文章
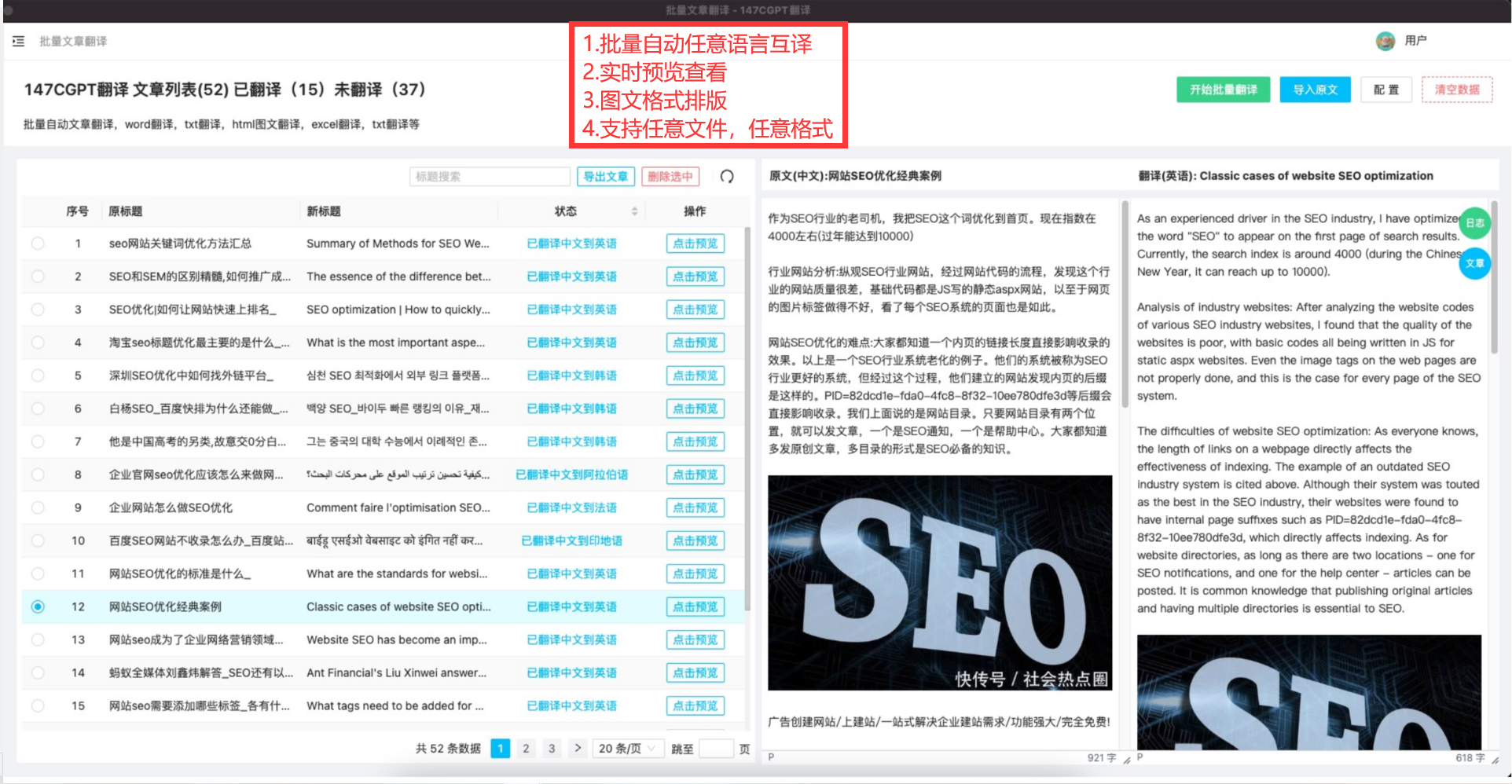
- 🧐一、我们在做什么
- 🥱二、项目详情
- 1.前端🙂
- (1)基本要求😐
- (2)批量操作功能🙁
- (3)模式选择功能 😟
- (4)模型选择功能😞
- (5)总结😩
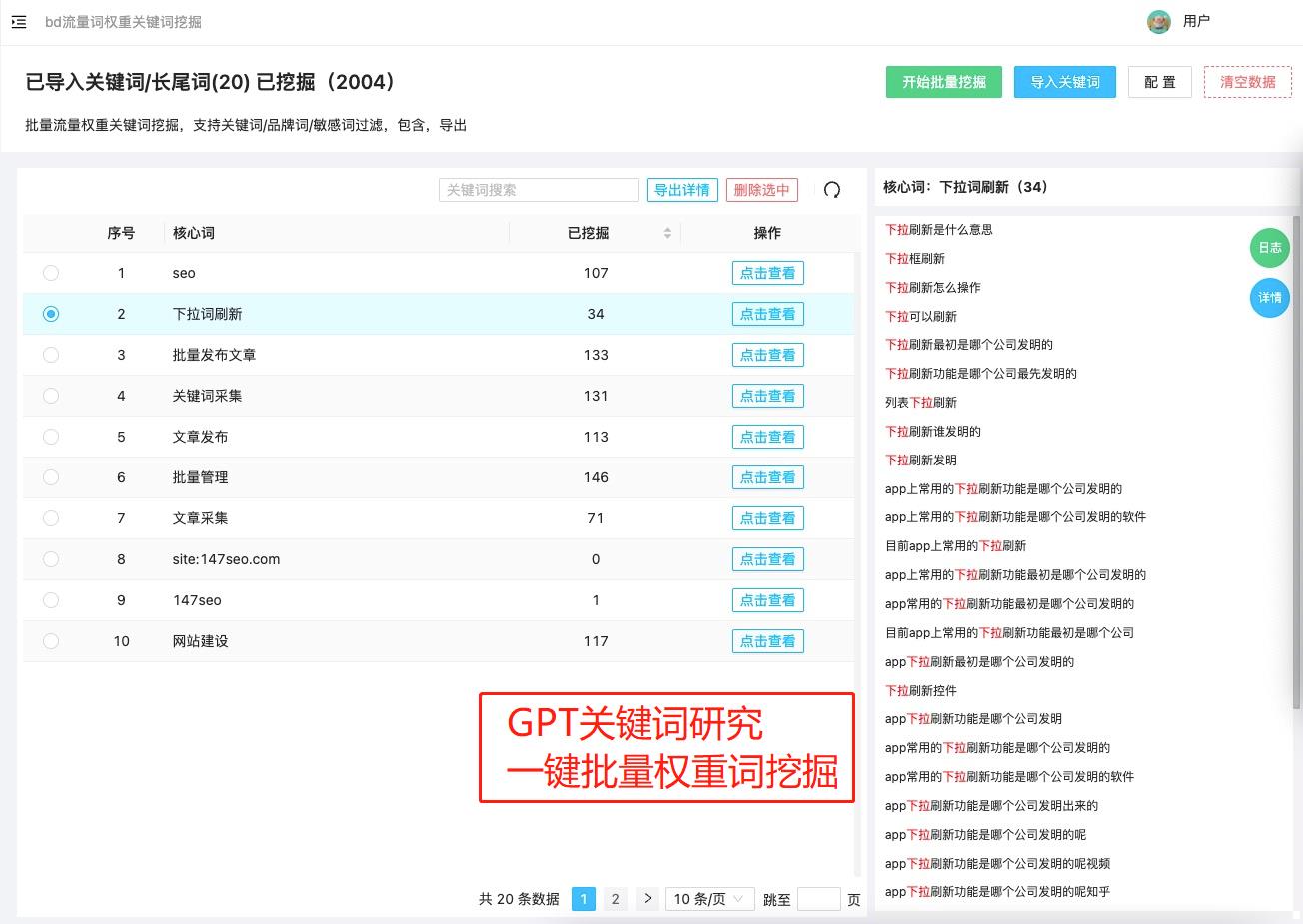
- 2.后端😶
- 前言
- (1)模型简介🤒
- (2)数据预处理👓
- (3)训练模型⏳
- (4)文本生成的原理🔐
- (5)标题相似度计算😵
- 3.功能演示😎
- (1)🍺根据标题生成文章
- (2)🍻批量文本生成
- 4.🍌运行环境配置
- (1)🍋前期准备
- (2)🍍具体配置
- 三、👯♂️COR
- 四、🤪项目相关资料
🧐一、我们在做什么
这次团队接到了一个外包项目😎,项目的大致内容就是根据给定的标题自动生成文章,然后做一个可视化界面方便用户进行交互。然后客户大致有这么两个基本需求🤔:
- 首先能够根据用户给定的数据训练一个模型,到时候可以利用模型和所给的标题来生成与客户给定数据相同类型的文章。
- 其次能够有一个基本的可视化界面,与后端的模型连接起来,方便交互。
🥱二、项目详情
1.前端🙂
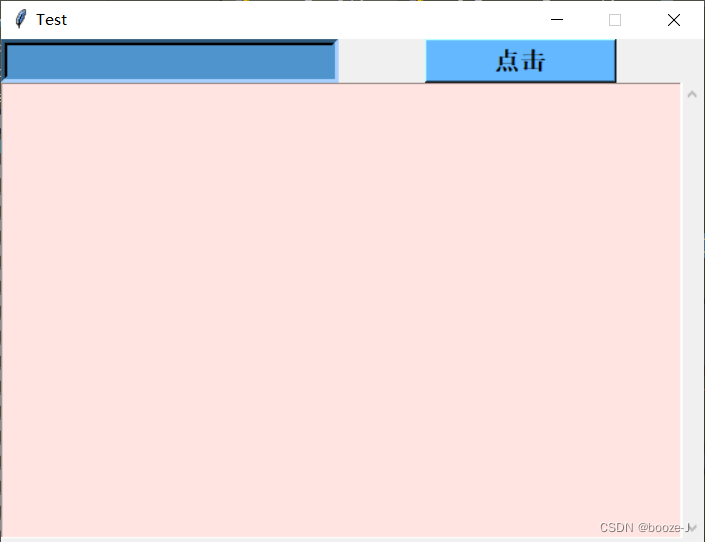
(1)基本要求😐
客户对于前端的需求是首先要有一个输入框来接收用户输入的标题,然后要有一个按钮用于事件的开始,最后需要一个基本的文本框用于输出文本。上面所描述的是最基本的大致的前端界面😶。
如下图所示:
(2)批量操作功能🙁
随着项目的不断推进,客户的需求也在不断的改变🙃,客户说要添加批量操作功能,我说行🙃!
批量操作功能大致的意思就是原来要生成文章,标题需要一个一个的输入,一个一个的保存,现在你只需要将所要生成文章的标题,按换行符分隔写入一个txt文件再读取txt文件中的题目进行批量生成,自动保存到本地。
这个时候咱的前端界面也就需要发生改变了,为了添加这个功能,我在原有的图形化界面之上添加了一个菜单栏,用于实现批量文章生成的功能和保存文本框内容的功能。


