目录
- 操作过程中不断遇到新的问题,思路的转换过程
- 背景
- 第一天 操作过程
- 第二天
- 正则表达式是个好东西
- 第三天
- 第四天
- 第五天
- 遇到的小问题
操作过程中不断遇到新的问题,思路的转换过程
背景
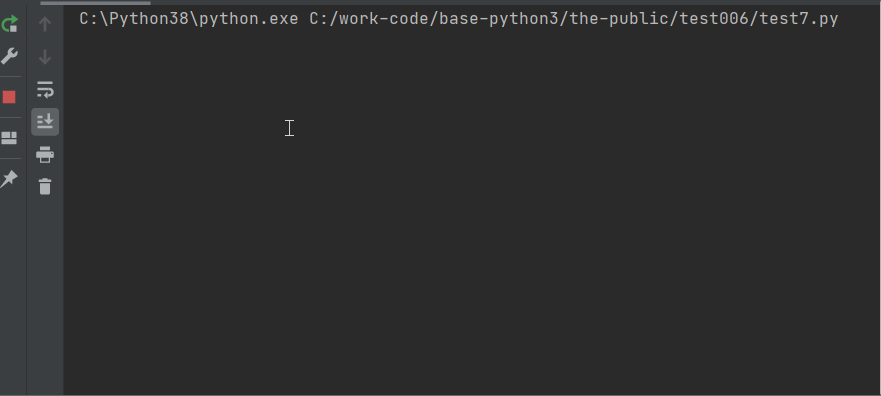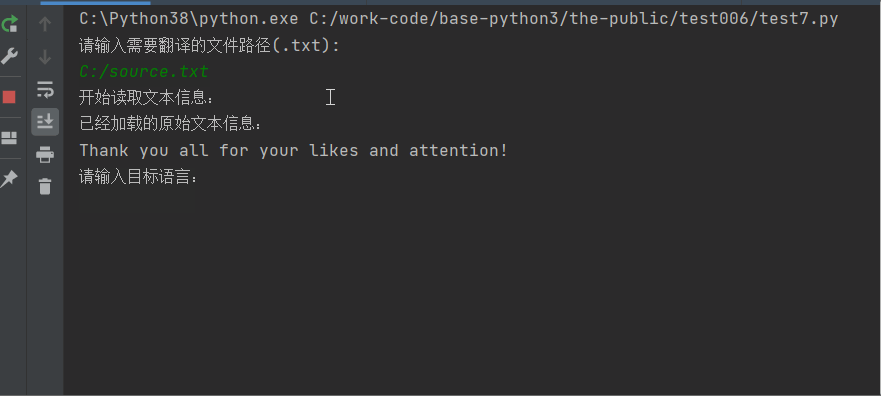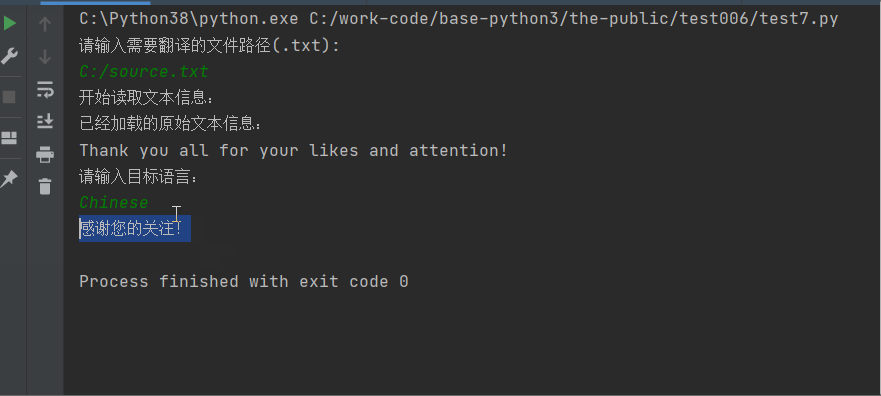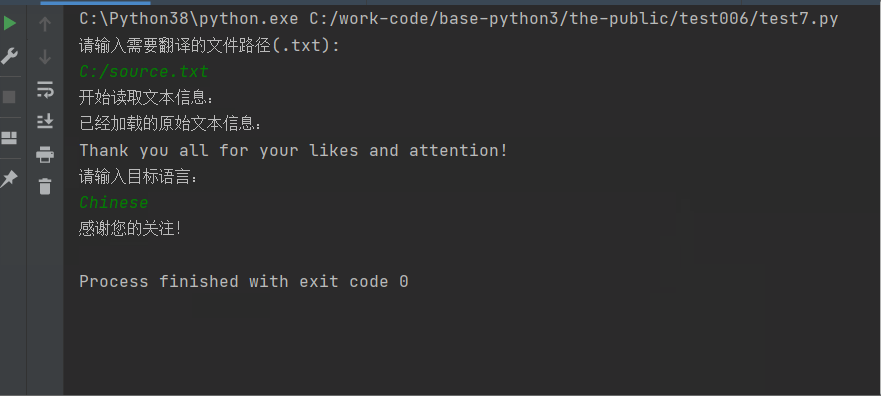
今天接到一个任务,需要将EXCEL文件中的中文翻译成英文,由于表格内容非常大,我想着 这要是手动翻译,三天啥都不用干了,就翻译这个吧
于是有了用python批量翻译的想法
目前的思路是,将excel中每个单元的内容拿出来,放在一个列表中,然后用翻译软件翻译再批量存入新的表格(应该可以用API接口,将所有单元内容依次拿出、翻译、存入,这个还没学会。。。)
参考文章:pandas操作
第一天 操作过程
1.发现一个问题,google翻译有字数上限。。。一次最多5000字符
于是想到分几步粘贴,需要翻译的表格差不多两万多。自己多动几次手就好了。
好,终于翻译完了,开始运行

新问题来了,谷歌在翻译的大段字符的时候,把有的引号 ‘’ 给吞了,这就造成了列表中间的元素发生了紊乱,这个就比较麻烦了,刚开始尝试手动修改,把吞掉的引号给他补上,手动操作5分钟之后,我放弃了,这尼玛也太坑了。就在我准备砸电脑放弃的时候,突然灵光一闪,想到可以用正则表达式批量计算啊,简直不要太机智
import pandas as pdpath = r'C:\Users\hao\Desktop\批量翻译\源文件\两广-住宅调研问卷.xlsx'
df = pd.read_excel(path, header=None)
