Waitlist了三个星期,今天下午终于拿到了百度文心一言的体验资格,于是立刻展开测试。
根据文心一言网页端信息显示,目前最新发版是4月1号的版本,版本号是v1.0.3,应该是从上个月16号发布会以后又做了两版迭代。根据文心一言自己的回答,可以看到文心一言是基于百度飞桨和文心大模型发布的大语言模型。

话不多说,笔者下午对文心一言做了50来次测试,就其中的10来个问题与GPT-4的回答做了对比测试。这里贴一些截图展示给大家参考。
中文作诗
以“春末夏初”为题,作一首藏头诗。

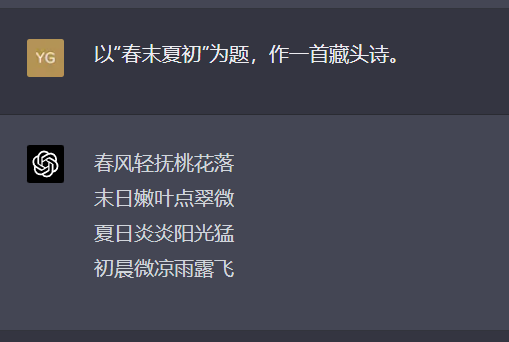
从诗歌的角度看,文心要明显写得更差一些。
中国历史文化
为了证实文心一言是否真的在中文上表现要好于GPT,笔者在这方面多做了一些测试。
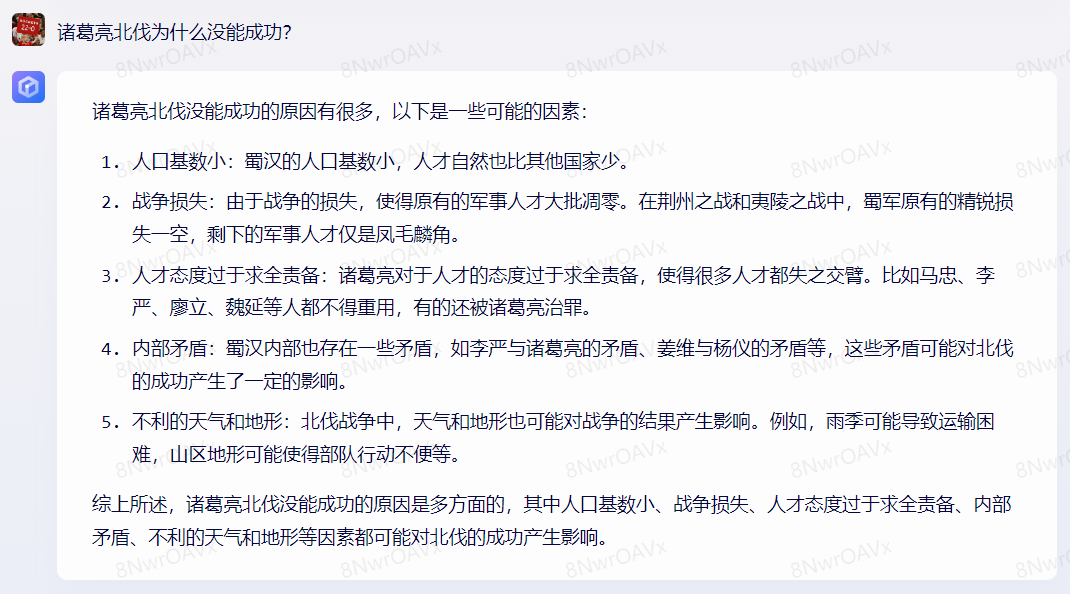
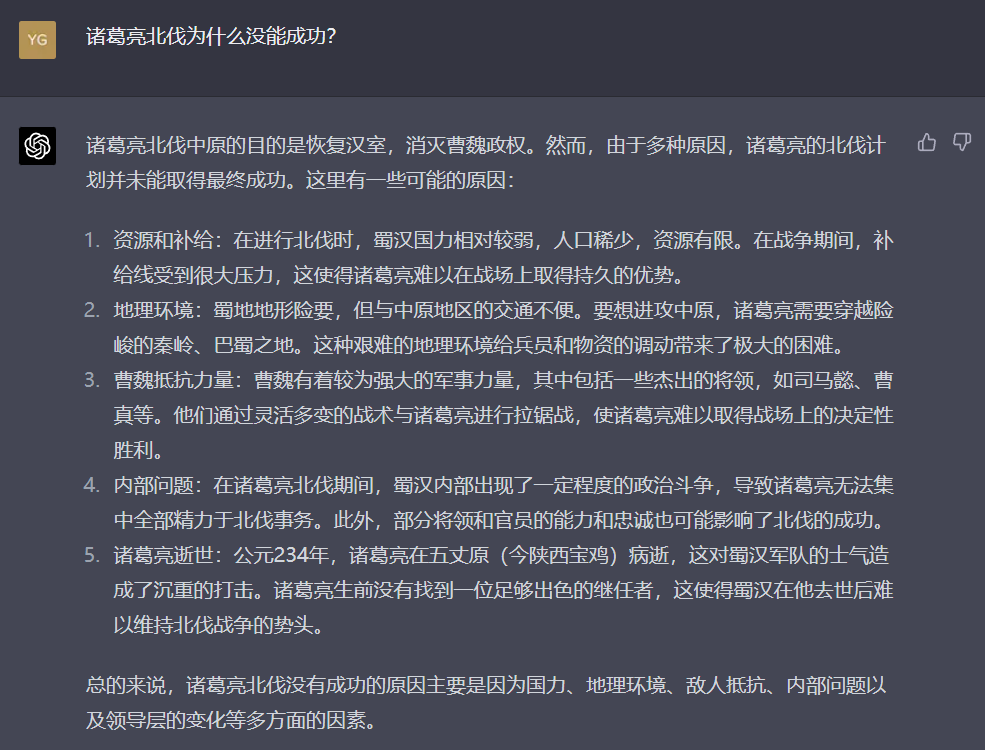
对于诸葛亮北伐为什么没能成功这个问题的回答,虽然GPT-4表现不算差,回答的也很全面,但就回答深度和质量上来讲,文心一言的表现要更胜一筹。