1、开发语言:Python3
2、数据库:MongoDB
3、开源框架:Chatterbot
4、依赖类库:
- pip3 install chatterbot
- pip3 install spacy
- # 需要手动编译安装 en_core_web_sm(使用2.1版本)
- pip3 install jieba
- pip3 install colorama
- pip3 install pymongo
About ChatterBot — ChatterBot 1.0.8 documentation 简单来说就是一个对话机器人框架
对输入的文本作预处理,比如去掉一些不必要的空格
1)最佳匹配适配器
使用函数将输入语句与已知语句进行比较。一旦找到与输入语句最接近的匹配,它就使用另一个函数来选择该语句的一个已知响应。
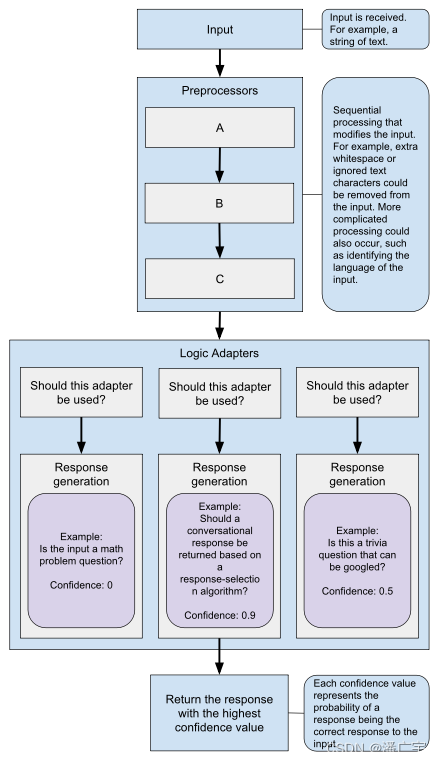
询问关于当前时间的问题的语句
User: What time is it?
Bot: The current time is 4:45PM.
检查给定的语句,以查看它是否包含可以计算的数学表达式。如果存在,则返回包含结果的响应。这个适配器能够处理字和数字运算符的任意组合。
User: What is four plus four?
Bot: (4 + 4) = 8
如果聊天机器人接收到的输入与为此适配器指定的输入文本匹配,则将返回指定的响应。
如果出现低置信度,则直接返回具体的文本
比如输入人工客服,返回特定的响应:
- >>> 人工客服
- Robot (1) :
- 您好,正在转接人工客服,请稍后。
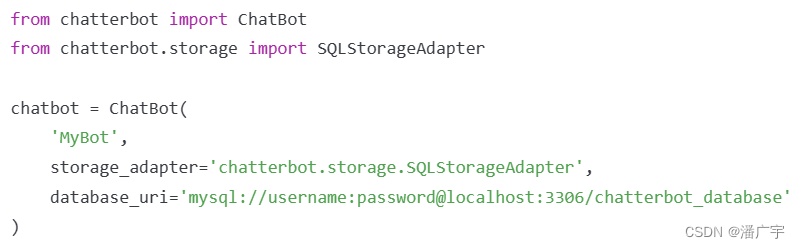
简单来说,存储适配器提供了一个接口,允许ChatterBot连接到不同的存储技术,不指定默认使用 SQLite 数据库存储聊天记录,会在执行程序的目录生成一个db.sqlite3文件
推荐是使用mongoDB作为存储适配器
还可以使用mysql:
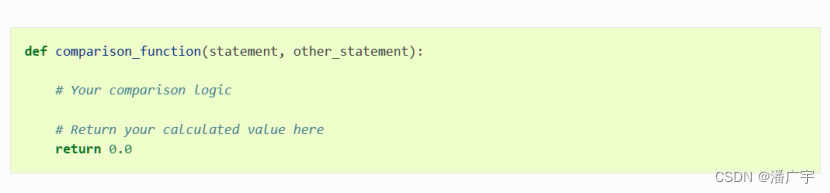
可以通过过滤器过滤一些非法的输入语句

可以自定义一个比较算法,最后返回一个0-1之间的得分值
在对话生成方面,ChatterBot 使用了一种基于深度学习的序列到序列模型来生成回答。具体来说,它使用了一种叫做 LSTM(长短时记忆)的神经网络模型,将对话历史和用户输入转化为一个序列,然后根据先前的对话历史来预测下一个可能的回复。
将问句表示成一个高维向量,因为一段自然语言文本可能包含很多不同的词汇,每个词汇都对应一个维度。
假设我们有以下两句话:
可以请问你多大了吗?
