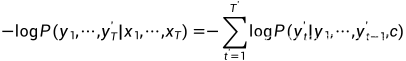在爬虫操作中难免会遇到文字验证码识别,处理方法有很多这次要说得是百度api的调用来对文字进行识别。分两步走第一:百度AI开放平台注册并建立自己的项目。第二:写代码。
百度AI平台创建项目
- 创建自己的账号,登录之后出现页面如下:

- 你需要文字识别就点击文字识别,并点击创建应用。

我的已经创建好了,有个API Key和Secret Key要记住也不要给别人哈,点击技术文档。
- 点击技术文档那里在调用方式可以看到他们的使用方法

看完之后需要什么的代码直接复制,我这里使用的是python代码
# encoding:utf-8import requests
import base64'''
通用文字识别(高精度版)
'''request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
# 二进制方式打开图片文件
f = open('[本地文件]', 'rb')
img = base64.b64encode(f.read())params = {"image":img}
access_token = '[调用鉴权接口获取的token]'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:print (response.json())
这里的只是百度api使用文档里的代码
验证码识别代码如下:
import keyword
from PIL import Image
from aip import AipOcrimport requests
import base64'''
通用文字识别(高精度版)
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
#二进制方式打开图片文件f = open('./ma.png', 'rb')
img = base64.b64encode(f.read())
host = 'https://aip.baidubce.com/oauth/2.0/tokengrant_type=client_credentials&client_id={API Key}&client_secret={Secret Key}'
response = requests.get(host)
if response:token = response.json()['access_token']# print(token)params = {"image":img}access_token = tokenrequest_url = request_url + "?access_token=" + access_tokenheaders = {'content-type': 'application/x-www-form-urlencoded'}response = requests.post(request_url, data=params, headers=headers)if response:# print(response.json())res_json = response.json()['words_result']for res in res_json:print(res['words'])