面试,无非都是问下面这些问题(挺多的 - -!),聘请中高级的安卓开发会往深的去问,并且会问一延伸二。以下我先提出几点重点,是面试官基本必问的问题,请一定要去了解!
-
基础知识 – 四大组件(生命周期,使用场景,如何启动)
-
java基础 – 数据结构,线程,mvc框架
-
通信 – 网络连接(HttpClient,HttpUrlConnetion),Socket
-
数据持久化 – SQLite,SharedPreferences,ContentProvider
-
性能优化 – 布局优化,内存优化,电量优化
-
安全 – 数据加密,代码混淆,WebView/Js调用,https
-
UI– 动画
-
其他 – JNI,AIDL,Handler,Intent等
-
开源框架 – Volley,Gilde,RxJava等(简历上写你会的,用过的)
-
拓展 – Android6.0/7.0/8.0特性,kotlin语言,I/O大会
急急忙忙投简历,赶面试,还不如沉淀一两天时间,再过一遍以上内容。想稳妥拿到一个offer,最好能理解实现原理,并且知道使用场景了。不要去背!要去理解!面试官听了一天这些内容是很厌倦的,最好能说出一些自己的见解。
安卓十大必问面试题
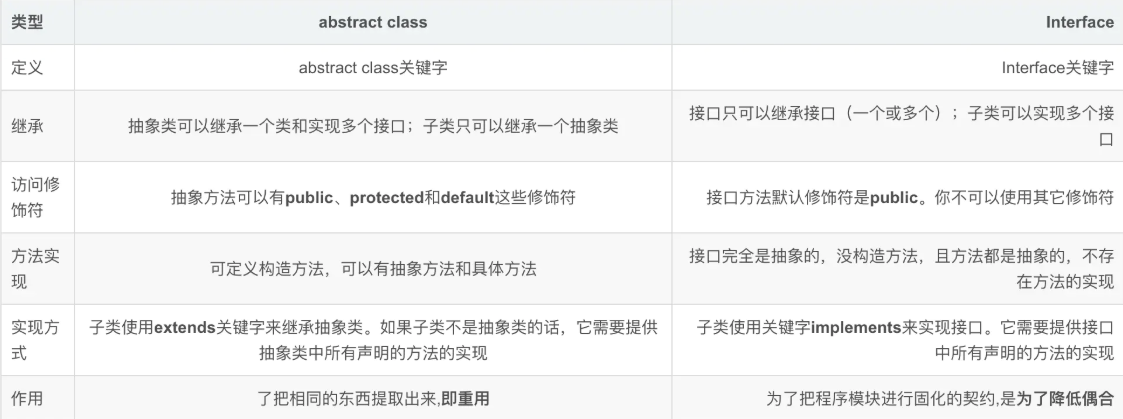
01 Java中提供了抽象类还有接口,开发中如何去选择呢?
这道题想考察什么?
Java是面向对象编程的,抽象是它的一大特征,而体现这个特征的就是抽象类与接口。抽象类与接口某些情况下都能够互相替代,但是如果真的都能够互相替代,那Java为何会设计出抽象与接口的概念?这就需要面试者能够掌握两者的区别。
考察的知识点
OOP(面向对象)编程思想,抽象与接口的区别与应用场景;
考生应该如何回答
抽象类的设计目的,是代码复用;接口的设计目的,是对类的行为进行约束。
- 当需要表示is-a的关系,并且需要代码复用时用抽象类
- 当需要表示has-a的关系,可以使用接口
比如狗具有睡觉和吃饭方法,我们可以使用接口定义:
public interface Dog {public void sleep();public void eat();
}
但是我们发现如果采用接口,就需要让每个派生类都实现一次sleep方法。此时为了完成对sleep方法的复用,我们可以选择采用抽象类来定义:
public abstract class Dog {public void sleep(){//......}public abstract void eat();
}
但是如果我们训练,让狗拥有一项技能——握手,怎么添加这个行为? 将握手方法写入抽象类中,但是这会导致所有的狗都能够握手。
握手是训练出来的,是对狗的一种扩展。所以这时候我们需要单独定义握手这种行为。这种行为是否可以采用抽象类来定义呢?
public abstract Handshake{abstract void doHandshake();
}
如果采用抽象类定义握手,那我们现在需要创建一类能够握手的狗怎么办?
public class HandShakeDog extends Dog //,Handshake
大家都知道在Java中不能多继承,这是因为多继承存在二义性问题。
二义性问题:一个类如果能够继承多个父类,那么如果其中父类A与父类B具有相同的方法,当调用这个方法时会调用哪个父类的方法呢?
