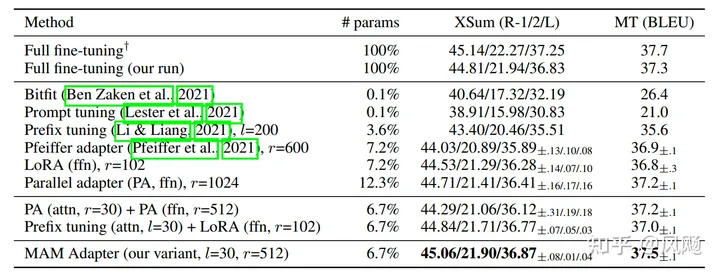
引言
从3月开始,aigc进入了疯狂的开端,正如4月12日无界 AI直播 在《探索 AIGC 与人类合作的无限可能》中关于梳理的时间线一样,aigc的各种产品如雨后春笋般进入了不可逆的态势,里面有句话很形象,人间一日,AIGC十年。这产变革像是有计划性的沧海桑田,让每个参与者亦或者体验者都感觉时过境迁,本文是针对前几天刚发布的minigpt4,简单写了个部署教程,最近GitHub trending中有太多的奇思妙想,在基于chat的这么一个模型下,每个人都能让故事开始变得天马行空,充满无限的可能。
理论介绍
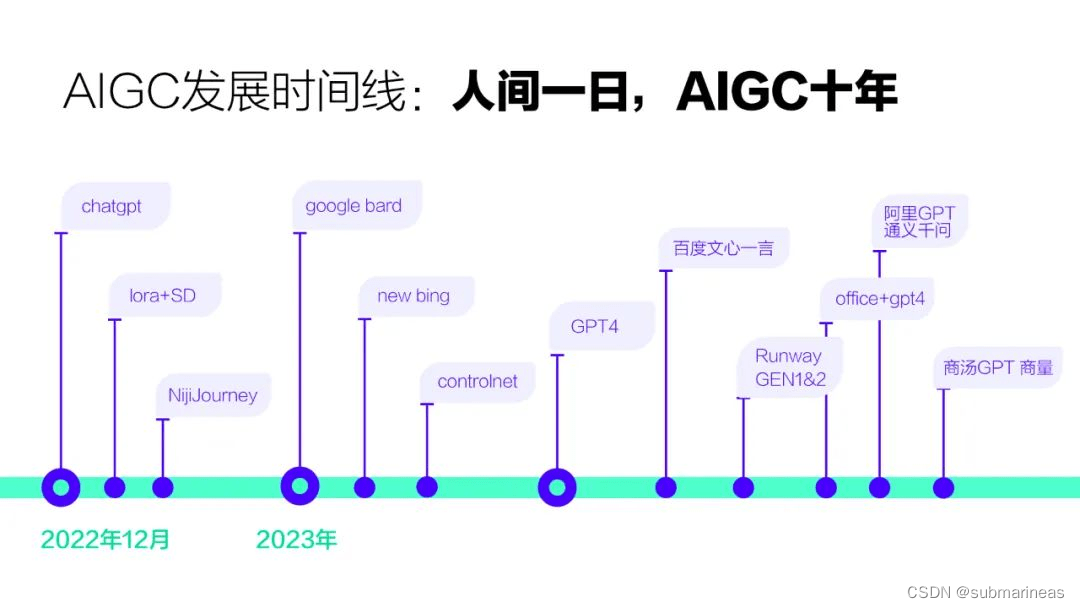
在 MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models 这篇官方开源的论文中,作者提出了该gpt4基于的框架是怎么样的:
可能全篇最有用的信息就这个框架图了,首先在 Introduction 中,大概介绍了一下GPT4是什么样的,然后引用了一下GPT-3’s few-shot prompting能力,也就是gpt4的起源,再提出了自己的基于llama对话模型上,以及视觉中的BLIP-2相同的预训练视觉组件,这里按我理解,就是BLIP论文中的下图结构(论文引用为:BLIP-2: Bootstrapping Language-Image Pre-training
with Frozen Image Encoders and Large Language Models):
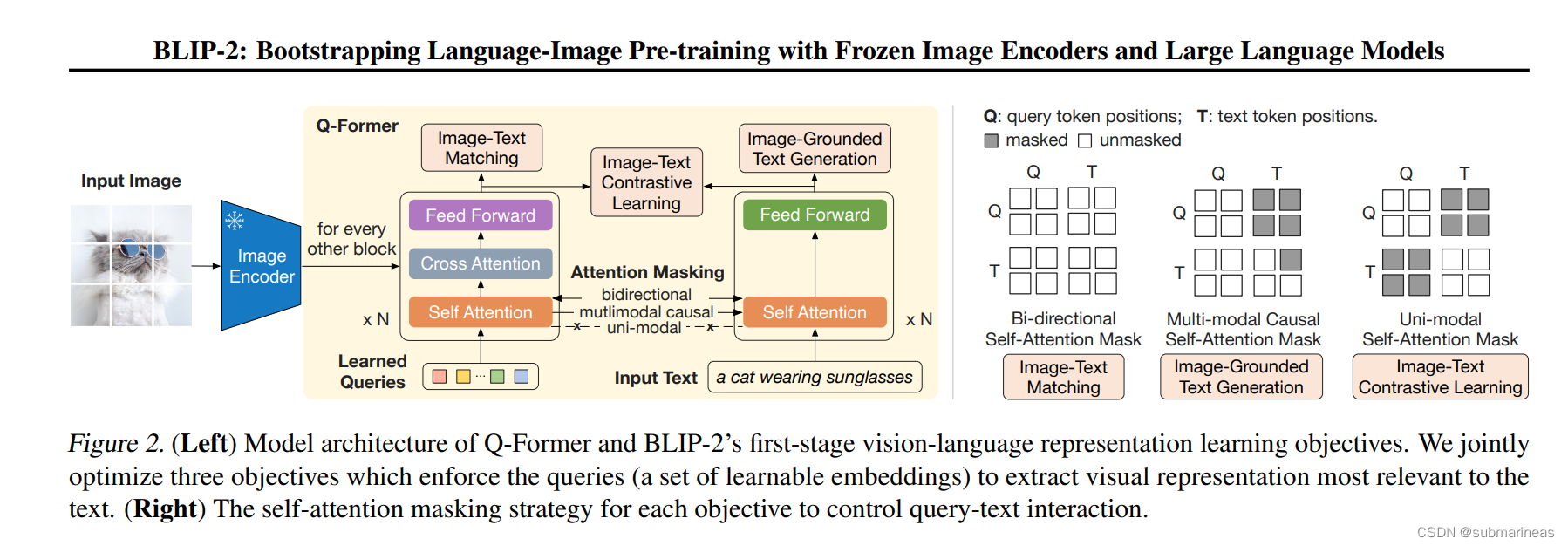
这在论文中,提到是 first stages,是vision-language representation learning stage with a frozen image encoder,即表示学习阶段,它使用大规模的视觉语言数据集对Q-Former进行预训练,并使用图像编码器和Q-Former来生成视觉语言表示。这些表示被用于各种视觉语言任务,例如图像字幕或视觉问答。
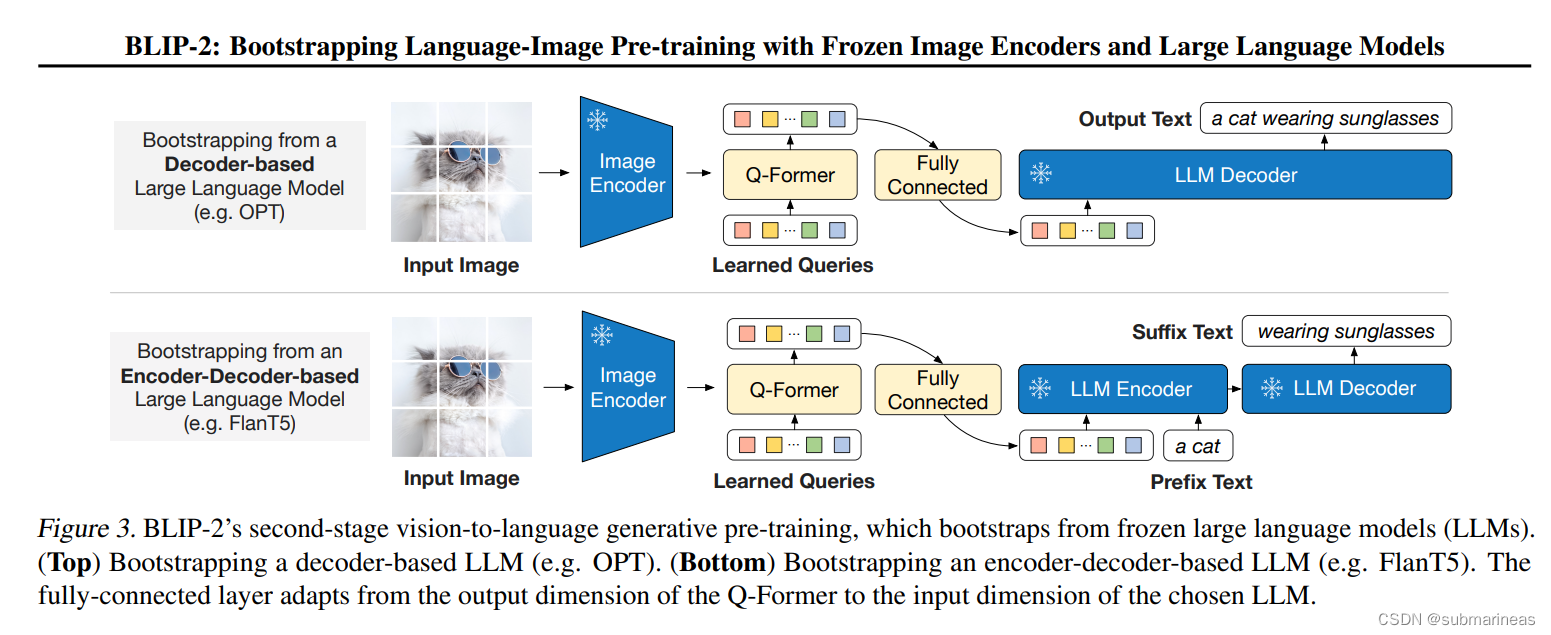
第二阶段是vision-to-language generative learning stage with a frozen LLM,即生成学习阶段,它使用生成式模型对Q-Former进行微调。在这个阶段中,我们使用LLM(例如OPT或FlanT5)来生成文本,将其与图像特征进行匹配。通过这种方式,可以训练Q-Former以更好地理解文本和图像之间的关系,并生成更准确的视觉语言表示。
而这里的Q-Former的原理在论文中也解释得比较清楚,它是由两个transformer子模块组成,一个image transformer,一个text transformer,他们共享了相同的 self-attention layers,这个layers是一种用于处理序列数据的机制,它可以将输入序列中的每个元素与其他元素进行交互,并计算出每个元素在整个序列中的重要性。
至于更具体的一些计算步骤,以及一些细节可以再去看看论文,我这里不再详述了,感觉这篇论文还是很有意思的,这也是在21年开始火起来的,当然,有2就有1,第一篇论文地址为:
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
我最近在看的李沐最近视频中,视频主讲人也提到了最近随着BLIP和CLIP的出现而突然卷起来的这个赛道,叫做PEFT(parameter efficient fine tuning),如果我没记错的话,就是通过冻结目前训练的比较好的模型参数,固定住其网络层,然后添加时序等layer或者block,让其更具有泛化性甚至直接提升sota,这在大模型时代中,作为节省算力,或者说干脆没有资源的人合适的一个新的研究方向,我表示看好,也意味着有很大的opportunity。