(3)模式选择功能 😟
又随着项目的不断推进,客户的需求还在不断的改变🙃,客户说要模式选择功能,,我说行🙃!
模式选择功能大致的意思就是添加两种模式,相当于是一个层次选择的功能,有一个优先级,当用户输入一个标题的时候选择模式一的话,优先级是先对标题在百度进行搜索,若搜到结果则返回文章,若未搜索到结果则对本地数据库进行索引,将输入的标题与数据库中的标题进行rough相似度比对,相似度大于指定值则返回对应标题的数据库文章。若在本地数据库未找到指定标题对应的文章,则使用模型对输入的标题进行AI 生成文章。当用户输入一个标题的时候选择模式二的话,就是直接使用模型对标题进行AI 文章生成。
添加模式选择功能后,前端页面也要有对应的改变,然后就在现有的前端页面之上添加了两个复选框,用于模式的切换与选择。
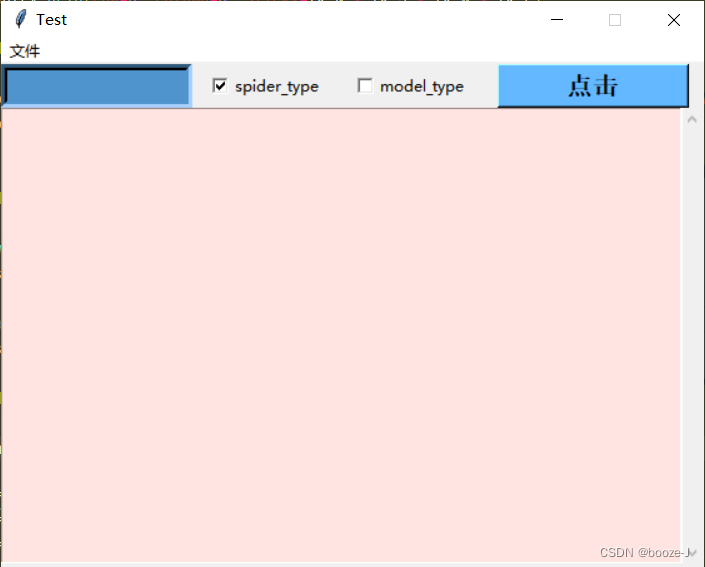
(4)模型选择功能😞
又又随着项目的不断推进,客户的需求仍旧在不断的改变🙃,客户说要模型选择功能,我说行🙃!