所以此时,我们就需要使用接口来定义握手行为:
public interface Handshake{void doHandshake();
}
public class HandShakeDog extends Dog implements Handshake
不是所有的狗都会握手,也不止狗会握手。我们可以同样训练猫,让猫也具备握手的技能,那么猫Cat类,同样能够实现此接口,这就是"has-a"的关系。
抽象类强调从属关系,接口强调功能,除了使用场景的不同之外,在定义中的不同则是:
02 请说一说HashMap,SparseArrary原理,SparseArrary相比HashMap的优点、ConcurrentHashMap如何实现线程安全?
这道题想考察什么?
1、HashMap,SparseArrary基础原理?
2、SparseArrary相比HashMap的优点是什么?
3、ConcurrentHashMap如何实现线程安全?
考察的知识点
HashMap,SparseArrary、ConcurrentHashMap
考生如何回答
HashMap和SparseArray,都是用来存储Key-value类型的数据。
SparseArray和HashMap的区别:
双数组、删除O(1)、二分查找
- 数据结构方面:hashmap用的是链表。sparsearray用的是双数组。
- 性能方面:hashmap是默认16个长度,会自动装箱。如果key是int 的话,hashmap要先封装成Interger。sparseArray的话就就会直接转成int。所以spaseArray用的限制是key是int。数据量小于1k。如果key不是int小于1000的话。可以用Arraymap。
HashMap的基本原理
HashMap内部是使用一个默认容量为16的数组来存储数据的,而数组中每一个元素却又是一个链表的头结点,所以,更准确的来说,HashMap内部存储结构是使用哈希表的拉链结构(数组+链表)。
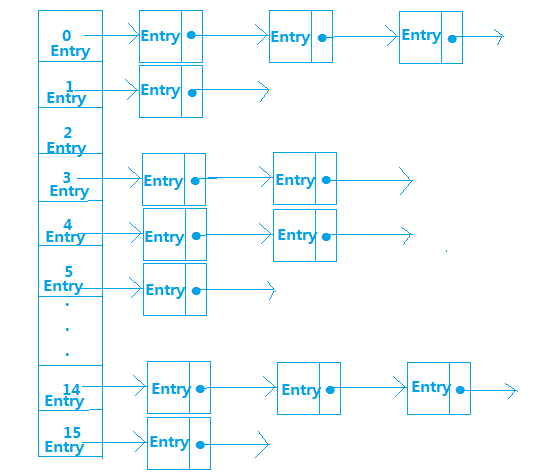
HashMap中默认的存储大小就是一个容量为16的数组,所以当我们创建出一个HashMap对象时,即使里面没有任何元素,也要分别一块内存空间给它,而且,我们再不断的向HashMap里put数据时,当达到一定的容量限制时,HashMap就会自动扩容。
SparseArray的基本原理
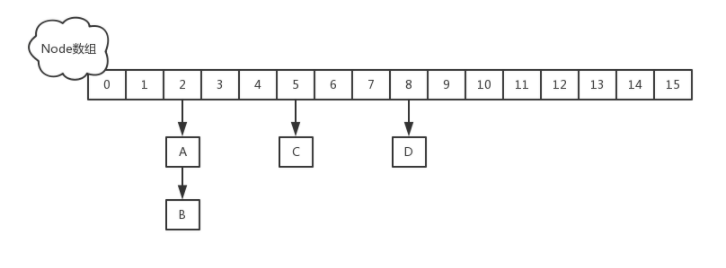
SparseArray比HashMap更省内存,在某些条件下性能更好,主要是因为它避免了对key的自动装箱(int转为Integer类型),它内部则是通过两个数组来进行数据存储的,一个存储key,另外一个存储value,为了优化性能,它内部对数据还采取了压缩的方式来表示稀疏数组的数据,从而节约内存空间,我们从源码中可以看到key和value分别是用数组表示:
private int[] mKeys;
private Object[] mValues;
我们可以看到,SparseArray只能存储key为int类型的数据,同时,SparseArray在存储和读取数据时候,使用的是二分查找法,
public void put(int key, E value) {int i = ContainerHelpers.binarySearch(mKeys, mSize, key);...}public E get(int key, E valueIfKeyNotFound) {int i = ContainerHelpers.binarySearch(mKeys, mSize, key);...}
也就是在put添加数据的时候,会使用二分查找法和之前的key比较当前我们添加的元素的key的大小,然后按照从小到大的顺序排列好,所以,SparseArray存储的元素都是按元素的key值从小到大排列好的。而在获取数据的时候,也是使用二分查找法判断元素的位置,所以,在获取数据的时候非常快,比HashMap快的多,因为HashMap获取数据是通过遍历Entry[]数组来得到对应的元素。
添加数据
public void put(int key, E value)
删除数据
public void remove(int key)
获取数据
public E get(int key)public E get(int key, E valueIfKeyNotFound)
虽说SparseArray性能比较好,但是由于其添加、查找、删除数据都需要先进行一次二分查找,所以在数据量大的情况下性能并不明显,将降低至少50%。满足下面两个条件我们可以使用SparseArray代替HashMap:
- 数据量不大,最好在千级以内
- key必须为int类型,这中情况下的HashMap可以用SparseArray代替:
ConcurrentHashMap基本原理
-
JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry。
-
JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了。
-
JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表。
-
03 请你描述TCP三次握手与四次挥手的过程与意义
这道题想考察什么?