但稍微问点冷门或者专业一点的历史问题时,文心一言和GPT-4都会犯错误。
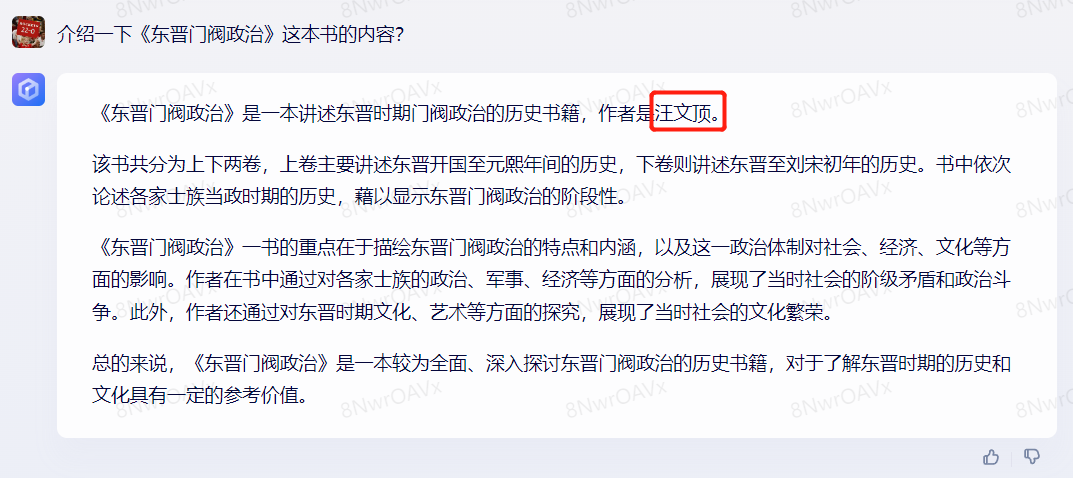
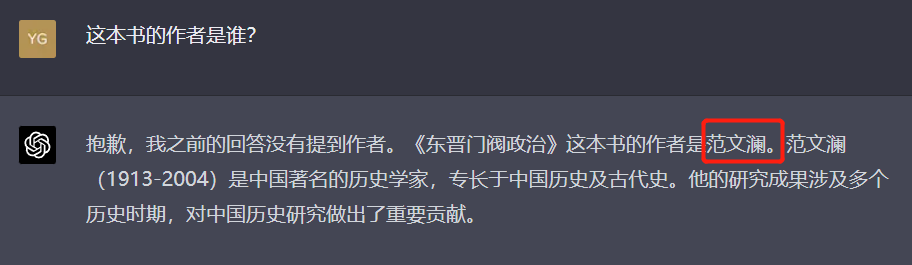
对于《东晋门阀政治》这本书的介绍,GPT-4和文心一言都犯了事实性错误,GPT-4说作者是范文澜先生,并且还给错了先生的生卒年份;而文心更没谱,给了一位文学作家的名字。而对于一些名著和常识性的文化问题的回答,二者都能给出不失偏颇的回答。