模型选择功能大致的意思就是用户可以自己更改模型🤡,相当于增加了可扩展性吧。在项目中默认有一个20万条{标题:文章}数据训练的初始化模型,然后用户希望之后自己也可以用其他类型的数据训练出模型来自动生成其他类型的文章。也有一个优先级关系,默认情况下使用的是项目中自带的模型,若用户切换自己训练的模型,则以用户自己训练的模型为主。
添加了这个模型选择功能之后,只对前端进行了微调,在菜单栏文件的子栏添加了一个选择模型功能。

(5)总结😩
所有上面在开发过程中添加或者修改的功能,前端界面的修改倒是问题不是很大🍖,关键是伴随着前端页面的修改,后端逻辑的修改才是难点🤯,每次前端页面的修改都可能会涉及到部分代码的重构,可能整体程序的解耦没有做的很好,所以每次修改难度还是有的。
2.后端😶
前言
首先我们团队之前并没有接触😱过通过标题生成文章的这类自然语言方面的项目,但是做过类似的项目,通过GPT2模型根据文章来生成标题。然后,就想着直接逆过程能不能行,就是将输入和输出换了一个方向,相当于原来是文章作为输入,标题作为输出对模型进行训练,换成现在 标题作为输入,文章作为输出对模型进行训练。我们尝试训练了之后,训练出来的模型进行测试发现效果不是很好,这样生成的文章不仅读不通顺,而且存在许多的重复语句,根本达不到客户的需求。经历了这次失败的经验之后,我们也在网上查阅了很多相关的资料,换了一种更加成熟、效果可能更好的模型,CPM(Chinese Pretrained Models)模型👻。
(1)模型简介🤒
CPM(Chinese Pretrained Models)模型是北京智源人工智能研究院和清华大学发布的中文大规模预训练模型🤓。官方发布了三种规模的模型,参数量分别为109M、334M、2.6B。
我们团队采用了109M的CPM模型(若资源允许也可以考虑334M的模型),并且简化了模型的训练和使用。
由于GPU资源有限,建议采用使用cpm-small.json中的模型参数,若资源充足,可尝试cpm-medium.json中的参数配置。
本项目的部分模型参数如下:
- n_ctx: 1024
- n_embd: 768
- n_head: 12
- n_layer: 12
- n_positions: 1024
- vocab_size: 30000
(2)数据预处理👓
每篇作文对应一个txt文件,txt内容格式如下{标题+文章} 📖:
我的爸爸我的爸爸长得不帅,个子也不高,更没有一个好的工作。为了让我们生活得更好,他离开家人,独自在外打工,吃苦受累。
爸爸很爱我们,他一年才回家一次,每次回来的时候都会给我和姐姐带许多我们爱吃的东西。可是爸爸每一次回来都比上次要苍老许多。他的头发已经逐渐花白了,脸上也有了许多抚不平的皱纹。
每次爸爸回来的第一个晚上,我们总会和他玩到半夜。爸爸每次回来后,总有许多的`事情,但他总会抽出—些时间陪我们逛街,陪我们玩耍。
记得小时候,爸爸总会把我扛在肩上,把姐姐背在背上,那时候,我就觉得爸爸是超人,什么事情都能做到。他也总会满足我们的需求,他说,只要我们好好学习,他再苦再累也都值得。
爸爸还特别有孝心。每次回家他都要抽时间陪奶奶,不在家的时候也总会打电话给奶奶,陪她聊聊天,说说话。我长大了,也要像爸爸这样有孝心,好好孝敬爸爸妈妈
我的爸爸虽然在别人眼中很平凡,但在我心目中他是最伟大的。对于每个txt文件,首先取出标题与内容,转化为json格式,将标题与内容按照title[sep]content[eod]的方式拼接起来,然后对其进行tokenize 最后使用滑动窗口对内容进行截断,得到训练数据。
运行如下命令,进行数据预处理。注:预处理之后的数据保存为train.pkl,这是一个list,list中每个元素表示一条训练数据。
python preprocess.py --data_path data/my_txt --save_path data/train.pkl --win_size 300 --step 300
超参数说明:
- vocab_file:sentencepiece模型路径,用于tokenize
- log_path:日志存放位置
- data_path:数据集存放位置
- save_path:对训练数据集进行tokenize之后的数据存放位置
- win_size:滑动窗口的大小,相当于每条数据的最大长度
- step:滑动窗口的滑动步幅
(3)训练模型⏳
运行如下命令,使用预处理后的数据训练模型。
python train.py --epochs 100 --batch_size 16 --device 0,1 --gpu0_bsz 5 --train_path data/train.pkl
超参数说明:
- device:设置使用哪些GPU
- no_cuda:设为True时,不使用GPU
- vocab_path:sentencepiece模型路径,用于tokenize
- model_config:需要从头训练一个模型时,模型参数的配置文件
- train_path:经过预处理之后的数据存放路径
- max_len:训练时,输入数据的最大长度。
- log_path:训练日志存放位置
- ignore_index:对于该token_id,不计算loss,默认为-100
- epochs:训练的最大轮次
- batch_size:训练的batch size
- gpu0_bsz:pytorch使用多GPU并行训练时,存在负载不均衡的问题,即0号卡满载了,其他卡还存在很多空间,抛出OOM异常。该参数可以设置分配到0号卡上的数据数量。
- lr:学习率
- eps:AdamW优化器的衰减率
- log_step:多少步汇报一次loss
- gradient_accumulation_steps:梯度累计的步数。当显存空间不足,batch_size无法设置为较大时,通过梯度累计,缓解batch_size较小的问题。
- save_model_path:模型输出路径
- pretrained_model:预训练的模型的路径
- num_workers:dataloader加载数据时使用的线程数量
- warmup_steps:训练时的warm up步数
(4)文本生成的原理🔐
文章生成的原理,模型将每次的输出拼接上一个输入,作为下一次的输入,一直迭代,直至模型生成的长度大于等于最大长度。比如:
第一次迭代:input:我的爸爸 output:长
第二次迭代:input:我的爸爸长 output:得
第三次迭代:input:我的爸爸长得 output:不
......