这个问题属于网络体系中的基础理论知识,对于这种类型的问题如果没有一个清晰的认识,那会让你在掌握一些“高大上“技术的时没有支撑,也难以把整体框架理顺。比如Http、RTSP 、RTMP等被广泛运用的应用层协议都是基于TCP来实现的。所以被问到这个问题并不稀奇。
考察的知识点
网络的基础知识
考生如何回答
TCP/IP协议定义了计算机在网络中如何发送数据、数据格式如何定义、发出消息后在网络中如何寻址找到目标计算机,最后目标计算机又如何检验收到消息的正确性、对数据拆解最后得到消息内容的一套处理标准。
有了这些标准后生产提供TCP/IP服务的软件商家就有了一套统一的规范,只要遵循这个规范去实现自己的软件功能。
三次握手
在进行业务通信前,必须建立好连接,而TCP/IP连接的建立需要经过三次握手的过程。其过程如下图:
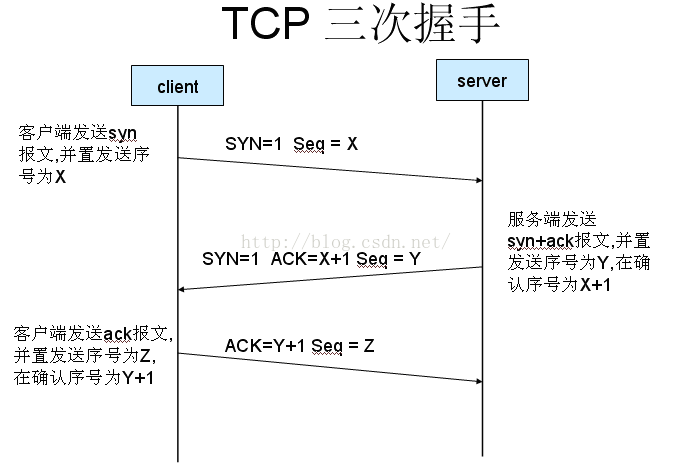
- 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
为什么要三次握手?
全双工通信
三次握手是确定通信双方通讯线路是全双工的最小次数,全双工通信是指:通信的双方可以同时发送和接收信息 。
正如双方电话通话:
A:喂,能听到吗?