代码能力
笔者也重点关注了文心一言在代码上的表现。代码可以重点体现一个LLM的推理能力,所以笔者也在代码上做了不少测试。整体上来看,文心一言的代码能力相较于上个月发版的时候要提升了不少,因为笔者并没有实际测试运行二者生成的代码,所以暂时还不能对二者做更深入的评价。
先用JS简单写个冒泡排序:
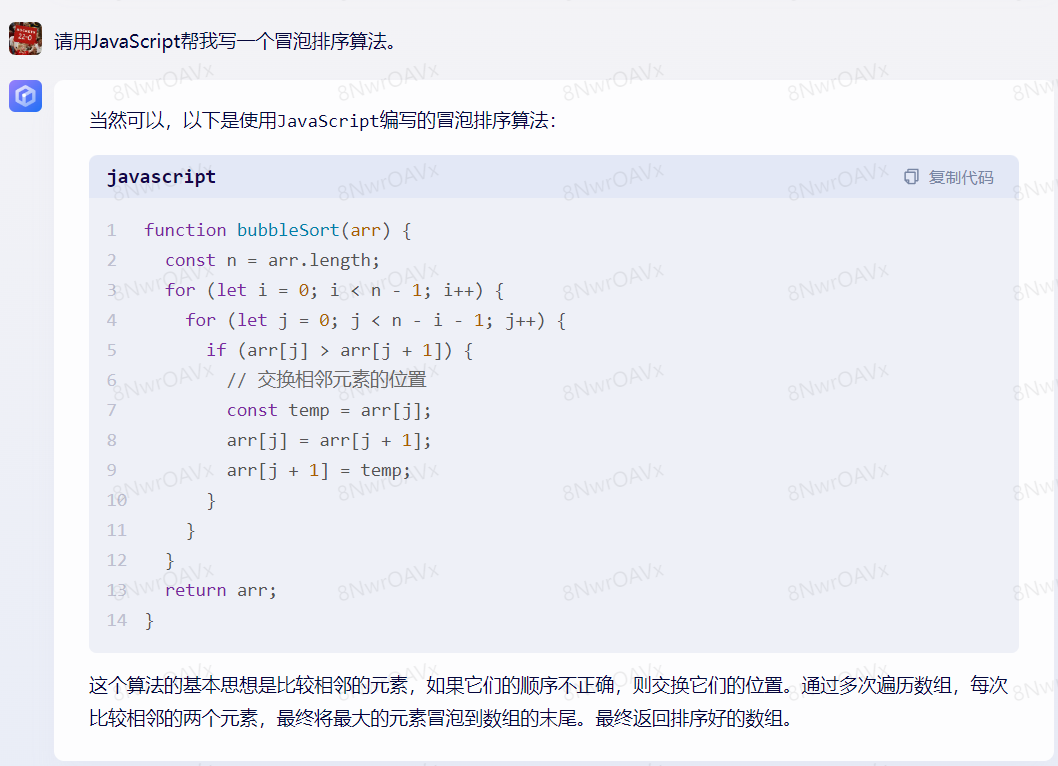
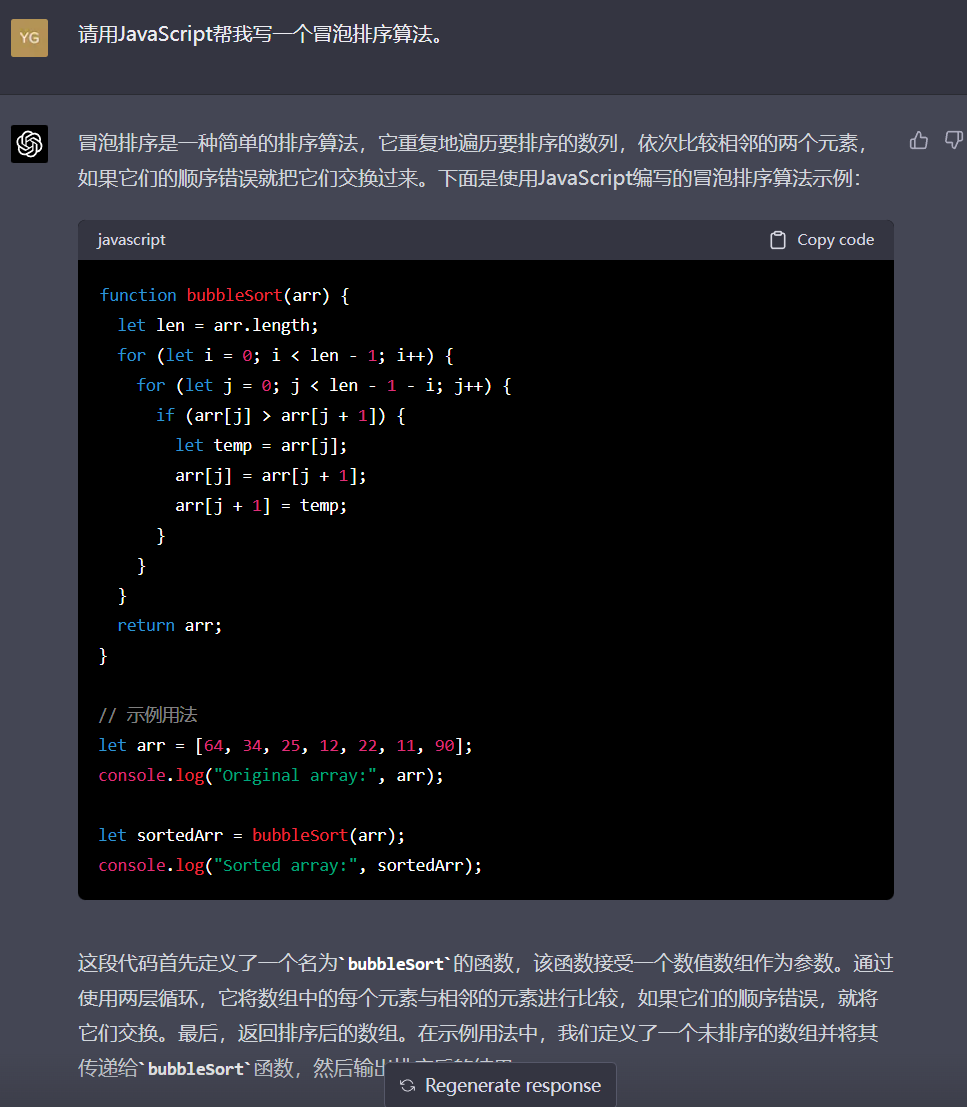
