爬取了2019年LPL职业联赛的一些数据,通过大小龙,推塔数,以及队伍击杀数来预测队伍胜利,所以分为爬虫和knn算法俩块
首先是爬虫部分,根据网页结构,创造了一个大列表来储存所有要爬取的url,然后循环这个url爬取
我是写在另一个文件里,所以下面需要导入这个函数,若写在一个文件中则不需要
第一个lol_game_url.py文件:
def make_url():l = []for i in range(68, 100):#73页访问有问题,所以没有爬取if i != 73:s = ''s += 'https://lpl.qq.com/es/stats.shtml?bmid=42%d' % il.append(s)l1 = []for i in range(80):s1 = ''if i < 10:s1 += 'https://lpl.qq.com/es/stats.shtml?bmid=430%d' % ielse:s1 += 'https://lpl.qq.com/es/stats.shtml?bmid=43%d' % il1.append(s1)l2 = l + l1return l2
第二个lol_game_detail.py文件:
#导入相应的模块
import sqlite3
import time
from selenium import webdriver
from lol_game_url import make_url
#获取列表,连接数据库,并循序url列表访问页面
lol_url_list=make_url()
browser=webdriver.Firefox()
# conn=sqlite3.connect(r'D:\BaiduNetdiskDownload\navicat12\navicat\database\spider.db')
# c=conn.cursor()
for i in lol_url_list:browser.get(i)time.sleep(2)#俩个战队名字team1=browser.find_element_by_css_selector('span#teamA_name').textteam2=browser.find_element_by_css_selector('span#teamB_name').text#俩个战队战斗场数,循环爬取每一场数据game_nums = browser.find_elements_by_css_selector('ul#smatch_bar>li')play_group='%svs%s'%(team1,team2)for game_num in game_nums:num = game_num.find_element_by_css_selector('a')game_num1=num.textif num:num.click()time.sleep(1)#战队1和战队2名称team11 = browser.find_element_by_css_selector('p#teama-name').textteam22 = browser.find_element_by_css_selector('p#teamb-name').text#大龙team1_big_dragon = browser.find_element_by_css_selector('span#game-b-dragon-num-left').textteam2_big_dragon = browser.find_element_by_css_selector('span#game-b-dragon-num-right').text#小龙team1_small_dragon = browser.find_element_by_css_selector('span#game-s-dragon-num-left').textteam2_small_dragon = browser.find_element_by_css_selector('span#game-s-dragon-num-right').text#推塔数team1_tower_num = browser.find_element_by_css_selector('span#game-tower-num-left').textteam2_tower_num = browser.find_element_by_css_selector('span#game-tower-num-right').text#总经济team1_gold_num = browser.find_element_by_css_selector('span#game-gold-total-left').textteam2_gold_num = browser.find_element_by_css_selector('span#game-gold-total-right').text#击杀team1_kill=browser.find_element_by_css_selector('p#game-kda-k-total-num-left').textteam2_kill=browser.find_element_by_css_selector('p#game-kda-k-total-num-right').text#战队成员team1_members=[]for i in range(1,6):l=''l+='nr-game-player-name-left-%d'%imember=browser.find_element_by_css_selector('p#%s'%l).textteam1_members.append(member)team1_member=','.join(team1_members)team2_members = []for i in range(1, 6):l = ''l += 'nr-game-player-name-right-%d' % imember = browser.find_element_by_css_selector('p#%s' % l).textteam2_members.append(member)team2_member = ','.join(team2_members)print(play_group)print(game_num1)print('第一个战队', team11)print('大龙数量', team1_big_dragon)print('小龙数量', team1_small_dragon)print('推塔数', team1_tower_num)print('经济数量', team1_gold_num)print('%s队员%s'%(team11,team1_member))print('击杀数',team1_kill)print('第二个战队', team22)print('大龙数量', team2_big_dragon)print('小龙数量', team2_small_dragon)print('推塔数', team2_tower_num)print('经济数量', team2_gold_num)print('%s队员%s' % (team22, team2_member))print('击杀数',team2_kill)print('*' * 100)#数据库添加字段并存储sql="""insert into lpl_match(play_group,game_num,team11,team1_members,team1_big_dragon,team1_small_dragon,team1_tower_num,team1_gold_num,team1_kill,team22,team2_members,team2_big_dragon,team2_small_dragon,team2_tower_num,team2_gold_num,team2_kill)values(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)"""# params=(play_group,game_num1,team11,team1_member,team1_big_dragon,team1_small_dragon,# team1_tower_num,team1_gold_num,team1_kill,team22,team2_member,team2_big_dragon,team2_small_dragon,# team2_tower_num,team2_gold_num,team2_kill)# c.execute(sql,params)# conn.commit()
第三个lol_machinelearning_predict.py中:
#导入相应模块
import sqlite3
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier#连接数据库并读取
conn=sqlite3.connect(r'D:\BaiduNetdiskDownload\navicat12\navicat\database\spider.db')
sql="""select * from lpl_match"""
lol=pd.read_sql(sql,conn)def knn_sklearn():#我们有的数据训练集lol_content=lol.loc[:,['team1_big_dragon','team1_big_dragon','team1_tower_num','team1_kill','team2_big_dragon','team2_small_dragon','team2_tower_num','team2_kill']]#这个是我手动标记的爬取时忘了设置(也不多,就200多条。。。),哪个战队胜利,1是战队1胜,2是战队2胜lol_victory=lol['victory']#分为训练集和目标集,test_size表示以多大比例来分x_train,x_test,y_train,y_test = train_test_split(lol_content,lol_victory,test_size=0.25)#n_neighbors为k值knn = KNeighborsClassifier(n_neighbors=5)knn.fit(x_train,y_train)l=knn.predict_proba(np.array([[0,3,4,15,1,1,9,22]]))#TOP VS IG ,IG赢#可以转换为列表形式l1=l.tolist()[0]print(l1)if l1[0] > l1[1]:print('team1胜利')else:print('team2胜利')
knn_sklearn()第一个lol_game_url.py文件结果展示(截取部分):
 第二个lol_game_detail.py文件结果展示(截取部分):
第二个lol_game_detail.py文件结果展示(截取部分):