B:可以
此时如果A没有反馈,B无法确定A是否能够接收数据。
保证可靠性
另外TCP是可靠传输协议,保证通信的可靠性的手段中包含序列号与确认应答机制。
- 序列号:TCP传输时将每个字节的数据都进行了编号,保证数据的有序性与可靠性(当接收到的数据总少了某个序号的数据时,能马上知道 );
- 确认应答:TCP传输的过程中,每次接收方收到数据后,都会对传输方进行确认应答。也就是发送ACK报文。这个ACK报文当中带有对应的确认序列号,告诉发送方,接收到了哪些数据,下一次的数据从哪里发。
而三次握手的同时也能确定通信双方的初始序列号。
- C --> S SYN my sequence number is X
- S <-- C ACK your sequence number is X my sequence number is Y
- C --> S ACK your sequence number is Y
如果C 未确认收到 B 的。也就是说,只有 C 发送给 S 的包都是可靠的, 而 S 发送给 C 的则不是,所以这不是可靠的连接。
避免资源浪费
除此之外,第一次握手:客户端发送连接请求消息到服务端,服务端收到信息后需要进行第二次握手:应答告知客户端已经接收连接请求。而服务端发送出去的应答消息,需要等客户端第三次握手响应后,才能确定此次连接为有效连接。
若客户端发出去的第一个连接请求由于某些原因在网络节点中滞留了导致延迟,直到客户端放弃连接后的某个时间点才到达服务端,这是一个早已失效的报文,但是此时服务端仍然认为这是客户端的建立连接请求第一次握手,于是服务端第二次握手回应了客户端。如果没有第三次握手,那么到这里,连接就建立了,但是此时客户端并没有任何数据要发送,会让服务端空等,造成资源浪费。
四次挥手
在完成数据交互之后,如果选择关闭连接,以回收资源,则完成四次挥手来进行“和平分手”。过程如下图:
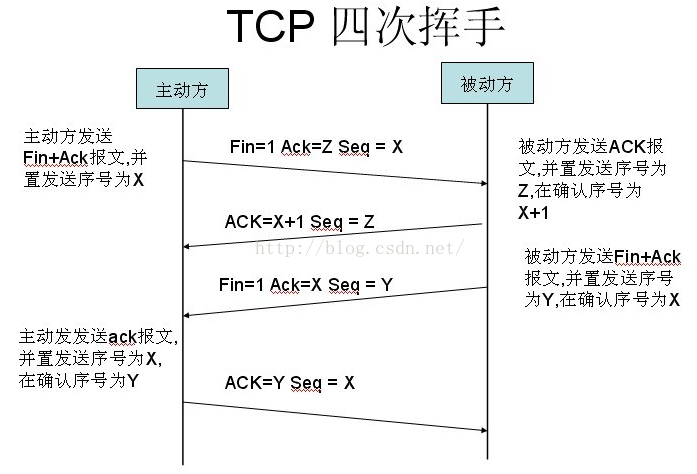
- 第一次挥手:主动关闭方发送第一个包,其中FIN标志位为1,发送顺序号seq为X。
- 第二次挥手:被动关闭方收到FIN包后发送第二个包,其中发送顺序号seq为Z,接收顺序号ack为X+1。
- 第三次挥手:被动关闭方再发送第三个包,其中FIN标志位为1,发送顺序号seq为Y,接收顺序号ack为X。
- 第四次挥手:主动关闭方发送第四个包,其中发送顺序号为X,接收顺序号为Y。至此,完成四次挥手。
为什么断开连接需要四次挥手?
三次握手是因为建立连接时,ACK和SYN可以放在一个报文里来发送。而关闭连接时,被动关闭方可能还需要发送一些数据后,再发送FIN报文表示同意现在可以关闭连接了,所以它这里的ACK报文和FIN报文多数情况下都是分开发送的。因此断开连接需要4次。
04 Kotlin语言的run高阶函数的原理是什么?
这道题想考察什么?
- 是否了解Kotlin语言的run高阶函数的原理是什么与真实场景使用,是否熟悉Kotlin语言的run高阶函数的原理是什么本质?
考察的知识点
- Kotlin语言的run高阶函数的原理是什么的概念在项目中使用与基本知识
考生应该如何回答
1.你工作这么些年,Kotlin语言提供的高阶run函数一般用的很频繁吧,run的原理是什么?
答:
run在Kotlin语法中使用端的感受:
1.在使用的时候,任何的类型,都可以.run出来使用,这是为什么呢? 因为标准run内置函数内部对泛型进行run函数扩展,意味着所有的类型都等于泛型,所以任何地方都是可以使用run函数的。
2.所有类型.run{} 其实是一个匿名的Lambda表达式,Lambda表达式的特点是,最后一行会自动被认为是返回值类型,例如在表达式返回Boolean,那么当前的run函数就是Boolean类型,例如在表达式返回Int类型,那么当前的run函数就是Int类型,以此类推。
fun main() {val r1 : Int = "Derry".run {truelength}println(r1)val r2 : String = 123.run {999"【${it}】"}println(r2)
}
根据上面分析的两点使用感受,来分析他的原理:
1.inline : 是因为函数有lambda表达式,属于高阶函数,高阶函数规范来说要加inline
2.<T, R> T.run : T代表是要为T而扩展出一个函数名run(任何类型都可以 万能类型.run), R代表是Lambda表达式最后一行返回的类型
3.block: T.() -> R : Lambda表达式名称block 输入参数是T本身 输出参数是R 也就是表达式最后一行返回推断的类型
4.: R { : R代表是Lambda表达式最后一行返回的类型,若表达式返回类型是Boolean, 那么这整个run函数的返回类型就是Boolean
5.T.() 是让lambda表达式里面持有了this(run函数), (T) 是让lambda表达式里面持有了it(let函数)
/*
1.inline : 是因为函数有lambda表达式,属于高阶函数,高阶函数规范来说要加inline2.<T, R> T.run : T代表是要为T而扩展出一个函数名run(任何类型都可以 万能类型.run), R代表是Lambda表达式最后一行返回的类型3.block: T.() -> R : Lambda表达式名称block 输入参数是T本身 输出参数是R 也就是表达式最后一行返回推断的类型4.: R { : R代表是Lambda表达式最后一行返回的类型,若表达式返回类型是Boolean, 那么这整个run函数的返回类型就是Boolean5.T.() 是让lambda表达式里面持有了this(run函数), (T) 是让lambda表达式里面持有了it(let函数)
*/
public inline fun <T, R> T.run(block: T.() -> R): R {println("你${this}.run在${System.currentTimeMillis()}这个时间点调用了我")/*contract {callsInPlace(block, InvocationKind.EXACTLY_ONCE)}*/// 调用Lambda表达式// 输入参数this == T == "Derry" / 123,// 输出参数:用户返回String类型,就全部是返回String类型return block()
}
总结:Kotlin内置标准run函数,运用了 高阶函数特性与Lambda,控制环节交给用户完成,用户在自己的Lambda表达式中,若返回Boolean,整个run函数 与 Lambda返回 都全部是Boolean
为了保证所有的类型都能正常使用run,给泛型增加了扩展函数run,所以所有的地方都可以使用run函数。
05 Android中多进程通信的方式有哪些?
这道题想考察什么?
对计算机中进程的了解,为了完成跨进程通信需要解决的问题以及现有的跨进程通信方式大致实现原理与区别
考察的知识点
操作系统内存、进程与通信
