用itchat爬取微信好友基本信息
Python有一个好玩的软件包itchat,提供了一个微信api接口,借此可以爬取朋友圈的一些基本信息,下面我们一起来玩玩吧。
import itchat
import numpy as np
import pandas as pd
from collections import defaultdict
import re
import jieba
import os
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
import PIL.Image as Image
一、登陆微信:
itchat.login()二、好友基本信息:
friends = itchat.get_friends(update=True)friend[0]是自己,下面为每一个人创建一个文件夹存放分析的结果。
NickName = friends[0].NickName #获取自己的昵称
os.mkdir(NickName) #为自己创建一个文件夹file = '\%s' %NickName #刚刚创建的那个文件夹的相对路径
cp = os.getcwd() #当前路径
path = os.path.join(cp+file) #刚刚创建的那个文件夹的绝对路径
os.chdir(path) #切换路径
- ### 好友数量
number_of_friends = len(friends)pandas可以把据处理成 DataFrame,这极大方便了后续分析。
df_friends = pd.DataFrame(friends)- ### 分析好友性别
男性为1;女性为2;未知为0;
自定义一个计数函数:
def get_count(Sequence):counts = defaultdict(int) #初始化一个字典for x in Sex:counts[x] += 1return counts
获取性别信息:
Sex = df_friends.Sex
Sex_count = get_count(Sex )pandas为Series提供了一个value_counts()方法,可以更方便统计各项出现的次数:
Sex_count = Sex.value_counts() #defaultdict(int, {0: 31, 1: 292, 2: 245})画图:
Sex_count.plot(kind = 'bar')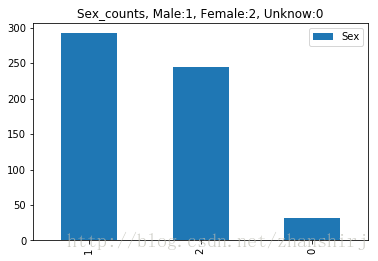
好友都来自什么地方
先来看Province
Province = df_friends.ProvinceProvince_count = Province.value_counts()Province_count = Province_count[Province_count.index!=''] #有一些好友地理信息为空,过滤掉这一部分人。
我的好于基本上来自北京和四川,这是显然的四川人在北京读书。
再来看City
City = df_friends.City #[(df_friends.Province=='北京') | (df_friends.Province=='四川')]City_count = City.value_counts()City_count = City_count[City_count.index!='']- ###把如上基本信息写入到本地文件
file_name_all = NickName+'_basic_inf.txt' write_file = open(file_name_all,'w')write_file.write('你共有%d个好友,其中有%d个男生,%d个女生,%d未显示性别。\n\n' %(number_of_friends, Sex_count[1], Sex_count[2], Sex_count[0])+'你的朋友主要来自省份:%s(%d)、%s(%d)和%s(%d)。\n\n' %(Province_count.index[0],Province_count[0],Province_count.index[1],Province_count[1],Province_count.index[2],Province_count[2])+'主要来自这些城市:%s(%d)、%s(%d)、%s(%d)、%s(%d)、%s(%d)和%s(%d)。'%(City_count.index[0],City_count[0],City_count.index[1],City_count[1],City_count.index[2],City_count[2],City_count.index[3],City_count[3],City_count.index[4],City_count[4],City_count.index[5],City_count[5]))write_file.close()
效果图:

二、分析好友签名:
- ### 提取并清理签名,得到语料库。
Signatures = df_friends.Signatureregex1 = re.compile('<span.*?</span>') #匹配表情regex2 = re.compile('\s{2,}')#匹配两个以上占位符。Signatures = [regex2.sub(' ',regex1.sub('',signature,re.S)) for signature in Signatures] #用一个空格替换表情和多个空格。Signatures = [signature for signature in Signatures if len(signature)>0] #去除空字符串
text = ' '.join(Signatures)file_name = NickName+'_wechat_signatures.txt'with open(file_name,'w',encoding='utf-8') as f:f.write(text)
f.close()
- ###jieba 分词分析语料库
wordlist = jieba.cut(text, cut_all=True)word_space_split = ' '.join(wordlist)
- ##画图
coloring = np.array(Image.open("F:/Program/Python/Practice/wechat/wechat.jpg")) #词云的背景和颜色。这张图片在本地。my_wordcloud = WordCloud(background_color="white", max_words=2000,mask=coloring, max_font_size=60, random_state=42, scale=2,font_path="C:\Windows\Fonts\msyhl.ttc").generate(word_space_split) #生成词云。font_path="C:\Windows\Fonts\msyhl.ttc"指定字体,有些字不能解析中文,这种情况下会出现乱码。file_name_p = NickName+'.jpg'my_wordcloud.to_file(file_name_p) #保存图片
微信好友签名关键字: