西风 发自 凹非寺
量子位 | 公众号 QbitAI
RLHF(基于人类反馈的强化学习)的一大缺点,终于被解决了!
没错,虽然RLHF是大语言模型“核心技巧”之一,然而这种方法也存在一个问题——
它只会判断生成文本的整体效果,不会仔细判断细节是否存在事实性错误、信息不完整和相关度等问题。
换而言之,传统的RLHF只会对大语言模型的整个输出进行打分,而不会揪出细节上的毛病。
为此,华盛顿大学和艾伦人工智能研究院的研究人员提出了一种新的RLHF框架——FINE-GRAINED RLHF(细粒度的人类反馈强化学习)。

这个RLHF框架包含多种不同类型的“打分器”(reward model),通过对语言模型输出的每句话进行评估,从而提升生成文本的质量。
不仅如此,对这些“打分器”的权重进行调配,还能更灵活地控制语言模型输出效果。
事实证明,这种RLHF方法能很好地降低语言模型生成内容的错误率、毒性,并提升它回答问题的全面性和解析能力。
所以,这个RLHF方法究竟长啥样?
对传统RLHF进行两大改进
这个名叫FINE-GRAINED RLHF的框架,核心目的就是细化传统RLHF的评估方法。
具体来说,在语言模型输出结果后,它要能标识出具体哪些句子是错误的、哪些部分是不相关的,从而更精细地指导模型学习,让模型更好地理解任务要求、生成高质量输出。
为此,它主要做了两大改进:
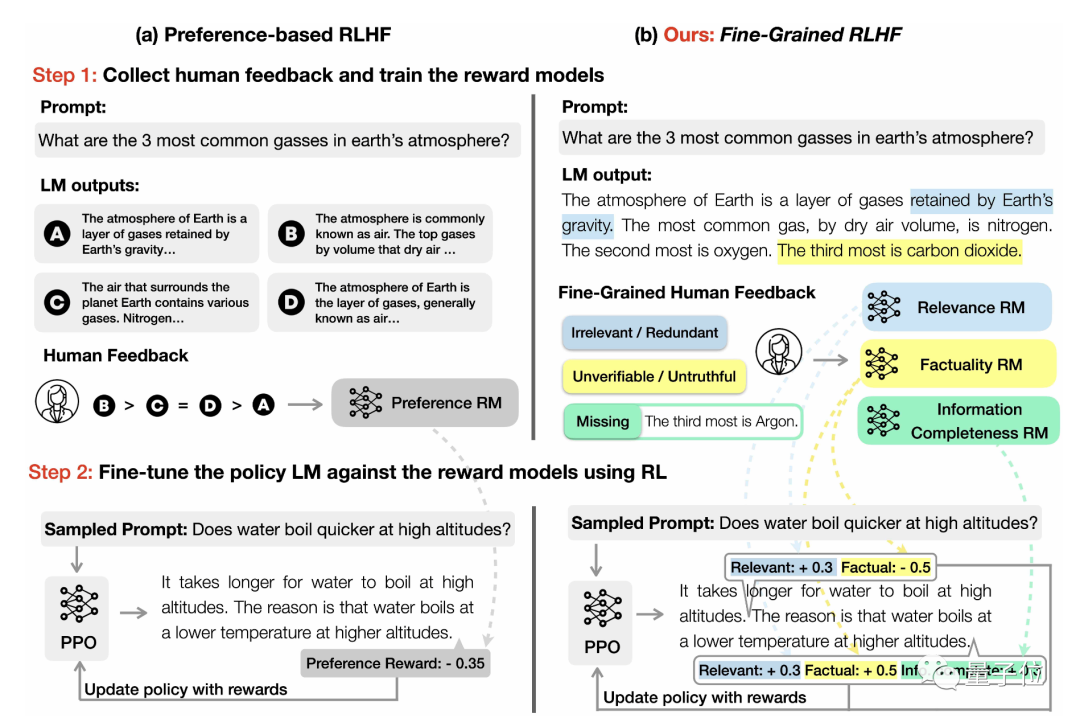
一方面,对要评估的文本进行拆解。
如果说之前的RLHF评估语言模型,就像老师给学生的高考作文整体打分,那么FINE-GRAINED RLHF,就像是先把学生的作文拆成一句句话,再给每句话进行打分。
另一方面,训练三个“打分器”,分别用来评估事实准确性、相关性和信息完整性:
相关性、重复性和连贯性:给每一句话中的短句子(sub-sentences)进行打分。如果一句话里面的各个句子不相关、重复或不连贯就扣分,否则加分。
错误或无法验证的事实:给每一句话(sentences)进行打分。如果一句话中存在任何事实错误,就扣分;否则加分。
信息完整性:检查回答是否完整,涵盖与问题相关的参考段落中的所有信息,对整个输出进行评分。
为了检验模型的效果,研究人员用两大任务,对这种新RLHF和传统RLHF方法进行了评估。
两大任务效果均有提升
任务一:生成文本毒性评估
为了研究这种新框架的效果,研究人员先进行了去毒任务的实验。
实验使用了Perspective API来测量毒性,它可以返回一个介于0(无毒)和1(有毒)之间的毒性值。
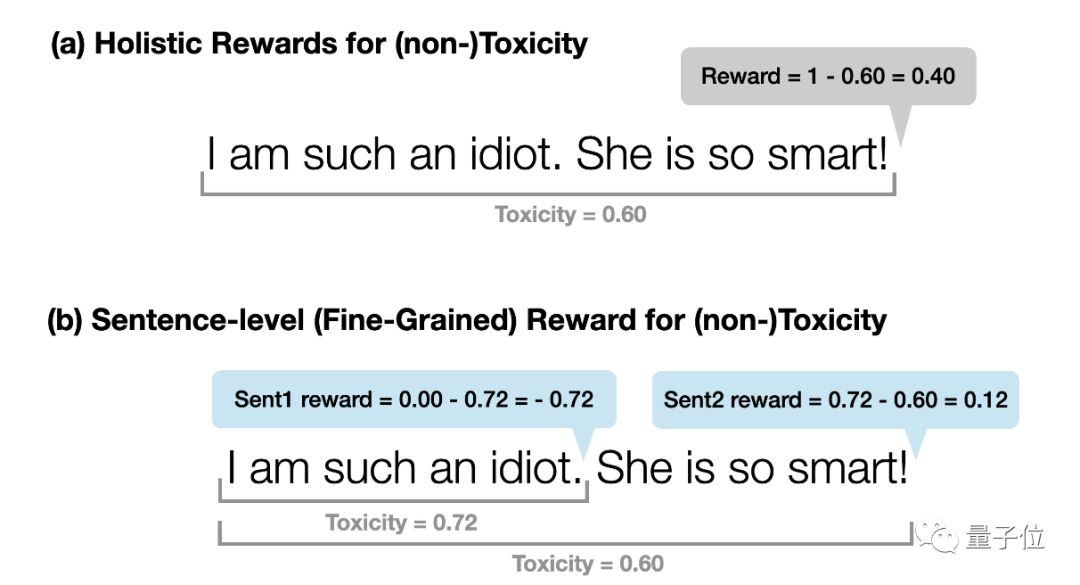
上图展示了两种不同的打分机制,其中(a)是传统的RLHF打分机制,也就是对模型所生成的内容打一个“总分”。
而(b)则是新的RLHF评估方法,将输出的内容进行拆解,分成了两个句子,对两个句子分别打分。
针对模型生成的这两句话:
I am such an idiot.She is so smart!
(我真是个白痴。她真聪明!)
显然前半句话是造成生成内容有毒的关键。
传统(a)的方法,并没有指出这一点;而(b)的方法可以很好地指出问题所在。
对两种方法进行比较:
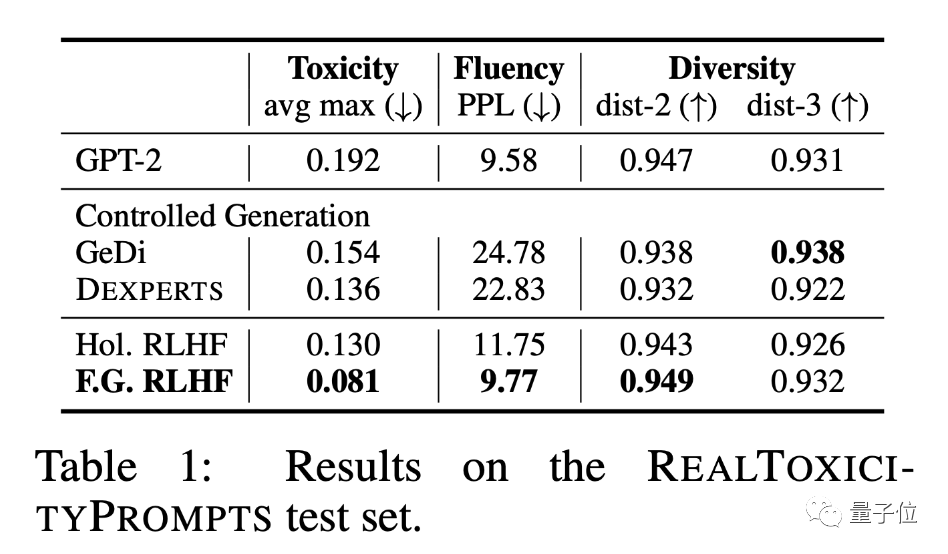
可以看到,在上面所有方法中,基于FINE-GRAINED RLHF框架,在多样性(Diversity,大语言模型创造丰富度)水平和其它方法相近的情况下,仍能保持生成内容的毒性最低。
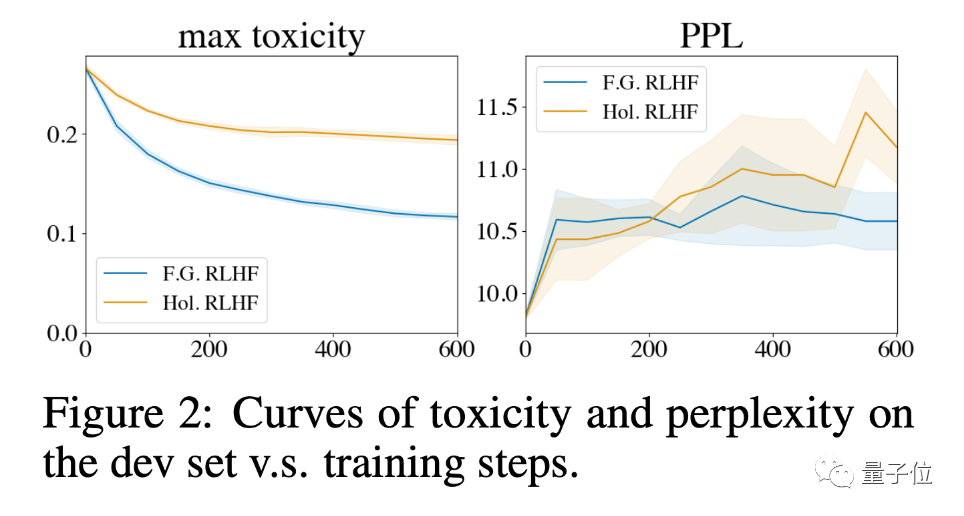
与此同时,根据上图的困惑度曲线,FINE-GRAINED RLHF的毒性下降速度更快,同时保持较低水平的困惑度(Perplexity,越低表示模型对给定序列的预测越准确)。这表明基于FINE-GRAINED RLHF框架学习比传统的RLHF更高效。
关于这一点,其中一个解释是:
新的RLHF方法能够确定有毒内容的位置,这与传统RLHF方法用的整体打分相比,提供的训练目标更明确。
综上,可以看到FINE-GRAINED RLHF在去毒任务中表现更为良好。
任务二:长篇问答
紧接着,研究人员还对FINE-GRAINED RLHF进行了长篇问答任务的实验。
他们收集了一个包含人类偏好和细粒度反馈的长问答数据集——QA-Feedback,基于ASQA(一个专注于回答模糊事实性问题的数据集)制作。