考生应该如何回答
总的来说,进程间通信方案有很多他们分别是:管道,信号,信号量,内存共享,socket,binder,消息队列,但是使用最多的还是binder,尤其是用户空间的跨进程通信,基本大多采用的是binder。
进程隔离
操作系统有虚拟内存与物理内存的概念。物理内存指通过物理内存条而获得的内存空间,而虚拟内存则是计算机系统内存管理的一种技术,虚拟内存并非真正的内存,而是通过虚拟映射的手段让每个应用进程认为它拥有连续的可用的内存。在使用了虚拟存储器的情况下, 通过MMU(负责处理CPU的内存管理的计算单元)完成虚拟地址到物理地址的转换。
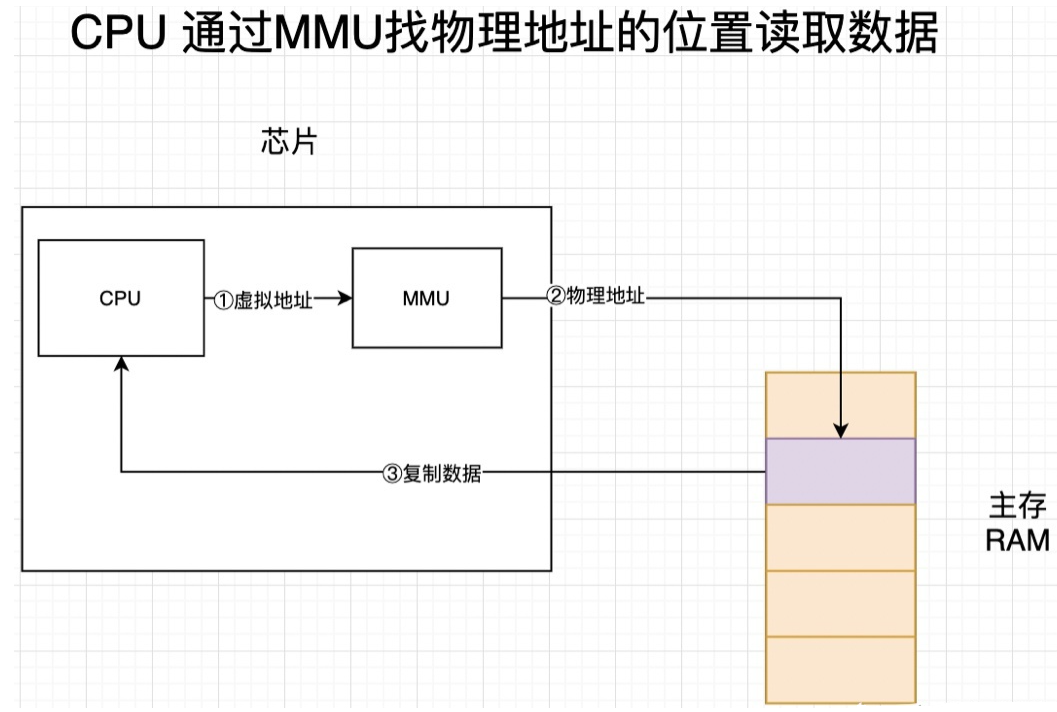
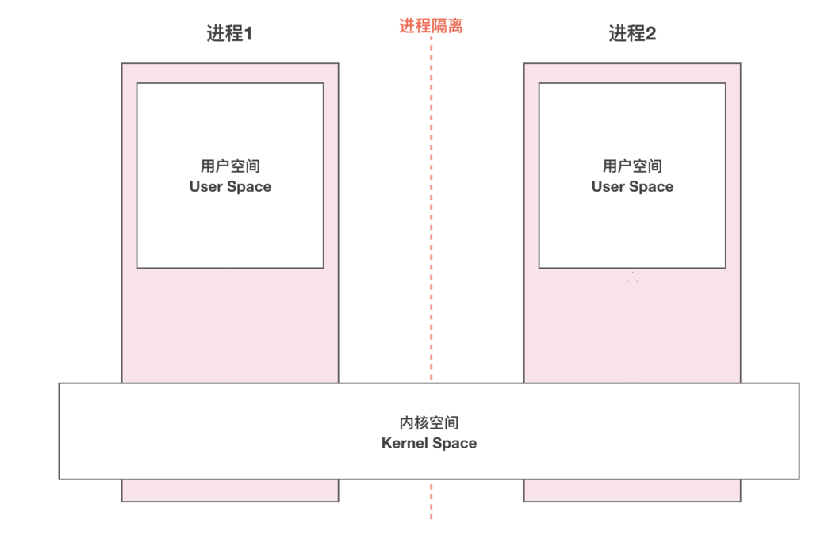
程序使用的虚拟内存被操作系统划分成两块:用户空间和内核空间。用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方,内核空间由所有进程共享。为了安全,内核空间与用户空间是隔离的,这样即使用户的程序崩溃了,内核也不受影响。同样为了安全,不同进程的各自的用户空间也是隔离的,这样就避免了进程间相互操作数据的现象发生,从而引起各自的安全问题。不同进程基于各自的虚拟地址不同,从逻辑上来实现彼此间的隔离。
IPC通信
为了能使不同的进程互相访问资源并进行协调工作,需要在不同进程之间完成通信。而通过进程隔离可知不同进程之间无法直接完成通信的工作。此时就需要特殊的方式来实现:IPC(Inter-Process Communication )即进程间通信。不同进程存在进程隔离,但是内核空间被所有进程共享,因此绝大多数的IPC机制就利用这个特点来实现通信的需求。因为Android是在Linux内核基础之上运行,因此Linux中存在的IPC机制在Android中基本都能使用。
管道
管道是UNIX中最古老的进程间通信形式,它实际上是由内核管理的一个固定大小的缓冲区。管道的一端连接一个进程的输出,这个进程会向管道中放入信息。管道的另一端连接一个进程的输入,这个进程取出被放入管道的信息。
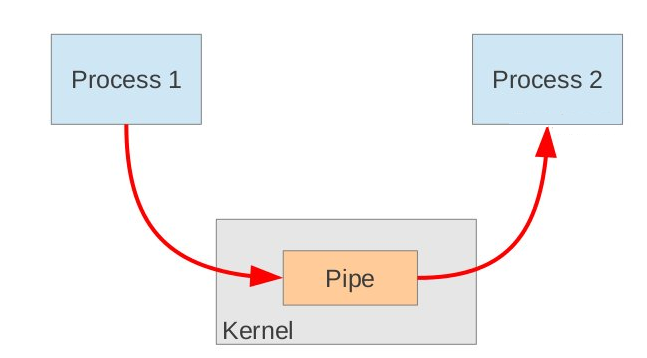
可以通过pipe创建一个管道:
//匿名管道(PIPE)
#include <unistd.h>
int pipe (int fd[2]); //创建pipe
ssize_t write(int fd, const void *buf, size_t count); //写数据
ssize_t read(int fd, void *buf, size_t count); //读数据
pipe创建的是匿名管道,它存在以下限制:
1、大小限制(一般为4k)
2、半双工(同一个时刻只数据只能向一个方向流动,需要双方通信时,需要建立两个管道 )
3、只支持父子和兄弟进程之间的通信
另外还有FIFO实名管道,支持双向的数据通信,建立命名管道时给它指定一个名字,任何进程都可以通过该名字打开管道的另一端,但是要同时和多个进程通信它就力不从心了。需要了解更多关于管道机制的内容可以在腾讯课堂搜索享学课堂。
信号
信号主要用于用于通知接收进程某个事件的发生。信号的原理是在软件层次上对中断机制的一种模拟,一个进程收到一个信号与处理器收到一个中断请求是一样的。
信号是一种异步通信机制,一个进程不必通过任何操作来等待信号的到达,事实上,进程也不知道信号到底什么时候到达。也就是说信号接收函数不需要一直阻塞等待信号的到达。 进程可以通过sigaction注册接收的信号,就会执行响应函数,如果没有地方注册这个信号,该信号就会被忽略。
int sigaction(int signum,const struct sigaction *act ,struct sigaction *oldact);