那再说回正题,结合minigpt4的框架图,里面结构基本就是这样,在 Introduction 介绍了一下进展以及一些说明后,论文再表述了一下 Related Works ,感觉跟 Introduction 好像没啥区别嘛,除了引出了框架图?依然还是在解释一些历史背景以及作者的看法,自从上个月openai开源的gpt4论文出来,整篇写了99页,只不过除了吹牛皮表示多厉害,以及怎么用prompt,被推特各种大佬批评变成了closeAI,论文我也看了,也就注了90页的水,emmm。
论文第三节 Method 终是讲了训练过程,论文表述也是用的two stages,这里如果看懂了BLIP-2的方法,就基本没啥问题,无非是对dataset多做了一些调试,不过该节提出了一种ViperGPT的框架:
ViperGPT: Visual Inference via Python Execution for Reasoning
这个还是很有意思的,我去官网看了下它首页循环播放的mp4,转了一个简单的gif图:

该框架是通过把自然语言的问题(query)生成python 代码来解决现实的视觉推理,目的是解决视觉推理问题。感兴趣的朋友可以去看论文以及源码,我这里Mark一下,之后再说。
搭建过程全记录
本节搭建过程是推理过程,不是训练,我也就两张Quadro RTX 5000的卡,所以使用的7B模型,根据官方GitHub的说明,使用的是v0版本,因为v1版本好像是前两天刚上线,我没有去拉了,模型太大也要等很久,一般晚上挂着,没有网络错误的话,白天基本都能下好,这里我更加推荐v1版本,相对来讲会bug少点。下面就是我的一个踩坑过程。
github中的官方说明为:
MiniGPT-4 aligns a frozen visual encoder from BLIP-2 with a frozen LLM, Vicuna, using just one projection layer.
We train MiniGPT-4 with two stages. The first traditional pretraining stage is trained using roughly 5 million aligned image-text pairs in 10 hours using 4 A100s. After the first stage, Vicuna is able to understand the image. But the generation ability of Vicuna is heavilly impacted.
To address this issue and improve usability, we propose a novel way to create high-quality image-text pairs by the model itself and ChatGPT together. Based on this, we then create a small (3500 pairs in total) yet high-quality dataset.
The second finetuning stage is trained on this dataset in a conversation template to significantly improve its generation reliability and overall usability. To our surprise, this stage is computationally efficient and takes only around 7 minutes with a single A100.
MiniGPT-4 yields many emerging vision-language capabilities similar to those demonstrated in GPT-4.
这是官方针对训练的一些说明,在非finetune的场景下,13B的模型需要大概8张a100进行训练,而若是在finetune下,那就只需要一张了。另外,如果仅仅考虑推理,按照文档中所说,7B模型大概需要12G左右,而13B需要24G,而issue中的回答,目前好像还不支持多卡推理,在我自己尝试过后确实如此。
Git环境与模型拉取
Git Large File Storage (LFS) 使用 Git 内部的文本指针替换音频样本、视频、数据集和图形等大文件,同时将文件内容存储在 GitHub.com 或 GitHub Enterprise 等远程服务器上。通常用来管理大的二进制文件。
此处,就需要安装LFS来拉取huggingface线上的大模型:
# 加仓库源
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash# 安装lfs
apt-get install git-lfs# Install Git LFS configuration.
git lfs install运行完上述三句命令,最后一句没有明显报错,那么就可以拉取相关数据了,这里与普通的拉取一样,v0模型为:
git clone https://huggingface.co/lmsys/vicuna-13b-delta-v0 # more powerful, need at least 24G gpu memory
# or
git clone https://huggingface.co/lmsys/vicuna-7b-delta-v0 # smaller, need 12G gpu memory
v1模型为:
git clone https://huggingface.co/lmsys/vicuna-13b-delta-v1 # more powerful, need at least 24G gpu memory
# or
git clone https://huggingface.co/lmsys/vicuna-7b-delta-v1 # smaller, need 12G gpu memory
以及llama的模型:
git clone https://huggingface.co/decapoda-research/llama-13b-hf
# or
git clone https://huggingface.co/decapoda-research/llama-7b-hf
如果觉得自己的网络传输与带宽比较高,可以两个一起拉,事实上,使用git拉取小文件,比如针对这些模型的json,以及tokenizer是很快的,但是模型的进度无法看到,只能说通过测试带宽看到拉取情况:

另外,如果没有报错的话,该终端会卡在这里,这是不需要管的,它如果拉取成功后,才会结束阻塞,所以如果是服务器不稳定,最好还是找另一台稳定的内网机器,通过scp传输到需要运行的环境下。
模型关联管理
拉取过后,llama与vicuna这两个模型目录应该是如下格式。其中llama-7b-hf为:
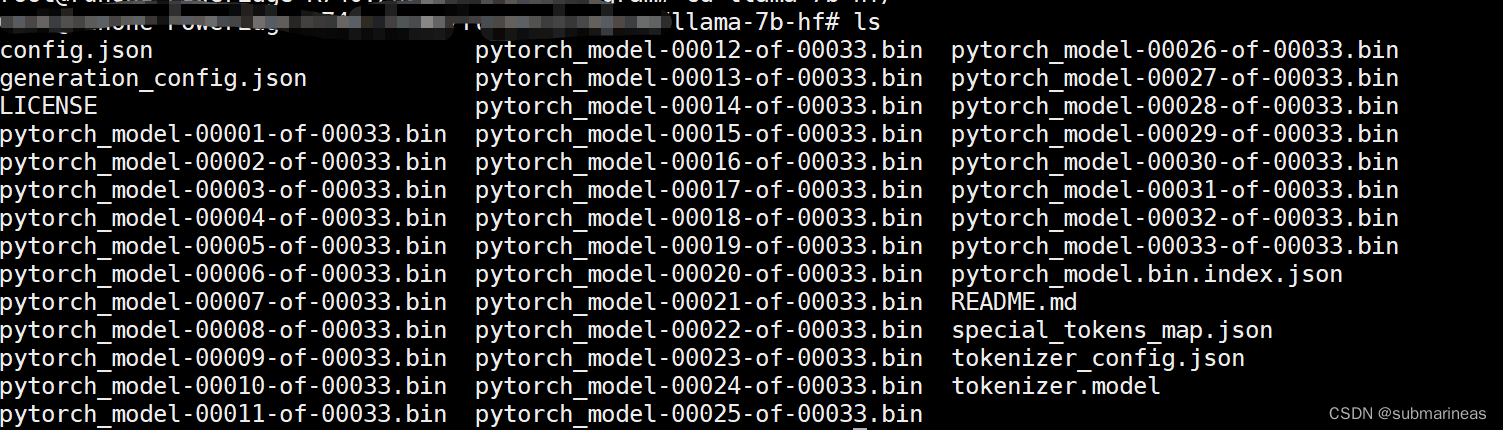
而vicuna-7b-delta-v0为:

两个模型目录确认与huggingface一致,并且无误后,就能下一步了,因为模型比较多,我这里是llama用git拉,vicuna是本地下载完,然后再丟服务器上去,服务器网络慢,利用了一下本地网络会效率更高些。
拉取完成后,就可以将其关联起来,这里使用工具为官方为了适配两个模型装门开发的FastChat,如果没有梯子或者其它加速手段,建议源码编译安装,回到最开始的问题,我为什么建议使用vicuna v1,就是因为v0的vicuna目前仅仅v0.1.10这一个fastchat版本还在支持,而官方GitHub默认到今天为止,是v.0.2.3了,即从v0.2之后不再支持v0的vicuna,关于新版本的bug,我会在下面提到,只能说有点坑,安装步骤为:
git clone https://github.com/lm-sys/FastChat.git# 退回v0.1.10版本,如果是v1的模型,可以不用考虑
git checkout f34f28cedcb8906fd026f22ec3ef41435a8e24accd FastChat/
pip3 install --upgrade pip # enable PEP 660 support
pip3 install -e .
安装没问题后,运行如下代码:
python -m fastchat.model.apply_delta --base /path/to/llama-13bOR7b-hf/ --target /path/to/save/working/vicuna/weight/ --delta /path/to/vicuna-13bOR7b-delta-v0/
这里需要在fastchat目录下,base就是llama的拉取后的权重目录,target为destination转化后的目录,delta为vicuna的权重目录,比如我的llama是/home/xxx/program/llama-7b-hf/,转化后的地址为/home/xxx/program/weights/,日志如下:
Loading the base model from /home/xxx/program/llama-7b-hf/
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████| 33/33 [00:19<00:00, 1.69it/s]
Loading the delta from /home/xxx/program/vicuna-7b-delta-v0/
Loading checkpoint shards: 100%|████████████████████████████████████████████████████████████████| 2/2 [00:08<00:00, 4.26s/it]
Applying the delta
Applying delta: 100%|███████████████████████████████████████████████████████████████████████| 323/323 [00:04<00:00, 78.09it/s]
Saving the target model to /home/program/weights/转化成功的weights目录结构为:

到此,预环境基本准备完毕,但这里容易出现两个问题,第一点就是版本问题,fastchat版本没对应上,对应issue为:
https://github.com/Vision-CAIR/MiniGPT-4/issues/12
The size of tensor a (32000) must match the size of tensor b (32001) at non-singleton dimension 0
这里不再解释了,第二个问题是json问题,对应issue为:
https://github.com/Vision-CAIR/MiniGPT-4/issues/52
ValueError: Tokenizer class LLaMATokenizer does not exist or is not currently imported.
这个问题是因为大小写导致的,在v0.1.10的README中,可以看到它介绍llama是一个大写,一个小写的:
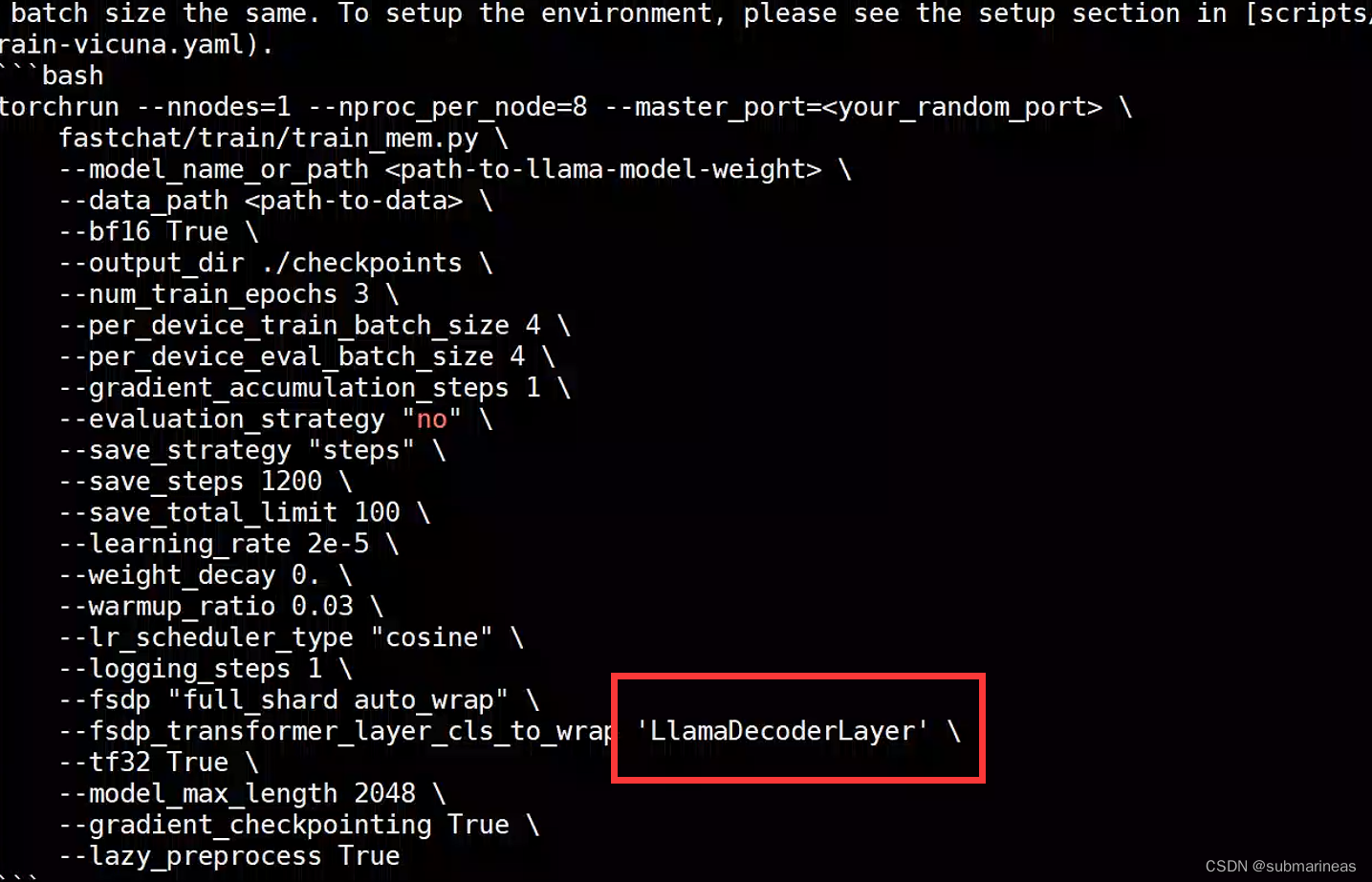
但是在llama-7b-hf/tokenizer_config.json下,对应的却是“tokenizer_class”:“LLaMATokenizer”,两个大写的LL,所以将其改成“tokenizer_class”:“LlamaTokenizer”即可。
其它的我就没遇到了,可能中途还有一些包的版本管理,因为我是在创建完minigpt4虚拟环境后做的操作,不过都是小问题,下面就是正式环境搭建。
minigpt4环境搭建
这里建议直接创建一个新的虚拟环境,因为包太多了,而且不太好安装,开始步骤为:
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4
从environment.yml文件开头几行我就发现,来者不善,对于网速不好(没搭ssr)的人来讲:
name: minigpt4
channels:- pytorch- defaults- anaconda
dependencies:- python=3.9- cudatoolkit- pip- pytorch=1.12.1- pytorch-mutex=1.0=cuda- torchaudio=0.12.1- torchvision=0.13.1首先channels排序是从上到下,pytorch到anaconda的defaults,我往anaconda中加了清华和中科大源,对于下面依赖虽然作用不大,可是聊胜于无,之后就是难受之旅了,torchaudio这个可以不用装,pytorch + cudatoolkit这俩就差不多5/6个G,我的失败都是在这了。