1.embedding
1.介绍:
- embedding就是用一个低纬的向量表示一个物品。而这个embedding向量的实质就是使
距离相似的向量所对应的物品具有相似的含义(参考皮尔逊算法和cos余弦式子:计算相似度) - 简单来说,就是用空间去表示物体,解释了物品之间的潜在关系;
2.如何优化GPT或者其他语言模型的回答:
Embedding在大模型中的价值, 比如说,我们想要问一个 pre: 问题“A产品的生产日期是多少?”,base: 然后基于A产品的使用说明书进行问答,那么再此之间就会涉及两个embedding,并再向量数据库中进行存储,比如PostgreSQL等等,然后我们会拿问题的embedding去A产品说明书的embedding进行搜索,搜索到与之最相似的embedding返回,然后给到下游的LLM进行回答。
这样的目的就是保证了回答的底线,在一定程度上减少了我们LLM的幻觉现象,从而针对性的回答问题。
2.ollama的介绍
ollama相当于一个用于管理和运行大模型的框架
3 ollama的安装:
- ollama在window下的安装
- docker安装ollama (有两种模式,一种在CPU上可以运行,一种在GPU)
- docker安装ollama2(租用显卡)
https://www.autodl.com/
3.1运行模型qwen
ollama run qwen:7b
3.2嵌入Embedding
嵌入(Embedding)是将数据向量化的一个过程,可以理解为将人类语言转换为大语言模型所需要的计算机语言的一个过程。在我们第二轮测试开始前,首先下载一个嵌入模型:nomic-embed-text 。它可以使我们的Ollama具备将文档向量化的能力。
ollama run nomic-embed-text
3.3LangChain
**1.介绍 :**想象一下,如果你能让聊天机器人不仅仅回答通用问题,还能从你自己的数据库或文件中提取信息,并根据这些信息执行具体操作,比如发邮件,那会是什么情况?Langchain 正是为了实现这一目标而诞生的。
Langchain 是一个开源框架,它允许开发人员将像 GPT-4 这样的大型语言模型与外部的计算和数据源结合起来。目前,它提供了Python和 JavaScript(确切地说是 TypeScript)的软件包。
2.总的来说: 用于提升大型语言模型(LLMs)功能的框架
补:核心组件:
- 首先是
Compents“组件”,为LLMs提供接口封装、模板提示和信息检索索引; - 其次是
Chains“链”,它将不同的组件组合起来解决特定的任务,比如在大量文本中查找信息; - 最后是
Agents“代理”,它们使得LLMs能够与外部环境进行交互,例如通过API请求执行操作。
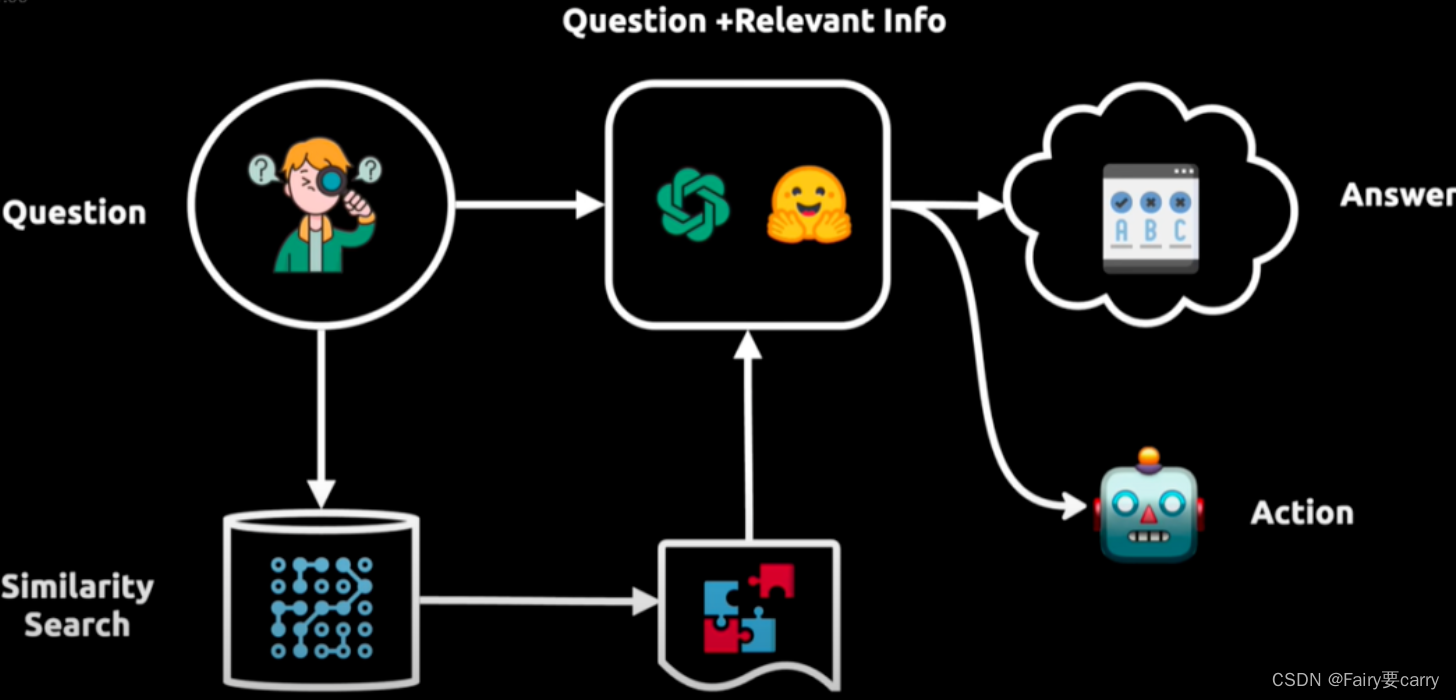
3.工作流程:
提问:用户提出问题。向语言模型查询:问题被转换成向量表示,用于在向量数据库中进行相似性搜索。获取相关信息:从向量数据库中提取相关信息块,并将其输入给语言模型。生成答案或执行操作:语言模型现在拥有了初始问题和相关信息,能够提供答案或执行操作。
4.langChain文档:
https://python.langchain.com/docs/get_started/quickstart
http://docs.autoinfra.cn/docs/integrations/llms/ollama
3.5 实战测试RAG
- 先将文本文件进行提取
# 从 langchain_community 包中导入 TextLoader 类
from langchain_community.document_loaders import TextLoader# 创建 TextLoader 类的实例,指定要加载的文本文件路径为 "./index.md"
loader = TextLoader("./index.md")# load() 方法可能会将指定的文本文件加载到内存中,以便后续进行处理或分析。
loader.load()- 接下来需要一个分词器
Text Splitter