你今年几岁了?
我们已经将它们表示为以下向量:
v1 = [1, 1, 0, 0, 1, 0, 0, 1, 0]
v2 = [0, 1, 1, 1, 1, 0, 0, 1, 0]
可以通过如下公式计算这两个向量的余弦相似度:
cos_sim(v1, v2) = (v1 • v2) / (||v1|| * ||v2||)
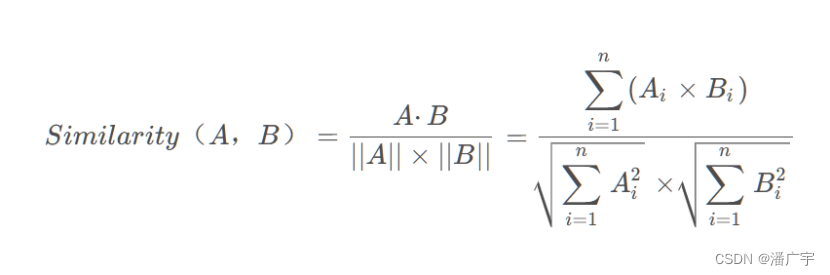



其中,“•”表示两个向量的点积,表示对应元素相乘之和。而“||v||”表示一个向量的模,即该向量的所有元素平方和的非负平方根。
按照上述公式计算得到两个向量的余弦相似度为 0.5,这说明这两句话在意义上比较相似。当用户输入一句与 v1 向量比较相似的话时,ChatterBot 可以将回答设置为“我的年龄是……”。
余弦相似度的取值范围是 [-1, 1],其中 1 表示两个向量完全相同,-1 表示两个向量方向完全相反,0 表示两个向量互相垂直。
1)准备语料库
第一行为Question,第二行为answer。它支持json,txt,yml各种格式文件,以txt为例子:
比如有以下的一段对话:
Q:我不知道如何安装游戏。
A:您可以在我们的网站上找到安装说明,或者尝试卸载并重新安装游戏。
Q:我忘记了我的游戏账号密码。
A:请尝试通过我们的密码恢复选项重置您的密码。
存为txt格式直接就是:
我不知道如何安装游戏。
您可以在我们的网站上找到安装说明,或者尝试卸载并重新安装游戏。
我忘记了我的游戏账号密码。
请尝试通过我们的密码恢复选项重置您的密码。
这里记录为 corpus.txt 待会用到
2)利用jieba分词工具进行分词
# -*- coding: utf-8 -*-
import jiebafile_path = "corpus.txt" # 将 your_file_path.txt 替换成您的文件路径
with open(file_path, "r", encoding="utf-8") as f:lines = f.readlines()new_lines = []
for line in lines:if line.strip(): # 判断是否为空行new_lines.append(line)text = ''.join(new_lines)word_list = jieba.cut(text) # 进行分词
result = " ".join(word_list) # 将分词结果合并为字符串,以空格隔开file_path = 'corpus_cut.txt' # 将 your_file_path.txt 替换成您的文件路径
with open(file_path, mode='a', encoding='utf-8') as f:# 写入数据f.write(result+'\n')官网文档并没有推荐使用jieba分词进行拟合度的优化,为什么要用jieba进行中文分词?