二者代码基本一致,差异在于GPT-4给了测试用例,文心仅做了简单解释就结束回答。再看看在深度学习方面的表现:
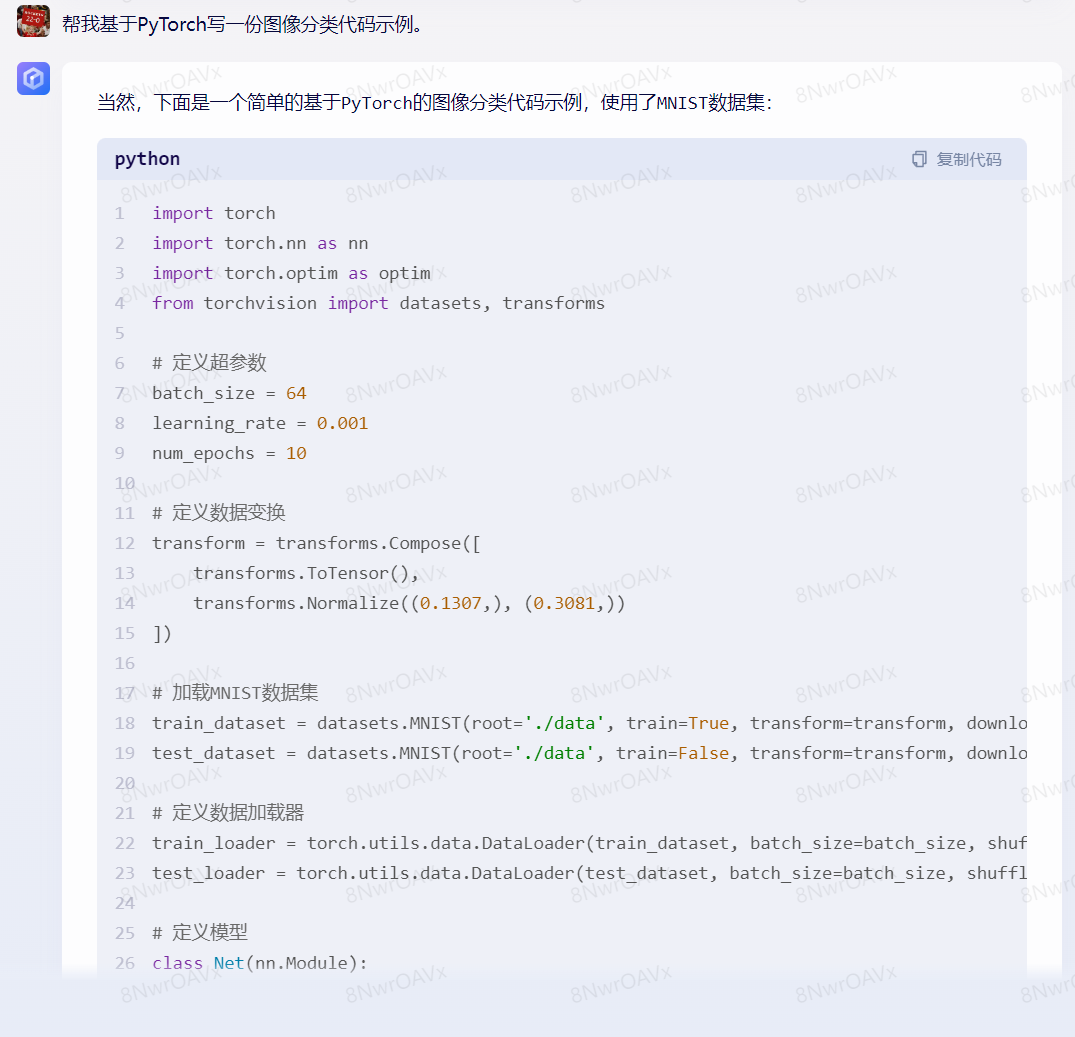
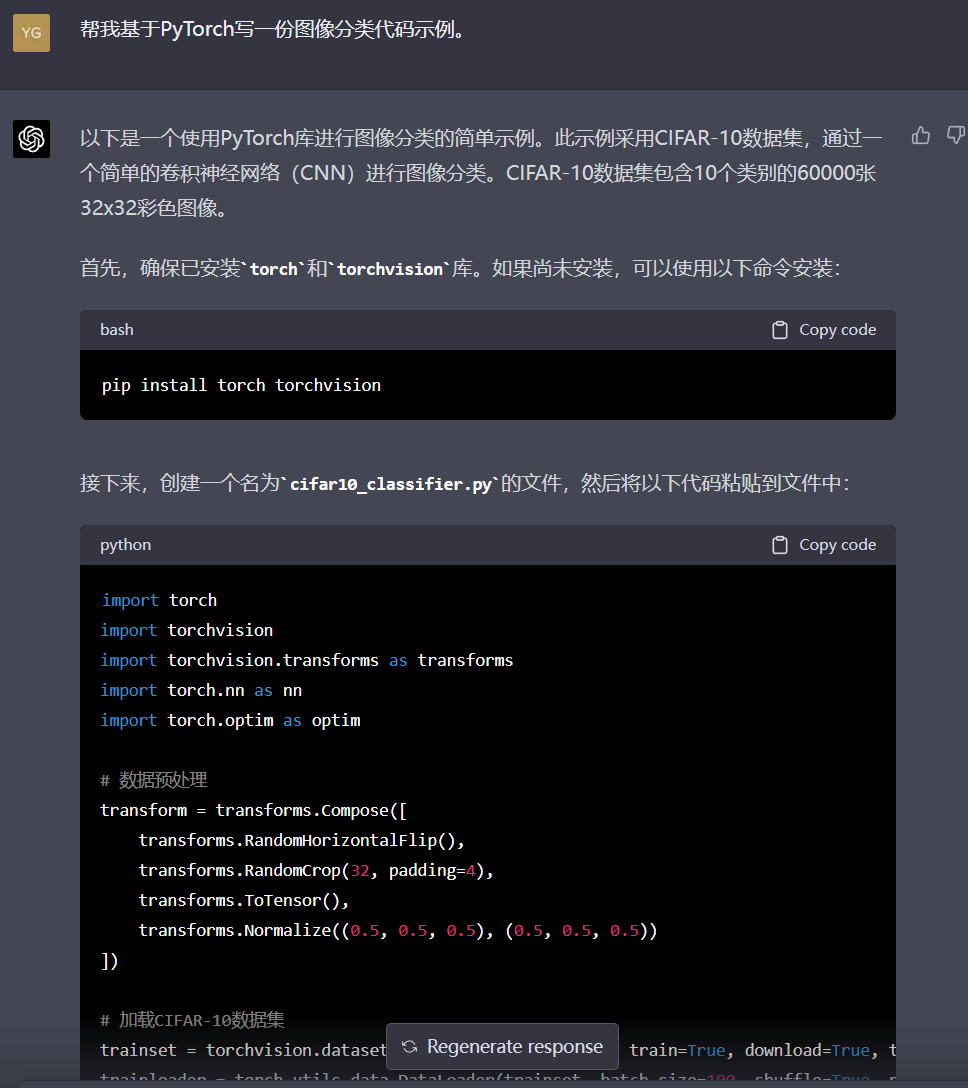
截图没截全,但笔者对比了下,二者代码结构上差异不大,但GPT-4对于代码的解释更加全面。
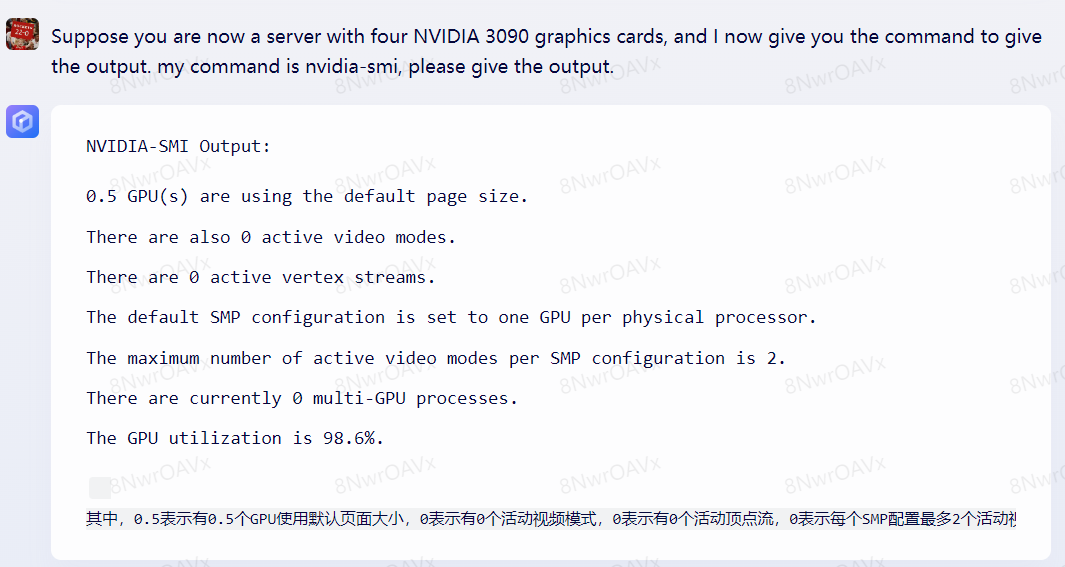