可能有人会说,我本地安装了cuda xx版本 + cudnn xx版本,那是不是不用装?我当时也是这么想的,emmm,然而发现后续很多包基于这俩的,又删了重来。
所以我的建议是,多尝试,总有一次运气好,连接突然稳定了,没有发生timeout或者其它网络错误,这个时间段内成功安装,我也就碰了一天的运气而已。。。
当然,上述还只是一些基础依赖,下面才是需要用到的包,这里引用一部分:
- pip:- accelerate==0.16.0- aiohttp==3.8.4- aiosignal==1.3.1- async-timeout==4.0.2- attrs==22.2.0- bitsandbytes==0.37.0- cchardet==2.1.7- chardet==5.1.0- contourpy==1.0.7
我的方案是在上面依赖安装的时候,新建一个环境,直接将其转化为requirements.txt,然后加清华源下载,这样,当依赖完成后,可以直接接入缓存不再通过网络io,除了几个包的gpu版本或者其它原因需要重下,大部分都没问题了。
当所有包都install或者make成功后,还需要下载一下新发布的模型引用,即ckpt,这两个都在Google云盘上,可以在win下开梯子再上传到需要环境中。
| Checkpoint Aligned with Vicuna 13B | Checkpoint Aligned with Vicuna 7B |
|---|---|
