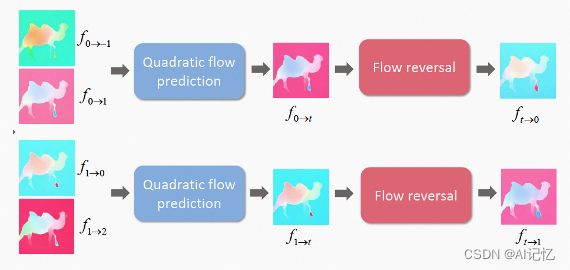
简介: 作者 | 宋晓旻
小叽导读:本文将集中分享阿里巴巴达摩院机器智能技术时序智能组与阿里数据团队合作成果——异常数据检测技术的演进和商业数据端的应用展示。文中提到的技术由阿里巴巴达摩院决策智能团队开发,本文由达摩院算法专家宋晓旻撰写。
阿里服务成千上万的商家和企业,日常的数据异常检测非常重要,一旦发生数据异常影响不可估量。
本篇文章介绍了阿里巴巴达摩院机器智能技术时序智能组与阿里数据团队合作成果——异常数据检测技术的演进和商业数据端的应用展示。
1、异常检测的业务
所谓异常检测就是监测并发现数据中不符合正常行为的异常模式。它已广泛用于交易监测、故障诊断、疾病检测、入侵检测、身份辨识等领域。例如商家退货比例飙升可能是竞争对手恶意刷单,网络流量的异常可能意味着受攻击主机上敏感信息的泄密,信用卡的异常消费等欺诈行为会导致巨大的经济损失。
异常检测在各个方面都对阿里的业务有巨大的帮助:
对于商业数据,它能更快的发现/溯源问题,帮助商业决策,赋能商业效益;
对于机器数据:在运维层面可以更快的发现、定位、排查问题。减少人力,提高服务质量;
对于保障数据安全:它能监控敏感数据,及时发现安全隐患。
以上提到数据主要都是随时间变化的,我们也集中力量开发时序数据分析的算法。
2、机器数据的异常检测
常见的时序异常检测模型包括统计模型、时序预测、无监督、有监督、关系型模型等。
在“异常数据检测技术"研究之前,达摩院时序智能组已经在高噪音“机器”数据的时序异常检测上积累了半年的经验,产品经过数月的迭代,算法框架和主要的部件如周期分解等都得到了打磨。其中的报警效果得到了业务方Tesla,kmon等的认可。
图 1. 典型机器数据的异常检测
一个典型的机器数据如上图1所示。它的噪音(起伏)较大。用户关心的往往是持续一段时间的整体变化,如图中橙色标记的点,而对于之前单个的起伏不定的单个异常不感兴趣。达摩院时序智能团队使用了Robust estimate的方法,使得算法能够区分用户感兴趣的异常和一般的噪音。
3、商业数据的异常检测
商业数据与机器数据异常检测的不同及挑战
在“异常数据检测技术"研究中,时序智能的算法遇到了新的挑战。商业数据并不能简单的复用机器数据上的算法。
首先,商业数据来源多样化,异常的定义也多样化,不可能同一组参数/算法来涵盖所有的需求。
阿里数据所研究的商业数据中常见的数据类型,包括“daily平稳”,“实时累积”,“稀疏(sparse)”,“机器数据”,“周期数据”,“非周期数据”(其它)等。
图 2. “Daily平稳”数据-例如GMV每日成交额
图 3. “实时累积”数据 - 例如pv,uv等每天清零并累积的数
图 4. “稀疏"(sparse)数据 - 例如app的访问量等
图 5. “机器数据” - 例如CPU负载,网络流量等基础设施的数据,一般抖动/噪音较大
图 6. “周期”数据-例如某些有周期性的交易或交通数据等
其次的挑战是:商业数据相对机器数据,虽然噪音较小,但是异常出现的更加频繁,敏感度要求非常准确。对漏报和误报的要求都很高。
最后一个挑战是,有的商业数据在一段时间内随时间单调上升(或下降),之前的算法会在持续上升(或下降)后报警。但是阿里数据的daily平稳数据要求不报警,并且要置信区间自动跟随数据的趋势上升(下降)。
我们将以上需求,归纳为技术上的挑战:
如何让数据自动分类与参数推荐;
如何保持让算法保持稳定的敏感度,不受异常的干扰;
如何让置信区间自动跟随数据的趋势;
这三个技术难题成了异常检测上线的拦路虎。
商业数据异常检测场景的成果
经过多次交流反馈,优化了之前的算法,并且解决了上一节中列出的三个拦路虎,让新的异常检测算法为新零售业务数据赋能。
我们在优化模型之前,它没有分解的能力,处理周期的能力很弱,且不能区分长期的整体变化和短期的突变。
原始数据直接用来预测会被异常所干扰,无法稳定的判断异常,并且置信区间的计算量非常大。
总之,优化前的算法的稳定性和可解释性比较差,对周期性和大促等异常的反应很不稳定,无法满足业务的需求。而研究后的新算法基于分解和统计模型,它的稳定性和可解释性很强,且对周期性的处理很完备,对各类异常的干扰很稳健。
下面列出4个在平台上收集的真实案例。它们都是在时序数据上做异常检测。蓝线是真实数据,算法计算出置信区间的上下界。黄线是上界,黑线是下界。如果真实数据在上下界之间是正常,超出了就是异常。
Daily平稳数据
亮点:自动识别为daily平稳数据,新算法检测
图 7.异常检测:优化前的daily平稳数据异常检测
图 8.异常检测:优化后的daily平稳数据
图7和图8对比了优化前后算法对于daily平稳的效果。在3月2~3日,交易量有了大幅的上升(图8中的红框),陡增了20%,这是一个异常。优化前的算法上下界不是很合理,上界随着数据向上移动,下界过于宽松。没有检测出这个异常。图8中,新算法根据数据近期的波动振幅自动调整安全区间的上下界,宽度合理,正确的识别出3月2号的这个异常。并且,之后几天的上下界一直比较平稳,没有受到这个异常的扰动。
实时累积数据
亮点:优化后算法区间灵敏度高,保障不漏报
图 9.异常检测:优化前的累积数据
图 10.异常检测:优化后的累积数据
图9中的上下界过宽,会漏掉很多异常。而图10中的上下界离真实数据非常近,保障不漏报。