第三个lol_machinelearning_predict.py文件结果展示(截取部分):

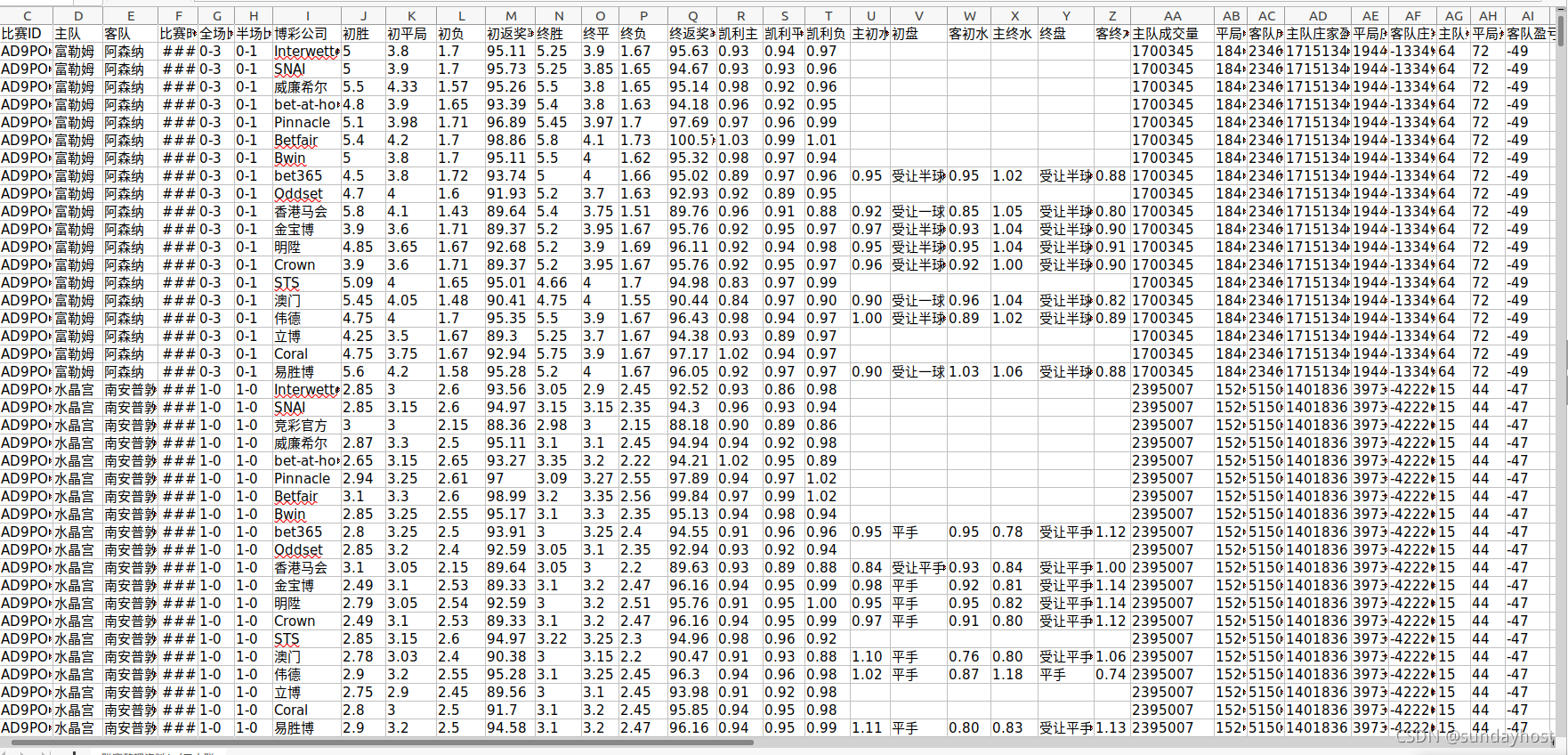
数据库展示(截取部分):

选取了第一个数据来预测,结果是正确的的,因为上面选取特征都会影响经济,所以就没有把经济选进来。对knn算法的理解就是计算你当前数据的特征值和已知数据类型的数据的特征值距离,然后按照大小排序选取,选取几个就是几nn。