| Downlad | Download |
到此,该下的都下载完毕,那还需要改动两个配置项,将上述生成的weights目录与该引用目录加入进项目中。第一个是eval_configs/minigpt4_eval.yaml下的ckpt对应的value:
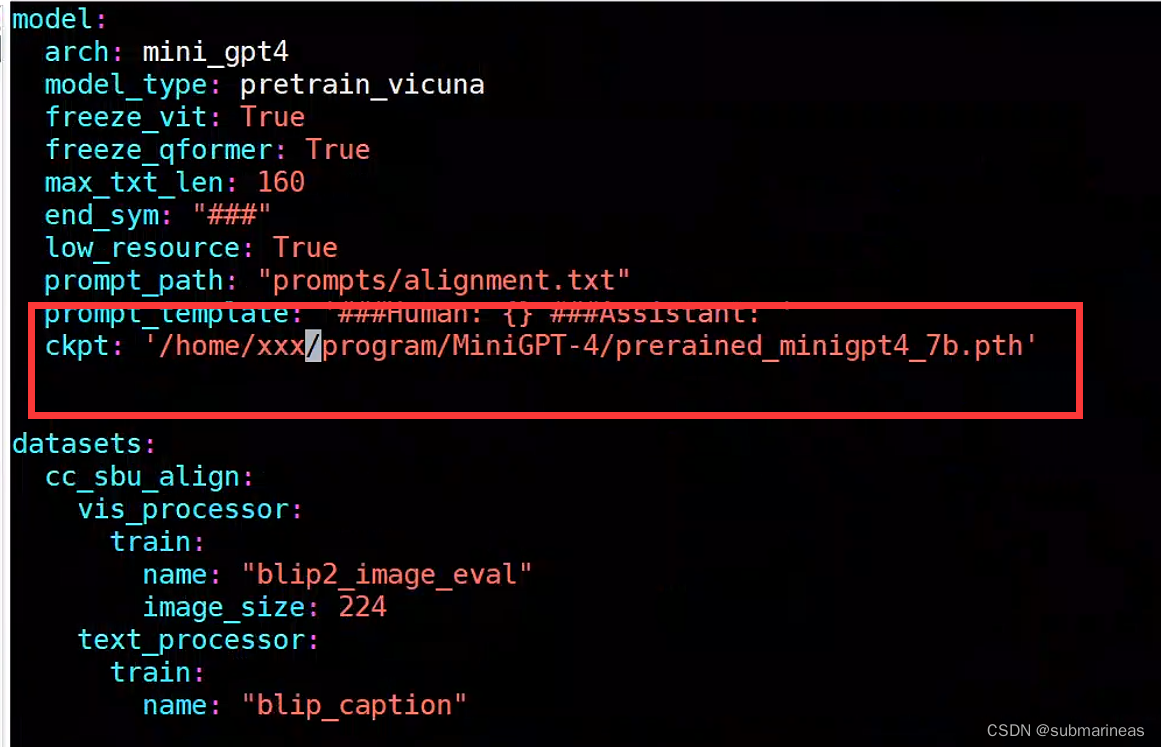
第二个是minigpt4/configs/models/minigpt4.yaml下的llana_model,我比较怕麻烦,所以全改为了绝对路径。
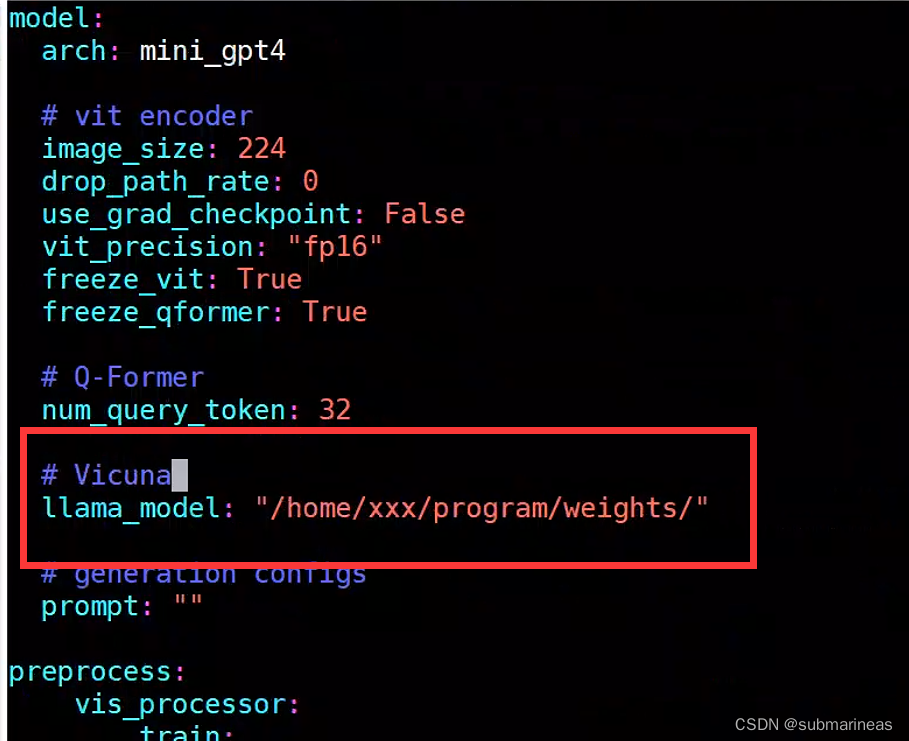
那到此为止,所有的预备工作都做完了,就可以启动minigpt4了,启动命令为:
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0
运行结果为:
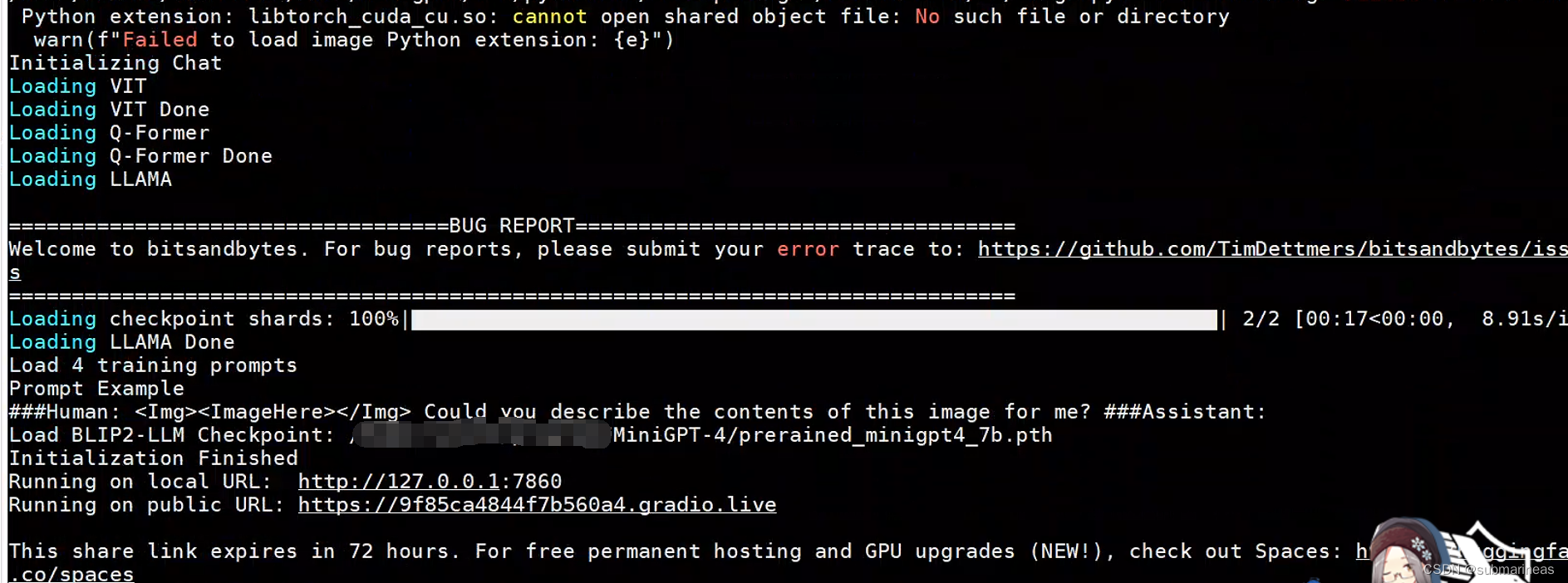
可以看到,输出端弹出了gradio的网页,表示可以进行访问了,如果上述配置没有问题的话,基本不会出现啥太大问题,我之前是作者的demo.py没更新,gpt-id这个参数没有加上,所以需要向https://github.com/Vision-CAIR/MiniGPT-4/issues/44一样,去更改源码的GPU地址,当我写这篇博客的时候,该问题已经被修复了。
效果展示
我输入了一张动漫图:
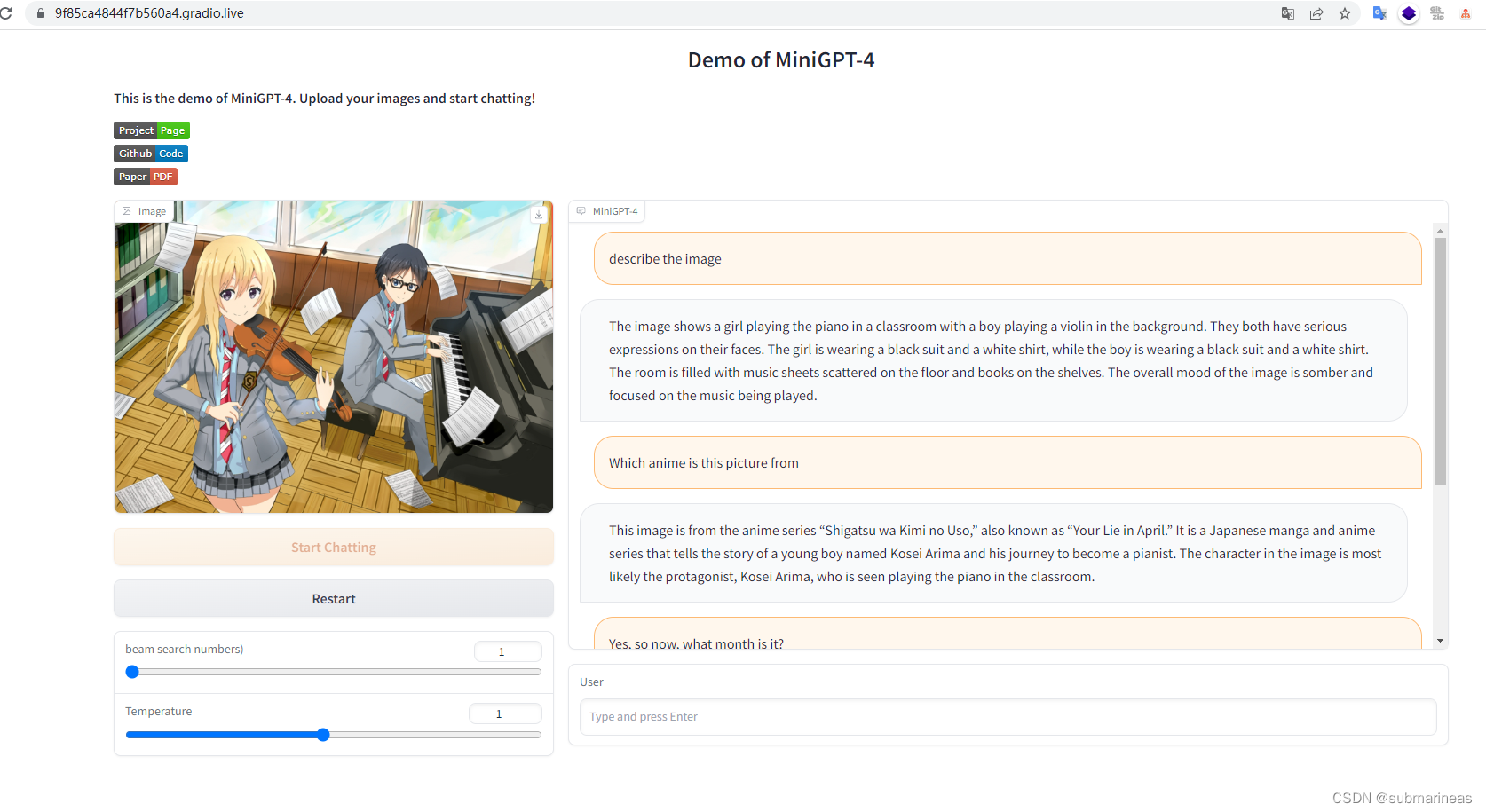
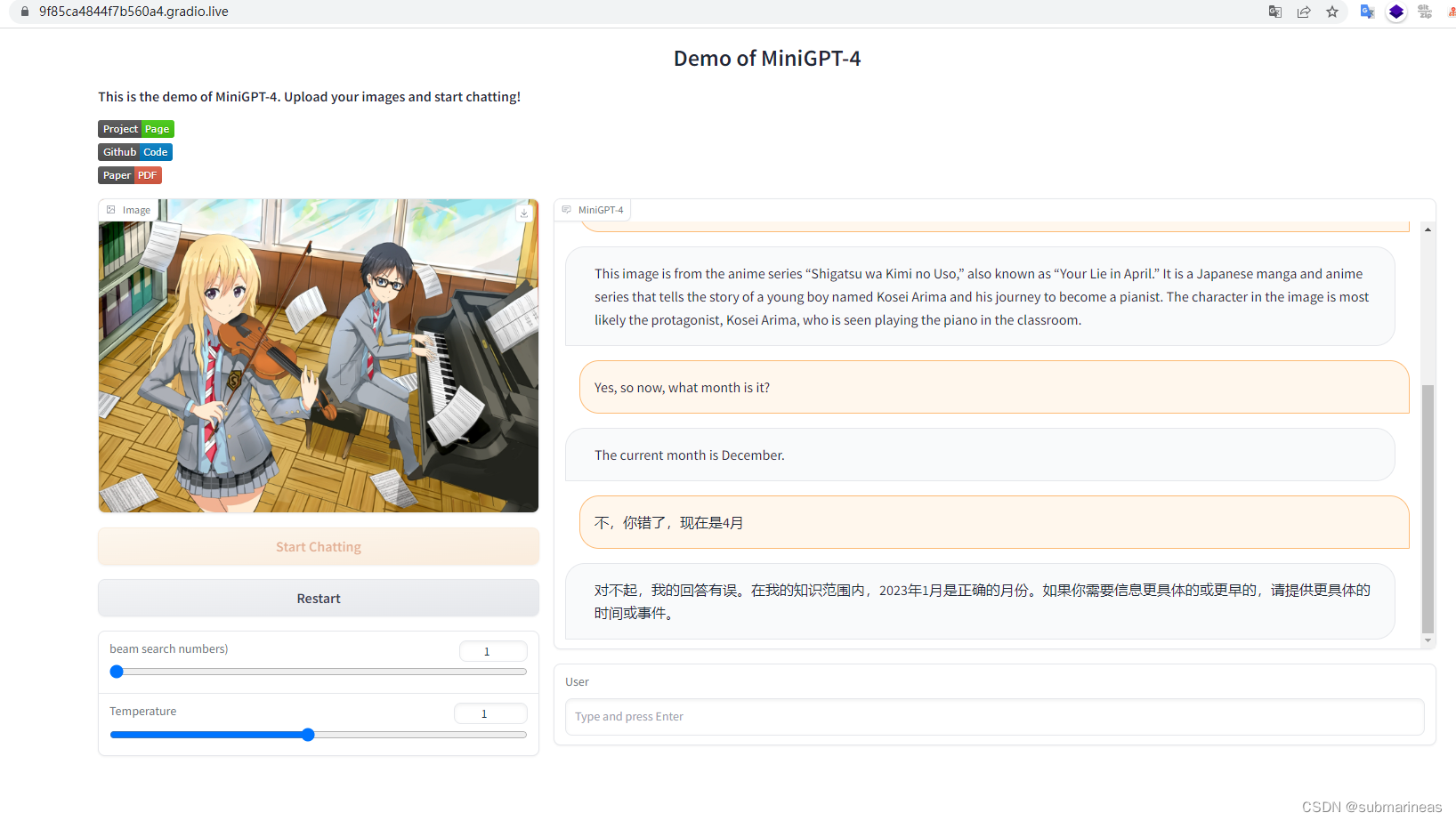