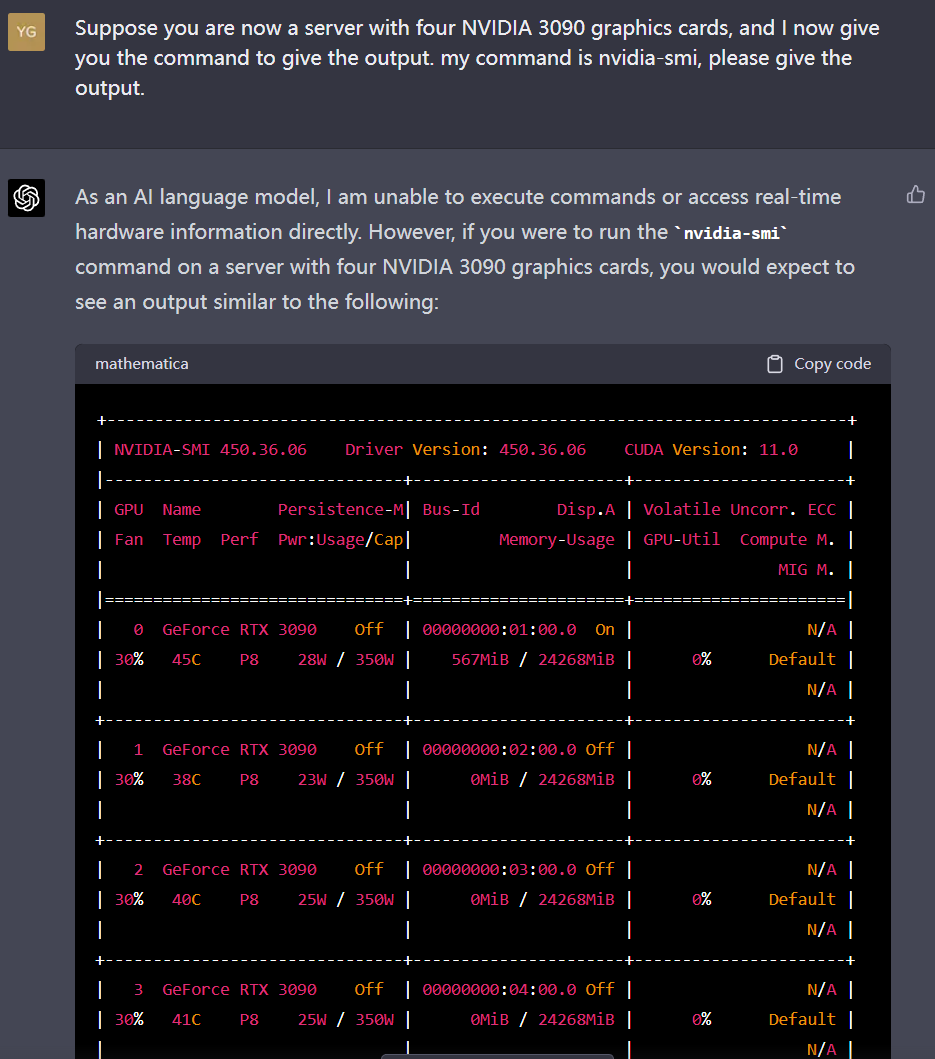
最后,笔者又让二者分别角色扮演一下一个拥有四张3090显卡的服务器,根据指令进行输出,在这一项上,文心一言表现远不如GPT-4。
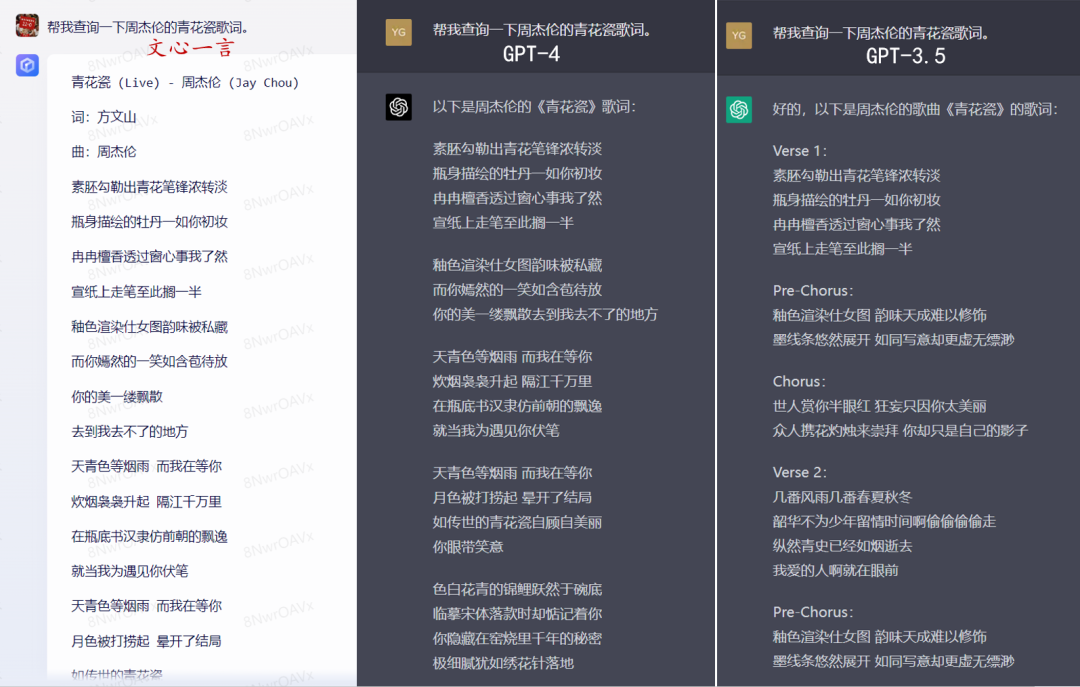
内容查询
在内容查询方面,笔者让二者分别查询周杰伦的《青花瓷》歌词,文心一言和GPT-4均能给出正确的歌词,但GPT-3.5完全在做生成,并未起到查询功能。
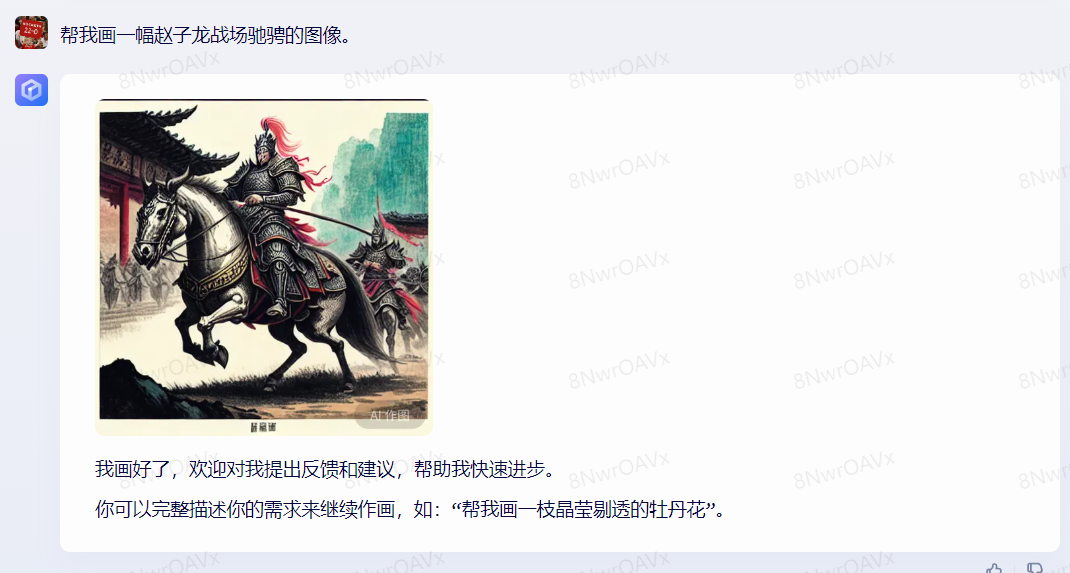
多模态
虽然GPT-4有着难以置信的多模态图像输入和生成能力,但暂时还无法体验到。好在文心一言直接给出了图像生成和AI作图功能,所以最后我们来看一下文心的绘图水平。


总体测试下来看,文心一言的表现是超乎笔者预期的。虽然距离GPT-4在推理能力上还有一定差距,但百度敢于在国产AI上率先发布和对标ChatGPT,属实难能可贵。从这一点上来看,笔者希望国产AI能够迎头赶上,早日做出影响全球的AI产品。
另外,为了聚集更多的人参与到AI生产力工具上来,笔者前几天特意组建了一个名为【ChatGPT实验室】的知识星球,目前已有140+读者加入,星球的主要定位包括:
1. 如何基于ChatGPT提高工作和学习效率。
2. 跟踪NLP、LLM、AIGC和AGI的前沿动态和最新进展。
3. 分享ChatGPT的最新应用和玩法。














![[ 攻防演练演示篇 ] 利用谷歌 0day 漏洞上线靶机](https://img-blog.csdnimg.cn/66e590b543704bc1a03be2b72a90276c.png)