机器数据
亮点:优化前算法完全不可用,优化后能自动识别高噪音数据,合理设置数据上限安全区间
图 11.异常检测:优化前的非周期数据
图 12.异常检测:优化后的非周期数据
对于机器数据,图11的上下界随着高噪音数据上下跳动,不可靠。图12中的上下界非常稳定,且不受大促(3/4)的高点影响。
稀疏数据
亮点:优化后能自动识别为稀疏、并识别数据周期,优化前算法完全不可用
图 13.异常检测:优化前的稀疏数据
图 14.异常检测:优化后的稀疏数据
图13中优化前的算法无法对稀疏数据的进行检测。图14的优化过的算法,可以提取稀疏数据中的高点,进行判断,减少了大量的误报。
商业数据异常检测的技术
数据的自动分类与参数推荐
由于涉及到接入数据类型的错综复杂,既有商业数据,也有机器数据;商业数据中也有很多种类。用户需求以及对异常的定义也不尽相同。在大规模部署的时候,不可能每一条都去人工识别和配置。
我们对数据和业务进行总结,归纳业务方的需求。总结出以下解决方案:
(1)将数据类型归纳为上节介绍过的“daily平稳”,“实时累积”,“离散数据”,“机器数据”,“周期数据”或其它等并开发出分类器,在进行检测前会自动识别数据类型。
(2)针对数据类型,自动适配不同的模型和参数。如图15所示。
(3)分解流程:去除周期/趋势等影响检验精度的分量
(4)鲁棒的统计检验:稳定,准确的判断异常。
图15.数据自动分类/参数推荐/分解/检验的流程
分类器根据数据的特征来工作。分类器会做以下操作:读取采样率,判断数据每天归零的特性,测量稀疏性,测量噪音大小,判断周期性等等。然后综合判断数据该属于那一类。在保证准确性的基础上,我们优化了分类器的速度,检测时间达到毫秒级。
保持算法保持稳定的敏感度
我们开发了基于M-estimator的方法过滤参考区间的异常,并加入了时间衰减(decay)的系数来调整权重。这保证了算法具有稳定的敏感度,不受异常的干扰。我们称之为Robust Ttest。
图16. 置信区间受异常影响的效果比较。从上往下:(1)没有加Robust Ttest的检测效果。(2)加入Robust Ttest,没有decay(3)加入Robust Ttest,decay=0.8 (4)加入Robust Ttest,decay=0.6
由于缺乏打标的数据作为参照,我们选择了基于统计的无监督异常检测算法,并做了假设:例如数据分布接近高斯分布,异常数据出现的频度相对于正常数据较为稀少等。当实际数据违背假设时,就需要对算法做修正。比如,当异常出现并滑动进入左窗口, 即作为参考的数据窗口,就把参考窗口中本来近似与高斯分布打破了。此时需要识别并去除异常的干扰。
对图16的详细解释如下。从上往下:(1)没有加入Robust Ttest和decay,可以看到异常右侧的置信区间被异常所干扰,上下宽度变的很大并导致漏报。(2)加入了Robust Ttest,没有decay,可以看到异常右侧的置信区间没有被异常所干扰。但是,在右侧有趋势下降时,置信区间不能很快的跟随。(3)加入了Robust Ttest,并设置decay=0.8,在右侧有趋势下降时,置信区间可以有跟随。(3)加入了Robust Ttest,并设置decay=0.6,在右侧有趋势下降时,置信区间可以很快的跟随。
置信区间能够跟随数据的趋势
为了使置信区间能够跟随数据的趋势,检测违反趋势的异常点。我们采用了基于HP filter的detrend技术,解决了这个难题。
使用了Robust Ttest和decay之后,有些数据(如图3)具有长期的趋势,置信区间依然不能及时的跟随。我们使用了基于HP filter的除趋势(trend)处理。使得置信区间能够随着长趋势上升或者下降,只检测单点的突起。
图17.过年期间daily平稳数据的异常检测,原数据为深蓝实线,上界为灰虚线,下界为淡蓝虚线,原数据超过上下界为异常(1)上图未经过去除趋势的处理, 上下界很不稳定 (2)下图经过了去除趋势的处理,上下界稳定。
4、总结
商业数据的异常出现的更加频繁,数据漏报和误报的要求都很高,数据类型也更加多样化。这些挑战,被我们在研究中一一阐明,并一一解决。
本文部分内容除引自内部文献外,部分内容引自:
Q. Wen, J. Gao, X. Song, L. Sun, H. Xu, and S. Zhu, "RobustSTL: A Robust Seasonal-Trend Decomposition Algorithm for Long Time Series," in Proc. Thirty-Third AAAI Conference on Artificial Intelligence (AAAI 2019), Honolulu, Hawaii, Jan, 2019. Link
Qingsong Wen, Jingkun Gao, Xiaomin Song, Liang Sun, Jian Tan. RobustTrend: A Huber Loss with a Combined First and Second Order Difference Regularization for Time Series Trend Filtering. Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI-19).Link.