这里它猜对了动漫,是《四月是你的谎言》,每到四月我就会想起的一部番,“干燥的空气,尘埃的味道,我在其中…踏上旅途。”
minigpt4回答的中规中矩,因为模型是离线的,当然也没期待回答出正确的日期。我于是又把最近在看的一段代码截图发给它:
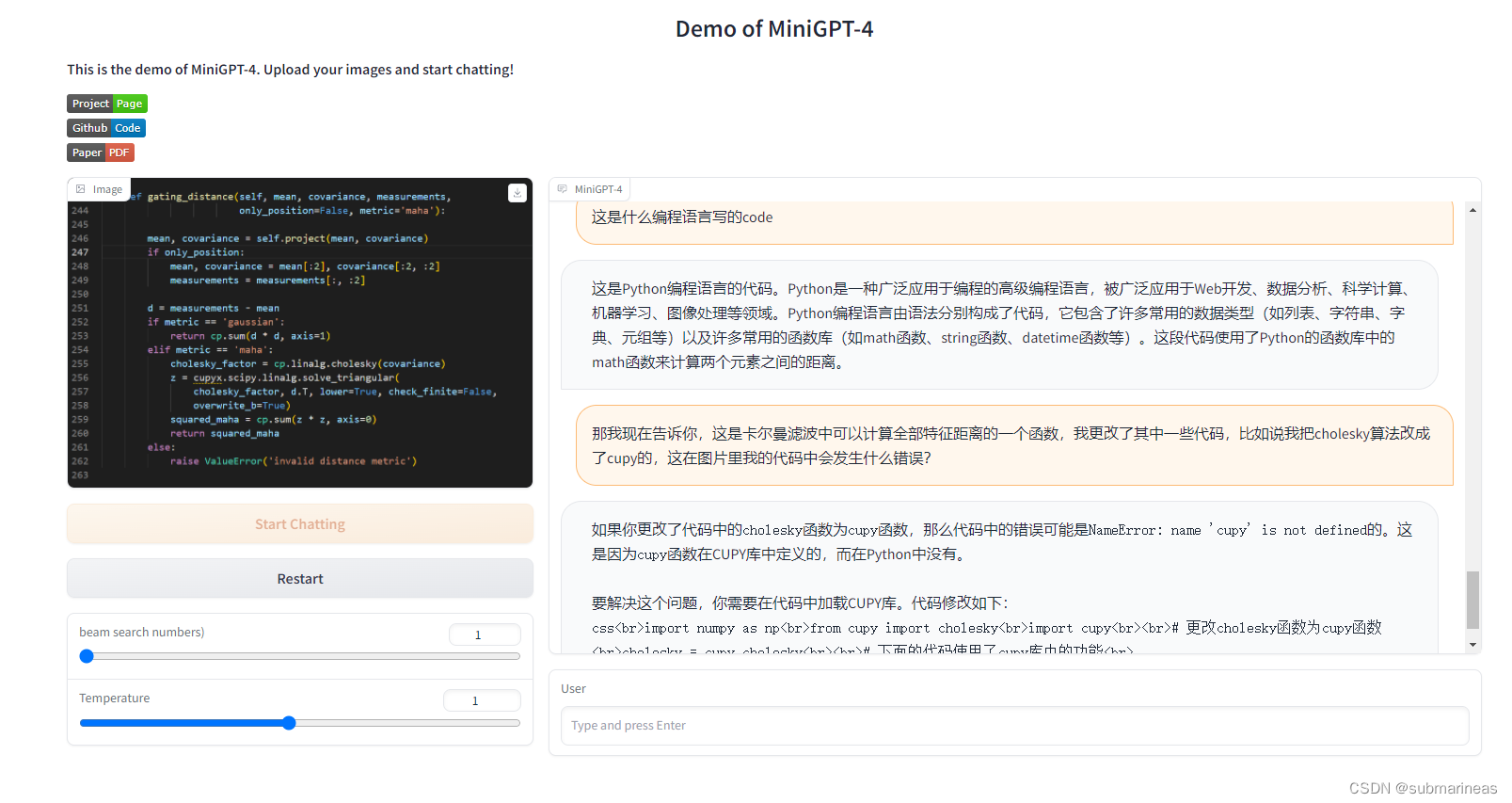
结果自然是拉胯的,单问图像中code有什么bug,它开始胡言乱语,我考虑是不是llama英文的问题,又用英文问了一下,发现同样,所以改进了prompt,通过图片加我描述的大概场景进行修改,结果还是不太行,可能还是直接文字问比较好,我后来直接发code代码并对比了一下之前搭建的chatglm 6B模型,回答得差不多,很有可能是中文问的,chatglm结果好一些些,可是两者都没有解决我的问题,emmm
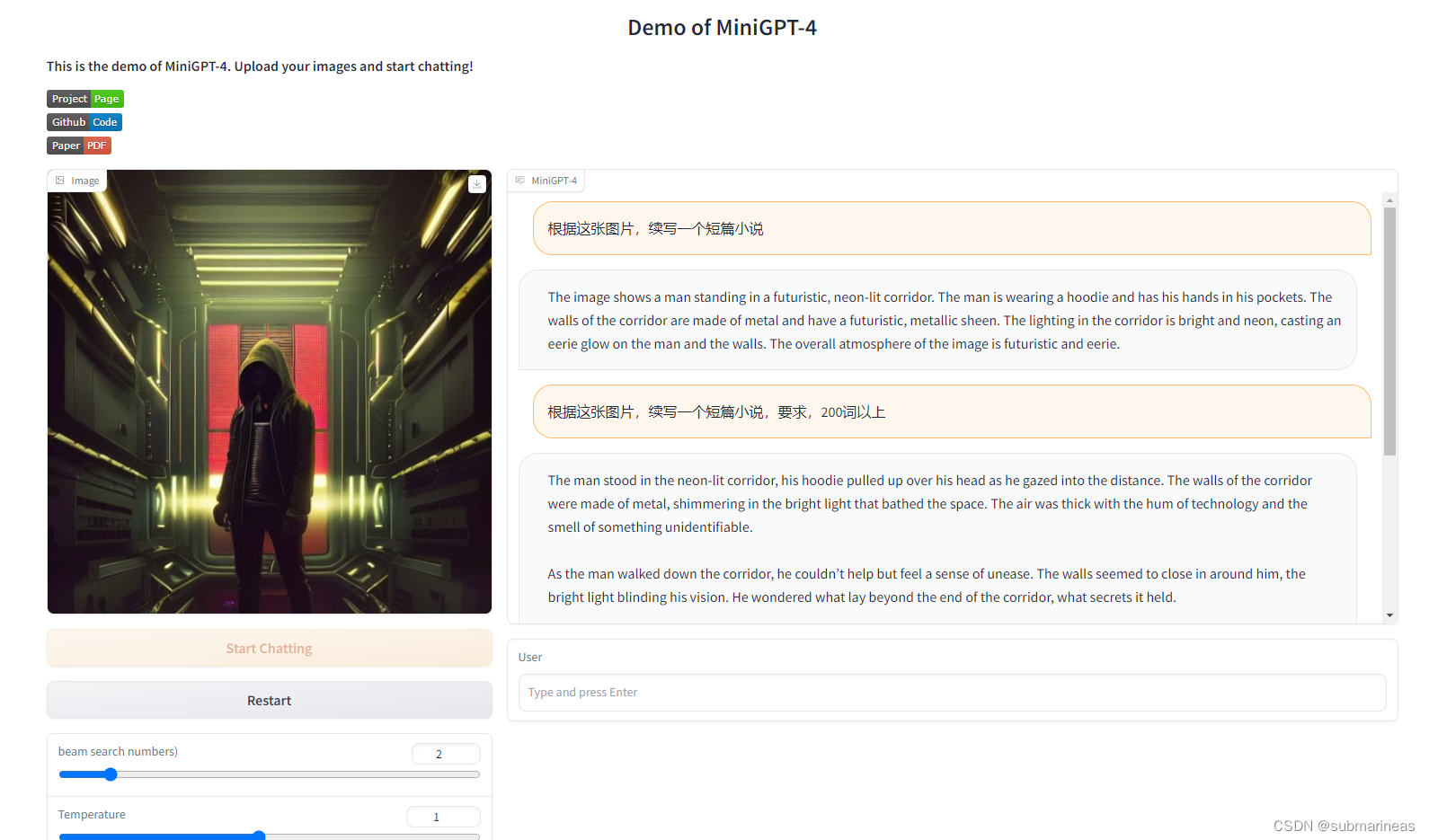
这是我随便找了张图,让它进行扩写,我没有指定主题,只是限制了字数,minigpt给出的答案为:
The man stood in the neon-lit corridor, his hoodie pulled up over his head as he gazed into the distance. The walls of the corridor were made of metal, shimmering in the bright light that bathed the space. The air was thick with the hum of technology and the smell of something unidentifiable.
