几个使用Stable Diffusion XL 1.0生成的图像示例。
新的SDXL 1.0发布允许在本地计算机上运行的高分辨率人工智能图像合成。
周三,Stability AI发布了其下一代开源权重人工智能图像合成模型Stable Diffusion XL 1.0(SDXL)。它可以根据文本描述生成新颖的图像,并生成比之前版本的Stable Diffusion更多细节和更高分辨率的图像。
就像稳定扩散1.4版一样,在去年8月份发布开源版本后引起轰动一样,任何具备适当硬件和技术知识的人都可以免费下载SDXL文件并在自己的机器上本地运行该模型。
本地操作意味着不需要支付访问SDXL模型的费用,几乎没有审查问题,未来业余爱好者可以微调权重文件(包含使模型功能的中性网络数据),以生成特定类型的图像。


一位Reddit用户名为masslevel的用户使用Stable Diffusion XL的beta版本生成的一张图像。
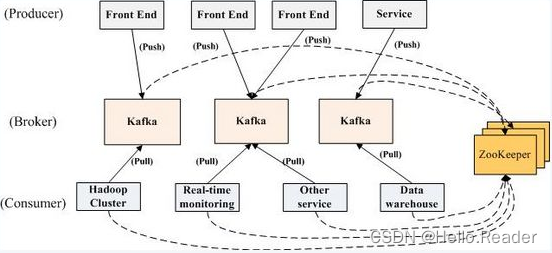
升级引擎
与其他潜在扩散图像生成器一样,SDXL从随机噪声开始,并根据文本提示的指导“识别”噪声中的图像,并逐步完善图像。但根据Stability的说法,SDXL利用了一个“三倍大的UNet骨干”,比早期的Stable Diffusion模型具有更多的模型参数来完成其技巧。简而言之,这意味着SDXL架构会进行更多的处理来得到最终的图像。
为了生成图像,SDXL利用了一个“专家组合”架构,指导了一个潜在扩散过程。专家组合是指一种方法,其中一个初始单一模型被训练,然后分成专门为不同阶段的生成过程训练的专业模型,从而提高图像质量。在这种情况下,有一个基本的SDXL模型和一个可选的“精炼器”模型,可以在初始生成后运行,使图像看起来更好。

Table Diffusion XL 包含两个可组合的文本编码器。在 Xander Steenbrugge 的这个例子中,大象和章鱼无缝地组合成一个概念。
值得注意的是,SDXL还使用了两种不同的文本编码器来理解书面提示,从而帮助确定模型权重中编码的相关图像。用户可以为每个编码器提供不同的提示,从而产生新颖、高质量的概念组合。
然后,图像细节和尺寸方面有所改进。 虽然 Stable Diffusion 1.5 是在 512×512 像素图像上进行训练的(使之成为最佳的生成图像大小,但缺少小型特征的细节),但 Stable Diffusion 2.x 将其增加到了 768×768。 现在,Stability AI 建议使用 Stable Diffusion XL 生成 1024×1024 像素图像,比 SD 1.5 生成的大小相似的图片具有更高的细节。
本地控制,开放的理念
我们下载了Stable Diffusion XL 1.0模型,并在Windows机器上使用12GB VRAM的RTX 3060 GPU本地运行它。像ComfyUI和AUTOMATIC1111的Stable Diffusion Web UI这样的接口使得这个过程比去年Stable Diffusion首次推出时更加用户友好,但仍需要一些技术调整才能使其正常工作。如果您想尝试它,本教程可以给您指明方向。
总的来说,我们看到了具有梦幻般质量的图像生成,更多地倾向于商业AI图像生成器Midjourney的风格。正如上面提到的那样,SDXL通过提供更大的图像尺寸和更多的细节而闪耀。它似乎也会更忠实地遵循提示,尽管这是可以争议的。
其他值得注意的改进包括比以前的SD模型更好地渲染手部,并且它更擅长在图像中渲染文本。但是,与早期模型一样,生成高质量的图像仍然像拉一个老虎机的杆子一样,希望得到好的结果。专家们发现,仔细提示(以及大量的试错)是获得更好结果的关键。

使用SDXL 1.0生成的“人手”AI图像
在消费级硬件上本地运行时,SDXL也存在缺点,例如比Stable Diffusion 1.x 和 2.x需要更高的内存要求和更慢的生成时间。(在我们的测试平台上,以20个步骤,欧拉祖先,CFG 8渲染一个1024x1024的图像,SD 1.5花费23.3秒,而SDXL 1.0花费了26.4秒。所得到的SDXL图像比SD 1.5图像少了一些重复元素。)
到目前为止,SD模型制作爱好者似乎对缺乏精细调校的LoRA感到遗憾,这些LoRA适用于SD 1.5风格的模型,可以提升美感(比如3D渲染风格)或某些场景的更详细的背景,但他们预计社区很快就会填补这些空白。
在稳定扩散中,社区是关键,因为该模型可以在本地运行而不需要监督。这对于利用该软件制作有趣艺术品的业余合成器群体来说是一种福利。但这也意味着该软件可以用来创建深度伪造、色情以及虚假信息。对于Stability AI来说,一些负面方面和开放性之间的权衡是值得的。
在本月早些时候发布在arXiv上的SDXL技术报告中,Stability抱怨称,“黑匣子”模型(如OpenAI的DALL-E和Midjourney)不允许用户下载权重,“使得评估这些模型的偏见和局限性在公正客观的方式下变得具有挑战性。”他们进一步声称,这些模型的封闭性“阻碍了可重复性,扼杀了创新,并防止社区在这些模型基础上进行进一步的科学和艺术进步。”
这种理想主义可能对那些感到被威胁的艺术家来说并没有多大的安慰,因为技术利用艺术家的作品碎片来训练像SDXL这样的模型,而未经允许,这不会解决版权诉讼的问题。但即便如此,尽管图像合成技术存在道德问题,它仍在朝着前方不断发展,这正是Stable Diffusion爱好者所希望的。

![青蛙过河 [递推法]](https://img-blog.csdnimg.cn/75b5aaf45dbf43bcbdbd50ad5f73b028.bmp)