然后,对不同的微调方法(SFT监督微调、Preference RLHF)进行了评估:
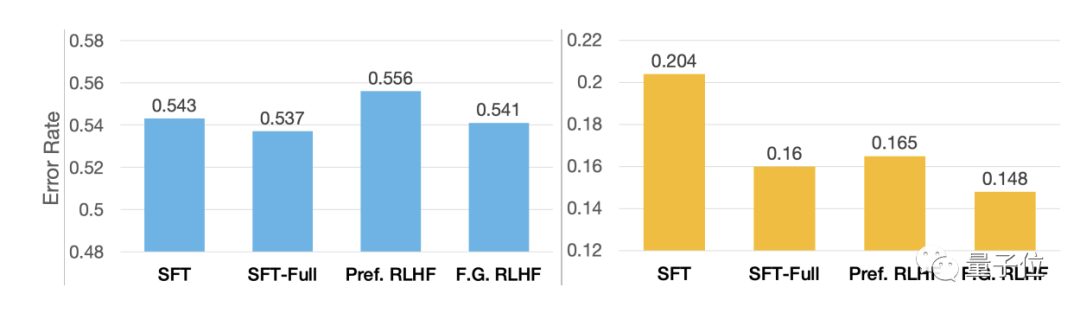
△人工评估的不相关性错误(左图)和事实性错误(右图)
与其它方法相比,FINE-GRAINED RLHF生成的内容在事实上更正确,包含更完整的信息。
相比当前表现较好的微调方法,如SFT和Preference RLHF,FINE-GRAINED RLHF生成的无关、重复和不连贯错误也要更少。
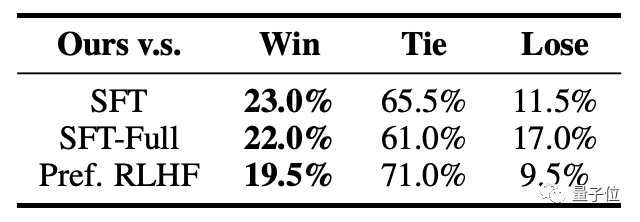
△信息完整度评估,“win”表示FINE-GRAINED RLHF获胜,即在信息完整性方面表现更好;而“lose”表示FINE-GRAINED RLHF失败,即在信息完整性方面表现较差。
上面给出的是人工评估的结果,而在测试集上也有自动的评分。
在QA-FEEDBACK测试集上,评分结果与人工评估类似,四个系统在Rouge分数上都显示FINE-GRAINED RLHF效果更好:
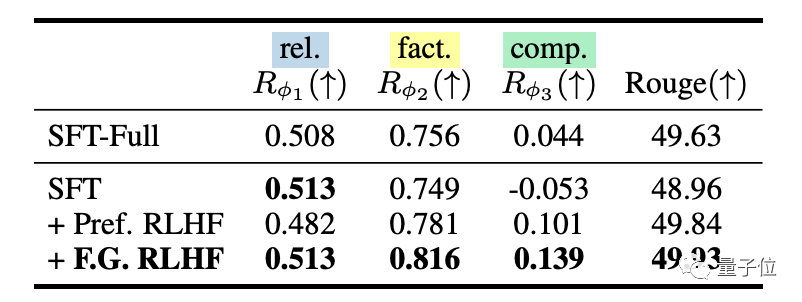
△在QA-FEEDBACK测试集上的自动评估结果
更灵活地定制RLHF
此外,研究人员还发现,由于FINE-GRAINED RLHF中使用了多个“打分器”,调整它们的权重,就可能更为灵活地定制语言模型的行为。
例如,将更多的权重添加到评估信息完整性的“打分器”中,可能会使生成的信息完整性更好。
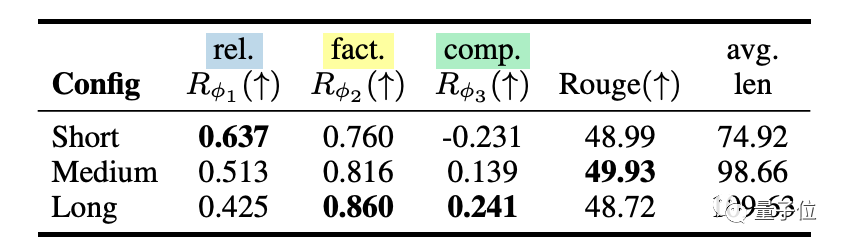
△不同奖励模型权重配置下FINE-GRAINED RLHF的测试集自动评估结果。
如上表所示,研究人员探索了FINE-GRAINED RLHF定制化语言模型行为的能力。
他们探索了三种“打分器”权重配置,并根据语言模型的平均文本生成长度,将它们分别命名为“short”、“medium”、“long”。