//根据参数signum指定的信号编号来设置该信号的处理函数。
//参数signum可以指定SIGKILL和SIGSTOP以外的所有信号。
在Android中,如果程序出现ANR问题会发出:SIGNALQUIT 信号,应用程序可注册此信号的响应实现监听ANR,爱奇艺xCrash,友盟+ U-APM、腾讯Matrix都实现了该方式。可以在腾讯课堂搜索享学课堂了解更多ANR监控相关内容。
信号量
信号量实际上可以看成是一个计数器,用来控制多个进程对共享资源的访问。它不以传送数据为主要目的,主要作为进程间以及同一进程内不同线程之间的同步手段。
信号量会有初值(>0),每当有进程申请使用信号量,通过一个P操作来对信号量进行-1操作,当计数器减到0的时候就说明没有资源了,其他进程要想访问就必须等待,当该进程执行完这段工作(我们称之为临界区)之后,就会执行V操作来对信号量进行+1操作。
共享内存
通过进程隔离可知,不同进程基于各自的虚拟地址不同,从逻辑上来实现彼此间的隔离。 而共享内存则是让不同进程可以将同一段物理内存连接到他们自己的地址空间中,完成连接的进程都可以访问这块共享内存中的数据。
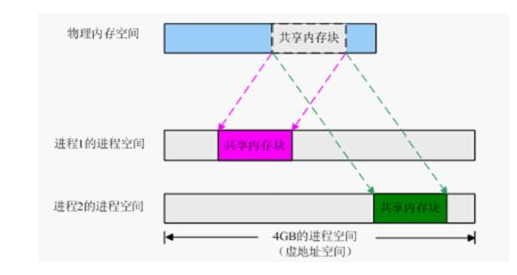
由于多个进程共享同一块内存区域,所以通常需要用其他的机制来同步对共享内存的访问,如信号量 。而在Android中提供了独特的匿名共享内存Ashmem(Anonymous Shared Memory)。Android的匿名共享内存基于 Linux的共享内存,都是在临时文件系统上创建虚拟文件,再映射到不同的进程。 它可以让多个进程操作同一块内存区域,并且除了物理内存限制,没有其他大小限制。相对于 Linux 的共享内存,Ashmem 对内存的管理更加精细化,并且添加了互斥锁。
在开发中,可以借助Java中的 MemoryFile 使用匿名共享内存,它封装了 native 代码。 Java 层使用匿名共享内存的步骤一般为:
1. 通过 MemoryFile 开辟内存空间,获得ParcelFileDescriptor;
MemoryFile memoryFile = new MemoryFile("test", 1024);
Method method = MemoryFile.class.getDeclaredMethod("getFileDescriptor");
FileDescriptor des = (FileDescriptor) method.invoke(memoryFile);
ParcelFileDescriptor pfd = ParcelFileDescriptor.dup(des);
- 将 ParcelFileDescriptor 传递给其他进程;
- A进程往共享内存写入数据;
memoryFile.getOutputStream().write(new byte[]{1, 2, 3, 4, 5});
- B进程从共享内存读取数据。
ParcelFileDescriptor parcelFileDescriptor;
FileDescriptor descriptor = parcelFileDescriptor.getFileDescriptor();
FileInputStream fileInputStream = new FileInputStream(descriptor);
fileInputStream.read(content);
在第二步中一般的利用Binder机制进行FD的传输,传输完成后,就可以直接借助FD完成跨进程数据通信,而且没有内存大小的限制。因此当需要跨进程进行大数据的传递时,可以借助匿名共享内存完成!