以此类推,直至文章的长度大于1.5倍的最大长度或者输出字符为终止符号[eod]或者超过最大长度下一个预测字符为“。”,都会停止迭代。文章生成完毕。
(5)标题相似度计算😵
我们团队的AI智能创作平台,不但提供了AI文章生成的功能,而且提供了基于百度和数据库的文章生成,通过计算标题的相似度,来选择源文章,然后使用源文章生成目标文章。相似度的计算方法:my_rogue-1,优点:计算速度快。
举例
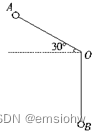
句子a:
我的爸爸长得帅。
句子b:
我的爸爸长得非常帅。
分子是a,b句子中共现的字个数,分母是a,b较长句子的字的个数。
P = L e n ( S a ∧ S b ) M a x ( L e n ( S a ) , L e n ( S b ) ) P = \frac{Len(S_a\land S_b)}{Max(Len(S_a),Len(S_b))} P=Max(Len(Sa),Len(Sb))Len(Sa∧Sb)
上述例子的相似度为:7/9
3.功能演示😎
(1)🍺根据标题生成文章

(2)🍻批量文本生成
4.🍌运行环境配置
(1)🍋前期准备
本项目整体代码是基于python语言实现的,所以我们需要准备好以下开发工具:
- anaconda - anaconda的安装使用可以参考博客anaconda详细安装使用教程或者安装miniconda也行,详细可以参考文章miniconda安装与使用 - 知乎 (zhihu.com)。
- pycharm - pycharm安装官网的社区版就够用了,pycharm的安装可以参考博客pycharm从安装到全副武装,学起来才嗖嗖的快,图片超多,因为过度详细!
(2)🍍具体配置
- 1.打开Anaconda Prompt,输入
conda create -n pytorch python=3.7
创建一个python版本为3.7的虚拟环境。
- 2.进入到pytorch虚拟环境
conda activate pytorch
-
3.在pytorch虚拟环境安装项目运行所必须的第三方库
- 安装pytorch,pytorch下载官网,安装时大家注意自己cuda的版本,没有显卡的可以安装cpu版。pytorch的安装可以参考博客PyTorch 最新安装教程(2021-07-27)
# CUDA 10.2 conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=10.2 -c pytorch- 安装transformers
pip install transformers==4.6.0 -i https://pypi.tuna.tsinghua.edu.cn/simple- 安装bs4
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple beautifulsoup4- 安装sentencepiece
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple sentencepiece- 安装jieba分词库
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple- 安装ttkbootstrap
pip install ttkbootstrap -i https://pypi.tuna.tsinghua.edu.cn/simple- 安装flask_cors
pip install flask_cors -i https://pypi.tuna.tsinghua.edu.cn/simple- 安装textrank4zh
pip install textrank4zh==0.3 -i https://pypi.tuna.tsinghua.edu.cn/simple- 安装scipy
pip install scipy==1.7.3 -i https://pypi.tuna.tsinghua.edu.cn/simple -
4.环境配置配置好了之后,使用pycharm打开项目,并将pycharm链接刚刚配好的pytorch虚拟环境的解释器(python.exe),运行main文件即可☕。
三、👯♂️COR
想要了解更多,+V:1|8|7|9|0|3|7|8|7|2|1|
四、🤪项目相关资料
github仓库地址🙈
gitee仓库地址🙉
博客首页🙊