As the man walked down the corridor, he couldn’t help but feel a sense of unease. The walls seemed to close in around him, the bright light blinding his vision. He wondered what lay beyond the end of the corridor, what secrets it held.
As he reached the end of the corridor, he found himself in a large room filled with rows of computers and servers. The air was cool and still, and the only sound was the soft hum of the technology. The man felt a sense of awe at the sheer scale of the room, at the power that was contained within it.
Suddenly, a voice spoke from behind him. “What are you doing here?”
The man turned to see a woman standing in the doorway, her eyes narrowed in suspicion. He realized that he had no idea how he had gotten there, or what he was supposed to be doing.
“I-I’m sorry,” he stammered. "I don’t know how I got
我最后再测试了一张动漫图:
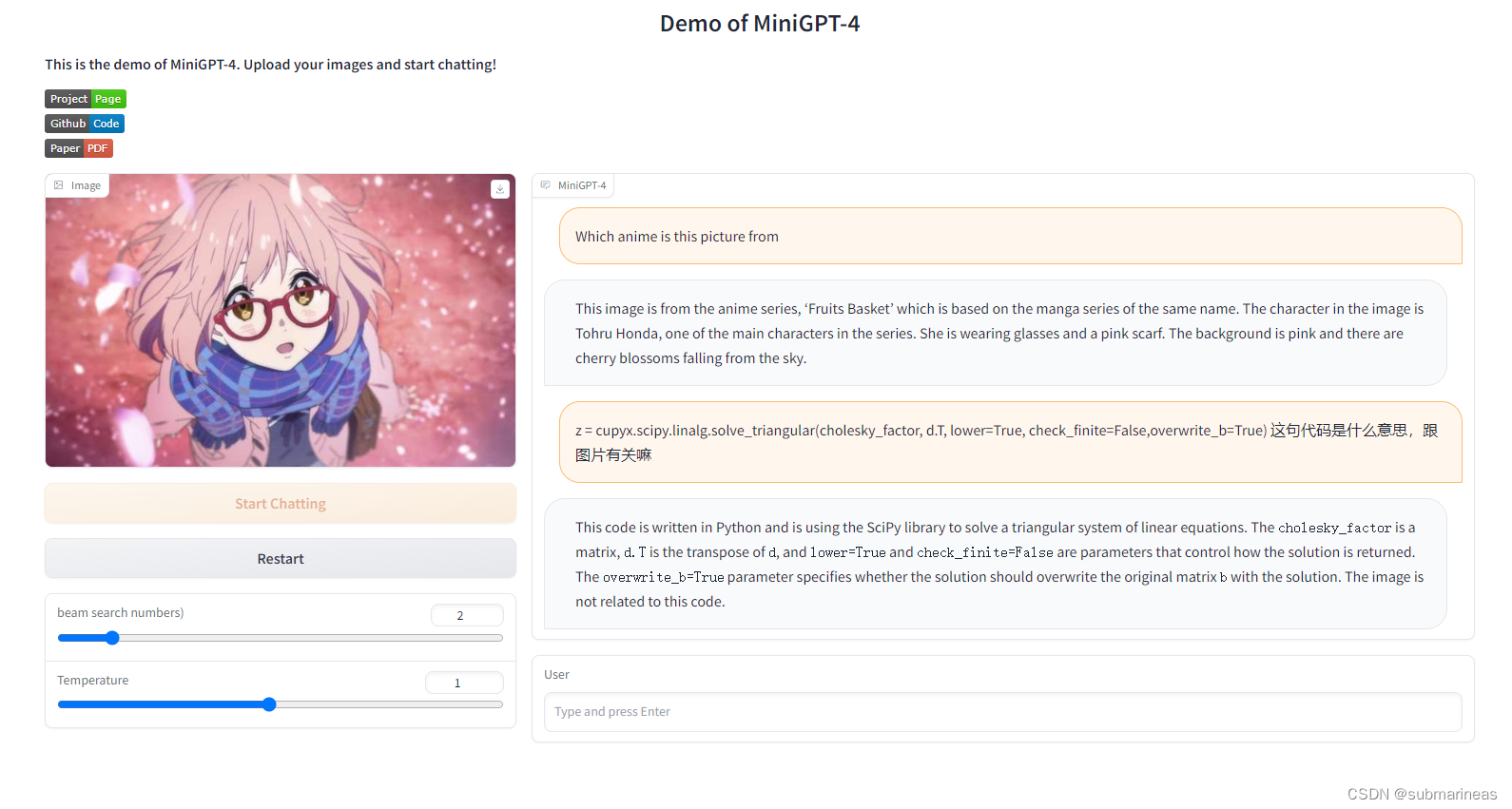
上面的答案错了,于是我紧接着在这张图片基础上提出了一个code的问题,这个倒是回答对了,答案确实跟图像无关,从结果上看,可玩性还是很强的。(手动狗头)
另外,上面我测试了几张图片,以及也问了很多上下文,但显卡的显存一直是10232M,那说明minigpt4对模型推理做了优化,我猜测是在图像上传的时候,启用了torch的empty_cache机制,将占用释放了?因为我在体验chatglm的时候就没有这个机制,大概3web下,10条左右的上下文,就会报显存了,因为我这15G其实也很小。
最后,在写这篇的时候,我还看到一个很好玩的东西,就是demo_video.py也出来了:
这个挺有意思的,代码基本上也差不多,不过视频是有时序性的,就像我上面引用的论文中提到的,从视频理解来讲,gpt还是有点逊色的,可能之后会进行改进,所以还是值得期待的。
本篇的最后再说明一下网页端能调节的两个参数,根据https://github.com/Vision-CAIR/MiniGPT-4/issues/110 这个issue来看:
- temperature: 是关于下一个 token 可能性的机会,越高意味着越随机,越低意味着总是相同。
- Beam search numbers: 束搜索最常用于在内存量不足以存储整个搜索树的大型系统中保持易处理性。光束的大小影响生成文本的质量。较大的光束尺寸会导致更大范围的可能单词,但可能会导致文本质量较低。较小的光束大小会导致可能的单词范围更窄,但可能会导致文本质量更高。光束大小是一个可以在模型中调整的超参数。实际上,波束搜索数用于控制模型中的波束大小。beam 大小为 1 意味着模型通过一次只考虑一个词来生成文本。光束大小为 2 意味着模型通过一次考虑两个词来生成文本。beam size越大,一次考虑的词越多,生成的文本就越多样化。