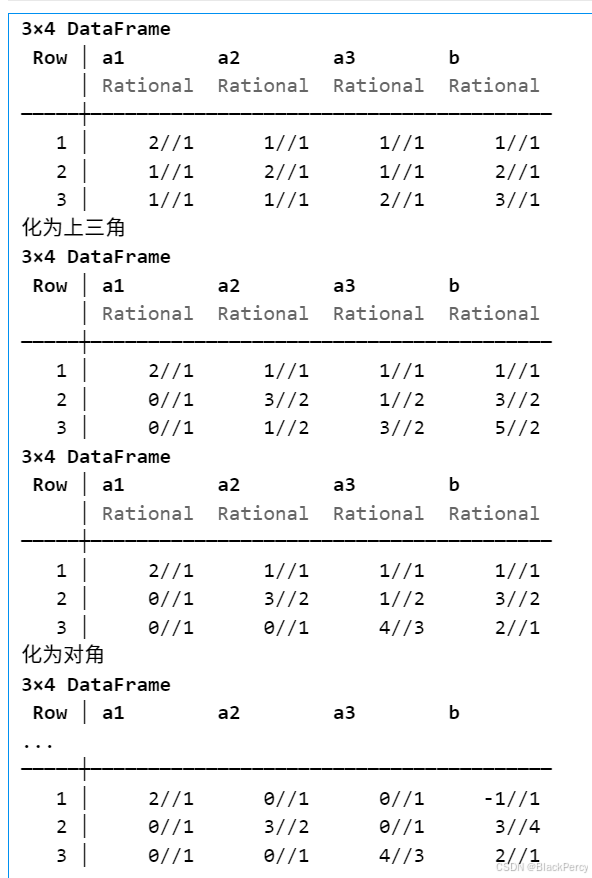
在实际应用中,三元组抽取面临语义模糊性的问题,这主要体现在输入文本的非规范描述、复杂句式以及多义性等方面。为了有效处理这种模糊性,研究者们提出了多种方法和技术,以下是一些关键策略:
-
基于深度学习的方法
深度学习模型,如BERT和GPT等预训练模型,被广泛应用于处理语义模糊性问题。例如,BERT通过双向Transformer架构,能够更好地捕捉上下文信息,从而提高对模糊语义的理解能力。此外,GPT-3等大型语言模型也展示了在少量样本学习中的强大性能,能够通过少量的训练数据解决模糊语义问题。 -
模糊逻辑与三角模糊数
在模糊逻辑框架下,三角模糊数(如三角模糊数的隶属函数)被用来量化模糊性。例如,通过将模糊术语转换为三角模糊数,可以更精确地表示模糊概念。此外,基于模糊逻辑的方法还可以通过去模糊化中心模型计算模糊值,从而将模糊信息转化为清晰的输出。 -
知识图谱与本体构建
知识图谱和本体构建在处理语义模糊性方面具有重要作用。例如,在本体构建过程中,通过选择性约束和类成员资格分析,可以减少模糊性带来的冗余问题。此外,知识图谱结合自然语言处理技术,可以更灵活地表示复杂和模糊的信息。 -
多义性消解与语义角色标注
多义性是语义模糊性的核心问题之一。通过语义角色标注(SRL)技术,可以识别句子中的动词及其对应的主语和宾语关系,从而减少歧义。此外,通过加权解析和生成随机语法等策略,可以进一步优化解析结果。 -
数据预处理与特征提取
数据预处理和特征提取是解决语义模糊性的基础步骤。例如,在法律领域的三元组抽取中,通过命名实体识别技术和词嵌入技术提取特征,可以提高模型对模糊语义的处理能力。此外,针对中文短文本的关系抽取研究也表明,通过词嵌入和知识增强的方法可以有效处理模糊语义。 -
模糊决策方法
在某些特定场景中,模糊决策方法被用来处理语义模糊性。例如,mF-极模糊TOPSIS方法结合了mF语义和TOPSIS技术,能够处理多标准决策制定中的模糊性和不确定性。 -
模糊搜索与相似度计算
在数据库查询中,通过计算字符串共享的三元组数量来衡量相似性,可以有效应对输入错误和模糊性。 -
结合人类反馈与模型优化
通过人工标注和模型优化相结合的方式,可以提高三元组抽取的准确性。例如,在实验中手动为抽取的三元组分配正确性标签,并通过推理规则增强信息性。
三元组抽取在处理语义模糊性时需要综合考虑深度学习、模糊逻辑、知识图谱、数据预处理等多种方法。这些方法不仅能够提高模型对模糊语义的理解能力,还能在实际应用中实现更高效的信息抽取和知识表示。