在Android中视图数据与SurfaceFlinger的通信、腾讯MMKV、Facebook Fresco等等技术都有利用到匿名共享内存。
消息队列
消息队列是一个消息的链表,存放在内核中并由消息队列标识符标识。它克服了Linux早期IPC机制的很多缺点,比如消息队列具有异步能力,又克服了具有同样能力的信号承载信息量少的问题;具有数据传输能力,又克服了管道只能承载无格式字节流以及缓冲区大小受限的问题。
但是缺点是比信号和管道都要更加重量,在内核中会使用更多内存,并且消息队列能传输的数据也有限制,一般上限为两页 16kb。
int msgget(key_t, key, int msgflg); //创建和访问消息队列
int msgsend(int msgid, const void *msg_ptr, size_t msg_sz, int msgflg); //发送消息
int msgrcv(int msgid, void *msg_ptr, size_t msg_st, long int msgtype, int msgflg); //获取消息
受限于性能,数据量等问题的限制,Android系统没有直接使用Linux消息队列来进行IPC的场景,但是有大量的场景都利用了消息队列的特性来设计通信方案,比如进行线程间通信的Handler,就是一个消息队列。
socket
socket 原本是为网络通讯设计的,但后来在 socket 的框架上发展出一种 IPC 机制,就是 UNIX domain socket。虽然网络 socket 也可用于同一台主机的进程间通讯(通过 loopback 地址 127.0.0.1),但是 UNIX domain socket 用于 IPC 更有效率:不需要经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等,只是将应用层数据从一个进程拷贝到另一个进程。 在Android系统中,Zygote进程就是通过LocalSocket(UNIX domain socket)接收启动应用进程的通知。
socket(AF_INET, SOCK_STREAM, 0); // 对应java Socket
socket(AF_UNIX, SOCK_STREAM, 0);// 对应java LocalSocket
Binder
Android Binder源于Palm的OpenBinder,在Android中Binder更多用在system_server进程与上层App层的IPC交互。 在Android中Intent、ContentProvider、Messager、Broadcast、AIDL等等都是基于Binder机制完成的跨进程通信。
总结
Android是在Linux内核基础之上运行,因此Linux中存在的IPC机制在Android中基本都能使用,如:
- **管道:**在创建时分配一个page大小的内存,缓存区大小比较有限;
- 信号: 不适用于信息交换,更适用于进程中断控制,比如非法内存访问,杀死某个进程等;
- 信号量:常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- 共享内存:无须复制,共享缓冲区直接付附加到进程虚拟地址空间,速度快;但进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决;
- 消息队列:信息复制两次,额外的CPU消耗;不合适频繁或信息量大的通信;
- 套接字:作为更通用的接口,传输效率低;
为什么Android选择Binder作为应用程序中主要的IPC机制?
Binder基于C/S架构,进行跨进程通信数据拷贝只需要一次,而管道、消息队列、Socket都需要2次,共享内存方式一次内存拷贝都不需要;从性能角度看,Binder性能虽然比管道等方式好,但是不如共享内存。
但是传统Linux IPC的接收方无法获得对方进程可靠的UID/PID,只能由使用者在传递的数据包里填入UID/PID,伪造身份非常简单;而Binder不同,可靠的身份标记只有由IPC机制本身在内核中添加,binder就是这么做的,不由用户应用程序控制,直接在内核向数据中添加了进程身份标记。
因此综合考虑,Binder更加适合system_server进程与上层App层的IPC交互。
06 View绘制流程与自定义View注意点
07 Acitvity的生命周期,如何摧毁一个Activity?
08 内存优化,内存抖动和内存泄漏。
09 组件化在项目中的意义
10 谈谈Glide框架的缓存机制设计
每个问题的解析都较为长,为了大家的更好阅读以及查漏补缺,这里将所有面试题整理汇总成了PDF文档

每一章节都是站在企业考察思维出发,作为招聘者角度回答。从考察问题延展到考察知识点,再到如何优雅回答一面俱全,可以说是求职面试的必备宝典,每一部分都有上百页内容,需要的小伙伴直接扫码免费获取。
**