提高代码的质量、可维护性和可扩展性,使程序更加健壮和高效。无论是开发小型应用还是大型企业级项目,掌握多态与接口的使用都是至关重要的。