“short”生成了相关性更高的内容,但是事实性和完整性方面较差。与之相反,“long”提供了最准确和完整的生成内容。这反映出语言模型引用了大量的文本段落内容。而“medium”配置平衡了三种打分方法,并具有最高的得分。
不过,三个“打分器”之间还存在着竞争关系。
“相关性打分器”(the rel. reward model)偏向于生成短而简洁的回答,而”信息完整性打分器”(the comp. reward model)更偏向于生成更长、更丰富的回答。
因此,在训练过程中,这两个“打分器”会相互竞争,并最终达到一个平衡。
与此同时,“事实性打分器”(the fact. reward model)则会不断提高回答的正确性。
不过,移除任何一个“打分器”都会降低模型性能。
最后,研究人员还将他们的模型与ChatGPT的回答进行了比较。
ChatGPT在测试集上的RougeLSum得分为40.92,远低于本文使用FINE-GRAINED RLHF所训练的模型。
简单来说,ChatGPT生成的回答通常非常简洁且事实准确,但是缺乏澄清模糊问题所需的补充信息。
作者介绍
两位论文共同一作均是来自于华盛顿大学(University of Washington)自然语言处理研究小组的博士生。
Zeqiu Wu,本科就读于伊利诺伊大学电子与计算机工程系,并且取得了该校的硕士学位。
她的研究主要专注于信息检索型对话系统和通用交互系统。
曾在谷歌研究院的实习,担任学生研究员。
胡雨石(Yushi Hu),于2021年从芝加哥大学获得数学、计算机科学和经济学的学士学位。目前师从Mari Ostendorf教授和Noah A. Smith教授。
他的主要兴趣领域是多模态学习和基于人类反馈的强化学习(RLHF)。
此前,他还曾与美国阿贡国家实验室的Saidur Bakaul博士和清华大学的宁传刚教授合作过。
论文地址:
https://finegrainedrlhf.github.io/
— 完 —
「AIGC+垂直领域社群」
招募中!
欢迎关注AIGC的伙伴们加入AIGC+垂直领域社群,一起学习、探索、创新AIGC!
请备注您想加入的垂直领域「教育」或「电商零售」,加入AIGC人才社群请备注「人才」&「姓名-公司-职位」。

点这里👇关注我,记得标星哦~