contents = []
for i in range(len(df[0])):for j in range(len(df.iloc[0])):content = df.iloc[i,j]print('第{}行第{}列元素:%s'.format(i, j)%content)contents.append(content)
print('行和列的长度:%d,%d'%(len(df[0]), len(df.iloc[0])))
print(contents)
第二天
正则表达式是个好东西
正则表达式常见操作
先导入所有翻译好的数据

在编译器的提示下,可以很明显地看出出现错误的地方(白色就代表出错了),英文里面所有格 's中会带来引号,与列表中的引号发生了冲突,于是想到用正则把其他的引号改为双引号,
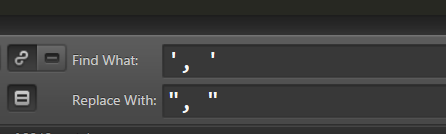
然后把开头和结尾的单引号也改为双引号,但依然提示错误。。。发现是由于数字不是字符串没有引号,没有被正则匹配上,于是又回去修改代码,把int和float型加上引号,再接着运行,发现还是有错误,中间有些空白字符被吞了,就导致后面的整个秩序对不上,导入到表格中发生错位。。。最后就放弃用正则修改了。。。
第三天
既然批量提取,翻译之后再批量导入的方法行不通,就只能试一试之前想到的API了,提取一个,翻译一个,这样就不会错位了,说干就干,百度了一个方法,代码如下
#利用translate模块,但有两个缺点,一个是限制翻译数量,每天就能翻译1000个词
#再一个是只能由英文翻译成中文,比较瓜
import pandas as pd
from translate import Translator
path = r'C:\Users\hao\Desktop\批量翻译\源文件\test_db1.xlsx'
df = pd.read_excel(path,