这也是我自己探索出来的,之前没用分词工具的时候,发现拟合度很差,后面猜测是框架的计算对中文不准确,对中文的分词效果很差,导致计算出来的词向量其实是误差很大的。中文没有像英文一样的明显的单词边界,因此需要使用专门的中文分词工具将中文文本分成有意义的词语,这样计算出来的词向量才是比较精准的。
Jieba 分词工具利用了统计算法和规则引擎的结合,通过分析中文文本中每个汉字与周围汉字的关系,来确定最可能的分词结果。这样可以大大提高分词的准确性,从而更好地反映出中文句子的含义。
3)训练数据
# -*- coding: utf-8 -*-
from chatterbot import ChatBot
from chatterbot.trainers import ListTrainer
import chatterbot.comparisons as comparisons
import chatterbot.response_selection as response_selection
import logginglogging.basicConfig(level=logging.INFO)chatbot = ChatBot("Ron", logic_adapters=[{'import_path': 'chatterbot.logic.BestMatch',"statement_comparison_function": comparisons.LevenshteinDistance,"response_selection_method": response_selection.get_first_response,'default_response': 'I am sorry, but I do not understand.','maximum_similarity_threshold': 0.90},{'import_path': 'chatterbot.logic.SpecificResponseAdapter','input_text': '人工客服','output_text': 'Ok, here is a link: http://chatterbot.rtfd.org'}],storage_adapter='chatterbot.storage.MongoDatabaseAdapter',database_uri='mongodb://127.0.0.1:xxxx/chatbot')# 打开并读取 TXT 文件内容
with open('corpus_cut.txt', 'r', encoding='utf-8') as file:conversation = file.readlines()# 创建训练器实例并迭代训练
trainer = ListTrainer(chatbot)
trainer.train(conversation)
ChatterBot 提供了多种存储适配器(Storage Adapter),可以将训练好的模型数据保存到不同的存储介质中,如文本文件、SQLite 数据库、MongoDB 数据库、Redis 队列等。其中,最常用的存储适配器是 JSON 文件和 SQLite 数据库。
如果你使用 SQLite 存储适配器,那么训练好的模型数据就会被保存在 SQLite 数据库文件中;如果你使用 JSON 存储适配器,那么训练好的模型数据就会被保存在 JSON 文件中。在每次启动机器人时,ChatterBot 会自动从指定的存储介质中加载模型数据。
4)通过命令行进行测试
注意要把输入的问句进行分词,然后丢给模型去匹配才能更精准
# -*- coding: utf-8 -*-
from chatterbot import ChatBot
import chatterbot.comparisons as comparisons
import chatterbot.response_selection as response_selectionimport jieba
import time
import colorama
from colorama import Fore,Style
import logginglogging.basicConfig(level=logging.INFO)colorama.init() # 初始化 colorama,必须先执行chatbot = ChatBot("Ron", logic_adapters=[{'import_path': 'chatterbot.logic.BestMatch',"statement_comparison_function": comparisons.LevenshteinDistance,"response_selection_method": response_selection.get_first_response,'default_response': '无法识别您的问题,可以联系人工客服,请输入"人工客服"四个字','maximum_similarity_threshold': 0.9},{'import_path': 'chatterbot.logic.SpecificResponseAdapter','input_text': '人工客服','output_text': '您好,正在转接人工客服,请稍后。'},{'import_path': 'chatterbot.logic.SpecificResponseAdapter','input_text': '你好','output_text': '你好,我是智能问答机器人,能问有什么可以帮到你?'}],storage_adapter='chatterbot.storage.MongoDatabaseAdapter',database_uri='mongodb://127.0.0.1:27017/chatbot',
)# 轮询对话
while True:try:# 等待用户输入user_input = input('>>> ')if user_input:if user_input != '人工客服':# 获取 chatbot 响应word_list = jieba.cut(user_input) # 进行分词result = " ".join(word_list) # 将分词结果合并为字符串,以空格隔开else:result = user_inputbot_response = chatbot.get_response(result)score = bot_response.confidenceresp = bot_response.textresp = resp.replace(" ", "")print(Style.BRIGHT + Fore.BLUE + "Robot " + "("+str(score)+ ") : "+ Fore.RESET+ Style.RESET_ALL)for i in range(len(resp)):print(Fore.YELLOW + resp[:i+1]+ Fore.RESET, end='\r')time.sleep(0.1)print() # 输出换行符以保证控制台输出完整except (KeyboardInterrupt, EOFError, SystemExit):break5) 启动mongoDB并查看相关的数据
use chatbot
show collections
db.statements.find()









![[干货]手把手教你写一个安卓app](https://img-blog.csdnimg.cn/20210715171459939.png)