langchain分词器文档
# 1.从 langchain_text_splitters 包中导入 CharacterTextSplitter 类
from langchain_text_splitters import CharacterTextSplitter# 2.使用 CharacterTextSplitter 类创建一个文本分割器实例,指定参数 chunk_size 和 chunk_overlap
# chunk_size: 它表示每个分割后的文本块(chunk)的大小
# chunk_overlap=0 表示相邻文本块之间没有重叠,它们是相互独立的。
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=100, chunk_overlap=0
)# 3.使用创建的文本分割器实例对 state_of_the_union 中的文本进行分割
texts = text_splitter.split_text(state_of_the_union)- 然后需要一个
向量数据库来存储使用nomic-embed-text模型项量化的数据。既然是测试,我们就使用内存型的DocArray InMemorySearch
embeddings = OllamaEmbeddings(model='nomic-embed-text')
vectorstore = DocArrayInMemorySearch.from_documents(doc_splits, embeddings)
总代码:
from langchain_community.document_loaders import TextLoader
from langchain_community import embeddings
from langchain_community.chat_models import ChatOllama
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import DocArrayInMemorySearch
from langchain_community.embeddings import OllamaEmbeddingsmodel_local = ChatOllama(model="qwen:7b")# 1. 读取文件并分词
documents = TextLoader("../../data/三国演义.txt").load()
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500, chunk_overlap=100)
doc_splits = text_splitter.split_documents(documents)# 2. 嵌入并存储
embeddings = OllamaEmbeddings(model='nomic-embed-text')
vectorstore = DocArrayInMemorySearch.from_documents(doc_splits, embeddings)
retriever = vectorstore.as_retriever()# 3. 向模型提问
template = """Answer the question based only on the following context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
chain = ({"context": retriever, "question": RunnablePassthrough()}| prompt| model_local| StrOutputParser()
)
print(chain.invoke("身长七尺,细眼长髯的是谁?"))
![[蓝桥杯练习]通电](https://img-blog.csdnimg.cn/direct/f58214a38e02480b848dd66f4ab6038e.png)